
新智元报道
作者:童湛
编辑:QQ
本文将介绍南大、腾讯和上海人工智能实验室被 NeurIPS 2022 收录的工作。

论文链接:https://arxiv.org/abs/2203.12602
代码和预训练权重已经在 Github 开源:https://github.com/MCG-NJU/VideoMAE
目录
1. 背景介绍
2. 研究动机
3. 方法介绍
4. VideoMAE 实现细节
5. 消融实验
6. VideoMAE 的重要特性
7. 主要结果
8. 对社区的影响
9. 总结
背景介绍
视频自监督学习 (Video Self-supervised Learning) :不利用标签信息,通过设计自监督的代理任务,从视频数据中学习时空表征信息。现有的视频自监督预训练算法主要分为两大类: (1) 基于对比学习的自监督方法,如 CoCLR,CVRL 等。(2 )基于时序相关代理任务的自监督方法,如 DPC,SpeedNet,Pace 等。
动作识别 (Action Recognition) : 对给定剪裁过视频(Trimmed Video)进行分类,识别这段视频中人物的动作。目前的主流方法有 2D-based (TSN,TSM,TDN 等) ,3D-based (I3D,SlowFast 等) 以及 Transformer-based (TimeSformer,ViViT,MViT,VideoSwin 等)。动作识别作为视频领域的基础任务,常常作为视频领域各种下游任务 (例如时序行为检测,时空动作检测) 的主干网络(Backbone),去提取整个视频级别或者视频片段级别的时空特征。
动作检测 (Action Detection) : 该任务不仅需要对视频进行动作分类,识别这段视频中人物的动作,还要在空间范围内用一个包围框(bounding box)标记出人物的空间位置。动作检测在电影视频分析,体育视频分析等场景下有广泛的应用场景。
研究动机
自从 2020 年底视觉自注意力模型(Vision Transformer)被提出后,Transformer 被广泛应用到了计算机视觉领域,并帮助改进了一系列计算机视觉任务的性能。
然而,Vision Transformer 需要利用大规模的带标签的数据集进行训练。最初,最原始的 ViT(Vanilla Vision Transformer)通过使用数亿张带标签的图像进行有监督形式的预训练才能获得良好的性能。目前的 Video Transformer 通常基于图像数据训练的 Vision Transformer 模型(如 TimeSformer,ViViT 等)并且依赖大规模图像数据的预训练模型(例如 ImageNet-1K,ImageNet-21K,JFT-300M 等)。TimeSformer,ViViT 均曾尝试在视频数据集中从头开始训练 Video Transformer 模型, 但是都不能取得令人满意的结果。因此,如何在不使用任何其他预训练模型或额外图像数据的情况下,直接在视频数据集上有效地训练 Video Transformer,特别是最原始的 ViT (Vanilla Vision Transformer),仍然是一个亟待解决的问题。需要注意的是,与图像数据集相比,现有的视频数据集的规模相对较小。例如,被广泛使用的 Kinectics-400 数据集只有 20 多万的训练样本,样本数量大约是 ImageNet-21K 数据集的1/50,JFT-300M 数据集的1/1500,存在好几个数量级的差距。同时,相比训练图像模型,训练视频模型的计算开销也大了很多。这进一步增加了在视频数据集上训练 Video Transformer 的难度。
最近,「掩码+重建」(masking-and-reconstruction)这种自监督训练范式在自然语言处理(BERT)和图像理解(BEiT,MAE) 中取得了成功。因此,我们尝试利用这种自监督范式在视频数据集上训练 Video Transformer,并且提出了一种基于掩码和重建 (masking-and-reconstruction)这种代理任务的视频自监督预训练算法 VideoMAE (Video Masked Autoencoder)。经过 VideoMAE 预训练的 ViT 模型能够在 Kinetics-400 和 Something-Something V2 这种较大的视频数据集,以及 UCF101 和 HMDB51 这种规模相对小的视频数据集上取得大幅优于其他方法的效果。
方法介绍
MAE 概述
MAE 采用一种非对称编码器-解码器架构来进行掩码和重建的自监督预训练任务。一张 224x224 分辨率的输入图像首先被分成大小为 16 ×16 的非重叠的视觉像素块(token)。每个像素块(token)会经过块嵌入(token embedding)的操作被转化为高维特征。MAE 采用较高的掩码比率 (75%) 随机遮盖掉一部分的像素块(token)。经过掩码操作后,将剩余的像素块送到编码器(encoder)中进行特征提取。紧接着,将编码器提取出来的特征块与另一部分预设的可学习的像素块(learnable token)进行拼接,构成和原始输入图像尺寸一样大的特征。最后,利用一个轻量级的解码器(decoder),基于这部分特征重建原始的图像(实际实验过程中,重建目标的是经过归一化的像素块(normalized token) 。
视频数据的特性
与图像数据相比,视频数据包含了更多的帧,也具有更加丰富的运动信息。本节会先分析一下视频数据的特性。

对视频数据不同掩码策略的示例
时序冗余性
视频数据中包含着密集的图像帧,这些图像帧包含的语义信息随时间变化得非常缓慢。由此可见,视频中密集连续的彩色图像帧是高度冗余的,如图所示。这种冗余性可能在实现 MAE 的过程中造成两个问题。首先,如果采用原始视频的密集帧率(例如 30 FPS)进行预训练,则训练效率会非常低。因为这种设置会使得网络更多地关注数据中的静态表象特征或者一些局部变化缓慢的运动特征。其次,视频中的时序冗余性会极大地稀释了视频中的运动特征。因此,这种情况会使得在正常掩码率(例如,50% 到 75%)下,重建被掩码的像素块的任务变得相对简单。这些问题会影响作为编码器的 Backbone 在预训练的过程中提取运动特征。
时序相关性
视频可以看作是由静态图片随着时间的演化生成的,因此视频帧之间也存在语义的对应关系。如果不针对性地设计掩码策略,这种时序相关性可能会增加重建过程中的「信息泄漏」的风险。具体来说,如图所示,如果使用全局随机掩码或随机掩码图像帧,网络可以利用视频中的时序相关性,通过「复制粘贴」相邻帧中时序对应位置的未被遮蔽的像素块来进行像素块重建。这种情况下一定程度上也能完成代理任务,但是可能会导致 VideoMAE 仅仅能学习到较低语义的时间对应关系特征,而不是高层抽象的语义信息,例如对视频内容的时空推理能力。为了缓解这种情况,需要设计一种新的掩码策略,使重建任务更加具挑战性,这样才能让网络更好地学习视频中的时空特征表示。
VideoMAE 方法介绍
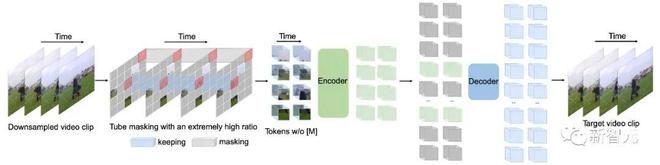
VideoMAE 的整体框架
为了解决前文中视频预训练过程中采用掩码和重建(masking-and-reconstruction)这种任务时可能遇到的问题,我们在 VideoMAE 中引入一些新的设计。
时序下采样
根据前文中对视频中密集连续帧中存在的时序冗余性的分析,因此在 VideoMAE 中选择采用带有时序间隔的采样策略来进行更加高效的视频自监督预训练。具体来说,首先从原始视频中随机采样一个由 $t$ 个连续帧组成的视频片段。然后使用带有时序间隔采样将视频片段压缩为帧,每个帧包含个像素。在具体的实验设置中,Kinetics-400 和 Something-Something V2 数据集上的采样间隔分别设置为 4 和2。
时空块嵌入
在输入到编码器中之前,对于采样得到的视频片段,采用时空联合的形式进行像素块嵌入。具体来说,将大小为视频片段中大小为的视觉像素视为一个视觉像素块。因此,采样得到的视频片段经过时空块嵌入(cube embedding)层后可以得到个视觉像素块。在这个过程中,同时会将视觉像素块的通道维度映射为。这种设计可以减少输入数据的时空维度大小,一定程度上也有助于缓解视频数据的时空冗余性。
带有极高的掩码比率的管道式掩码策略
为了解决由视频数据中的时序冗余性和时序相关性导致的「信息泄漏」问题,本方法选择在自监督预训练的过程中采用管道式掩码策略。管道式的掩码策略可以将单帧彩色图像的掩码方式自然地在整个视频的时序上进行拓展,即不同的帧中相同空间位置的视觉像素块将被遮蔽。具体来说,管道式掩码策略可以表示为 。不同的时间t共享相同的值。使用这种掩码策略,相同空间位置的 token 将总是会被掩码。所以对于一些视觉像素块(例如,不同掩码策略的示例图第 4 行的包含手指的像素块),网络将无法在其他帧中找到其对应的部分。这种设计这有助于减轻重建过程中出现「信息泄露」的风险,可以让 VideoMAE 通过提取原始视频片段中的高层语义信息,来重建被掩码的 token。
相对于图像数据,视频数据具有更强的冗余性,视频数据的信息密度远低于图像。这种特性使得 VideoMAE 使用极高的掩码率(例如 90% 到 95%)进行预训练。值得注意的是,MAE 的默认掩码率为 75% 。实验结果表明,使用极高的掩码率不仅能够加速预训练(仅有 5% 到 10% 的视觉像素块被输入到编码器中),同时能够提升模型的表征能力和在下游任务中的效果。
时空联合自注意力机制
前文中提到了 VideoMAE 采用了极高的掩码率,只保留了极少的 token 作为编码器的输入。为了更好地提取这部分未被遮蔽的 token 的时空特征,VideoMAE 选择使用原始的 ViT 作为 Backbone,同时在注意力层中采用时空联合自注意力(即不改变原始 ViT 的模型结构)。因此所有未被遮蔽的 token 都可以在自注意层中相互交互。时空联合自注意力机制的级别的计算复杂度是网络的计算瓶颈,而前文中针对 VideoMAE 使用了极高掩码比率策略,仅将未被遮蔽的 token(例如 10%)输入到编码器中。这种设计一定程度上可以有效地缓级别的计算复杂度的问题。
VideoMAE 实现细节
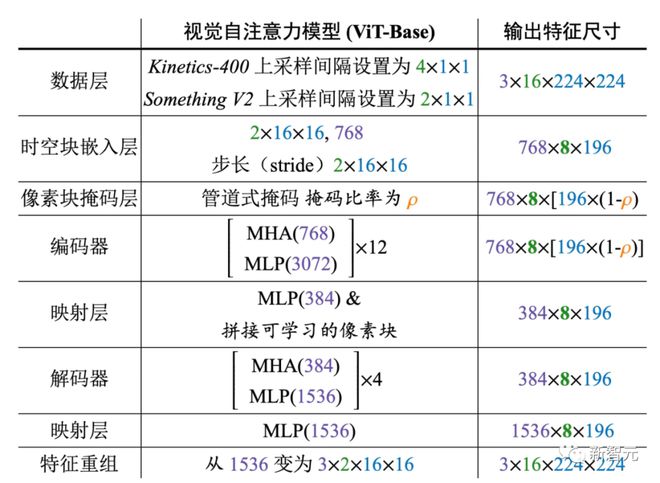
VideoMAE 框架的具体设计细节
上图展示了 VideoMAE 采用的编码器和解码器的具体架构设计(以 ViT-B 为例)。我们在下游的四个视频动作识别数据集和一个动作检测数据集上对 VideoMAE 进行评估。这些数据集关注视频中不同方面的运动信息。Kinetics-400 是一个大规模的 YouTube 视频数据集,包含了大约 30 万个剪裁过的视频片段,涵盖了 400 个不同的动作类别。Kinetics-400 数据集主要包含日常生活中的活动,并且某些类别与交互对象或场景信息高度相关。Something-Something V2 数据集中的视频主要包含了不同对象执行相同动作,因此该数据集中的动作识别更加关注运动属性而不是对象或场景信息。其中训练集大约包含 17 万个视频片段,验证集大约包含 2.5 万个视频片段。UCF101 和 HMDB51 是两个相对较小的视频动作识别数据集。UCF101 的训练集大约包含 9500 个视频,HMDB51 的训练集大约包含 3500 个视频。实验过程中,我们首先在训练集上使用 VideoMAE 对网络进行自监督预训练,紧接在训练集上对编码器(ViT)进行有监督形式的微调,最后在验证集上对模型的性能进行评估。对于动作检测数据集 AVA,我们首先会加载 Kinetics-400 数据集上训练好的模型,对编码器(ViT)进行有监督形式的微调。
消融实验
本节在 Something-Something V2 和 Kinetics-400 数据集上对 VideoMAE 进行消融实验。消融实验默认采用输入为 16 帧的原始的 ViT 模型。同时在微调后进行评估时,在 Something-Something V2 上选择 2 个视频片段和 3 次裁剪进行测试,在 Kinetics-400 上选择 5 个视频片段和 3 次裁剪进行测试。
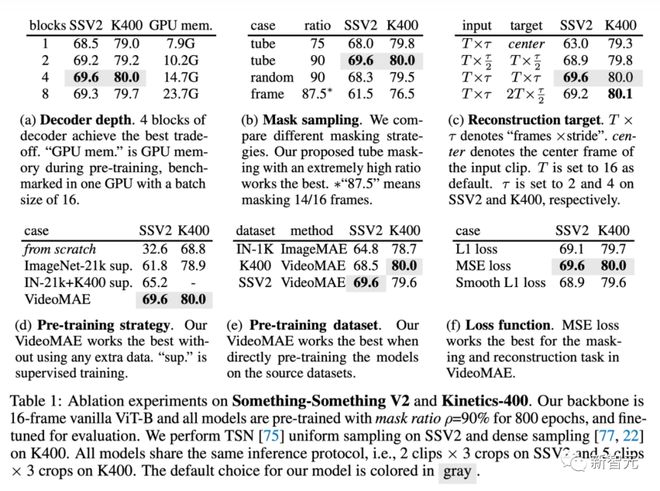
解码器设计
轻量级解码器是 Vid e oMAE 中的一个关键组件。表(a) 中展示了使用不同深度的解码器的实验结果。与 MAE 不同,VideoMAE 中更深的解码器可以取得更好的性能,而深度较浅的解码器可以有效地降低 GPU 的显存占用。认情况下解码器的层数设置为 4。遵循 MAE 的经验性设计,VideoMAE 中解码器的通道宽度设置为编码器的通道宽度的一半(例如,以 ViT-B 作为编码器时,解码器的通道宽度设置为 384)。
掩码策略
在使用 75% 的掩码比例下,将不同的掩码策略与管道式掩码策略进行比较。如表(b)所示,全局随机掩码和随机掩码图像帧的性能劣于管道式掩码策略。这可能是由于管道式掩码策略可以一定程度上缓解了视频数据中的时序冗余性和时序相关性。如果将掩码比率增加到 90% ,VideoMAE 的在 Something-Something 上的性能可以进一步从 68.0% 提升到 69.6%。VideoMAE 中掩码策略和的掩码比率的设计可以使遮蔽加重建成为更具有挑战性的代理任务,强制模型学习到更加高层的时空特征。
重建目标
这里比较了 VideoMAE 中的重建目标,结果在表(c)中。首先,如果只使用视频片段中的中心帧作为重建目标,VideoMAE 在下游任务中的性能会大大降低。同时,VideoMAE 对采样间隔也很敏感。如果选择重建更密集帧的视频片段,其结果会明显低于默认的经过时序下采样的视频片段。最后还尝试从经过时序下采样的视频片段中重建视频片段中更加密集的帧,但这种设置会需要解码更多的帧,使得训练速度变慢,效果也没有很好。
预训练策略
这里比较了 VideoMAE 中的预训练策略,结果展示在表(d)中。与之前方法(TimeSformer,ViViT)的实验结论类似,在 Something-Something V2 这个对运动信息更加敏感的数据集上从头开始训练 ViT 并不能取得令人满意的结果。如果利用大规模图像数据集(ImageNet-21K)上预训练的 ViT 模型作为初始化,能够获得更好的准确度,可以从 32.6% 提升到 61.8% 。而使用在 ImageNet-21K 和 Kinetics-400 上预训练的模型进一步将准确率提高到 65.2%。而利用 VideoMAE 从视频数据集本身预训练得到的 ViT,在不使用任何额外的数据的条件下,最终能达到 69.6% 的最佳性能。Kinetics-400 上也有相似的结论。
预训练数据集
这里比较了 VideoMAE 中的预训练数据集,结果展示在表(e)中。首先按照 MAE 的设置,在 ImageNet-1K 上对 ViT 自监督预训练 1600 epoch。然后利用 I3D 中的策略,将 2D 块嵌入层膨胀为 3D 时空块嵌入层,并在视频数据集上微调模型。这种训练范式可以超过从头有监督训练的模型。紧接着,将 MAE 预训练的模型与在 Kinetics-400 上 VideoMAE 预训练的 ViT 模型的性能进行了比较。可以发现 VideoMAE 可以实现比 MAE 更好的性能。然而这两种预训练模型均未能取得比仅在 Something-Something V2 数据集上进行自监督预训练的 VideoMAE 更好的性能。由此可以分析,预训练数据集和目标数据集之间的领域差异可能是一个重要问题。
预训练轮次
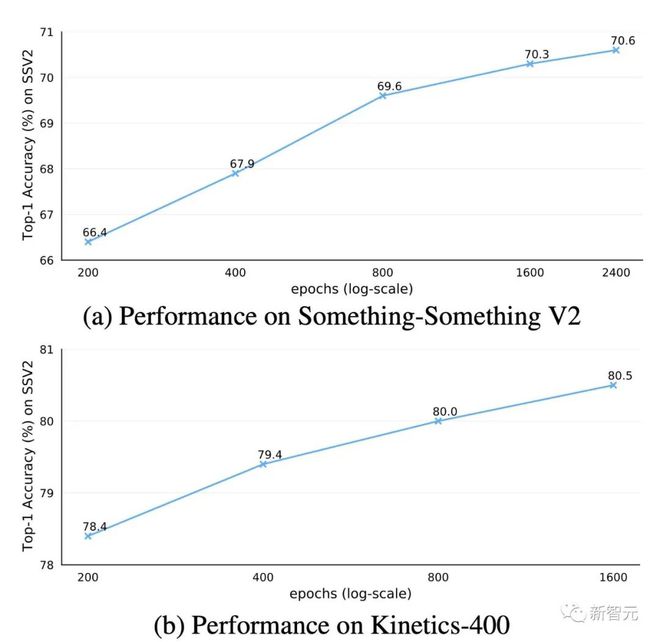
预训练的总轮次在 VideoMAE 中的影响
在消融实验中,VideoMAE 预训练的总轮次默认设置为 800。我们尝试在 Kinetics-400 和 Something-Something V2 数据集上对预训练轮次进行深入探究。根据图中的结果,采用更长的预训练轮次在两个数据集上都可以带来持续的增益。
VideoMAE 的重要特性
VideoMAE 是一种数据高效的学习器
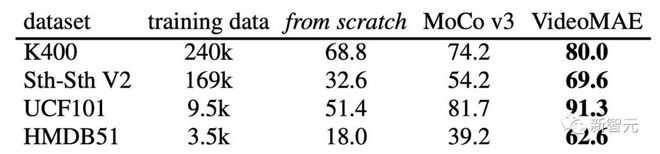
VideoMAE 与 MoCov3 在下游不同视频动作识别数据集上的性能比较
先前很多工作对视频自监督预训练进行了广泛的研究,但这些方法主要使用卷积神经网络作为 Backbone,很少有方法去研究中基于 ViT 的训练机制。因此,为了验证基于 ViT 的 VideoMAE 对视频自监督预训练的有效性,我们对两种基于 ViT 的训练方法进行了比较:(1) 从头开始有监督训练模型,(2) 使用对比学习方法 (MoCo v3) 进行自监督预训练。根据实验结果,可以发现 VideoMAE 明显优于其他两种训练方法。例如,在数据规模最大的 Kinetics-400 数据集上,VideoMAE 比从头开始训练的准确率高出大约 10%,比 MoCo v3 预训练的结果高出大约6%。VideoMAE 卓越的性能表明,掩码和重建(masking-and-reconstruction)这种自监督范式为 ViT 提供了一种高效
的预训练机制。与此同时值得注意的是,随着训练集的变小,VideoMAE 与其他两种训练方法之间的性能差距变得越来越大。值得注意的是,即使 HMDB51 数据集中只包含大约 3500 个视频片段,基于 VideoMAE 的预训练模型仍然可以获得令人非常满意的准确率。这一新的结果表明 VideoMAE 是一种数据高效的学习器。这与对比学习需要大量数据进行预训练的情况不同。VideoMAE 的数据高效的特性在视频数据有限的场景下显得尤为重要。

VideoMAE 与 MoCov3 在 Something-SomethingV2 数据集上的效率分析
我们还进一步比较了使用 VideoMAE 进行预训练和使用 MoCo v3 预训练的计算效率。由于使用掩码加重建这种极具挑战性的代理任务,每次迭代过程网络只能观察到 10% 的输入数据(90% 的 token 被遮蔽),因此 VideoMAE 需要更多的训练轮次数。极高比例的 token 被遮蔽这种设计大大节约了预训练的计算消耗和时间。VideoMAE 预训练 800 轮次仅仅需要 19.5 小时,而 MoCo v3 预训练 300 轮次就需要 61.7 小时。
极高的掩码率
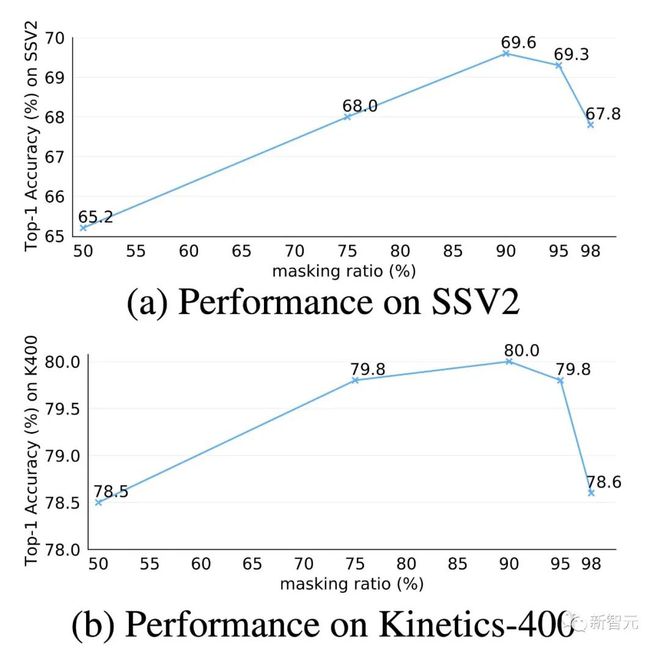
掩码比率在 VideoMAE 中的影响
极高的掩码率是 VideoMAE 中的核心设计之一。我们在 Kinetics-400 和 Something-Something V2 数据集上对此设计进行了深入探究。根据图中的结果,当掩码比率非常高时,即使是 95% 时,网络在下游视频动作识别任务的这两个重要数据集上仍然能表现出极佳的性能。这个现象与自然语言处理中的 BERT 和图像的 MAE 中的存在巨大的不同。视频数据中存在时序冗余性和时序相关性,使得 VideoMAE 相比于图像数据和自然语言,能够进行极高的掩码比率的操作。

我们还对经过预训练的 VideoMAE 的重构示例进行了可视化。从图中可以发现,即使在极高的掩码率下,VideoMAE 也可以产生令人满意的重建结果。这意味着 VideoMAE 能够学习和提取出视频中的时空特征。
泛化和迁移能力:数据的质量与数量

VideoMAE 与 MoCov3 在较小数据集上的特征迁移能力的性能比较
为了进一步研究 VideoMAE 学习到的特征,本节对经过预训练的 VideoMAE 的泛化和迁移能力进行了评估。上表中展示了在 Kinetics-400 数据集上进行预训练的 VideoMAE 迁移到 Something-Something V2、UCF101 和 HMDB51 数据集上的效果。同时,表中也展示了使用 MoCo v3 进行预训练的模型的迁移能力。根据表中的结果,利用 VideoMAE 进行预训练的模型的迁移和泛化能力优于基于 MoCo v3 进行预训练的模型。这表明 VideoMAE 能够学习到更多可迁移的特征表示。在 Kinetics-400 数据集上进行预训练的 VideoMAE 比直接在 UCF101 和 HMDB51 数据集上直接进行预训练的 VideoMAE 效果好。但是在 Kinetics-400 数据集上进行预训练的模型在 Something-Something V2 数据集上的迁移能力较差。
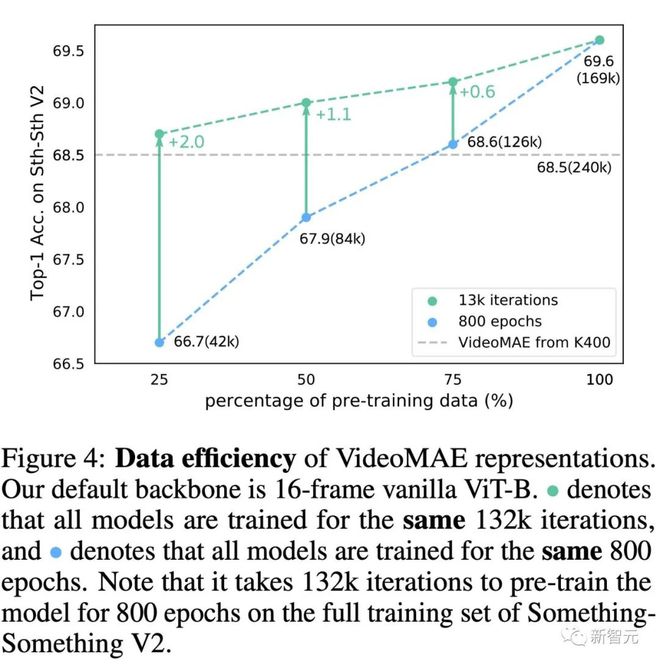
为了进一步探究造成这种不一致现象的原因,我们在 Something-Something V2 数据集上进行了减少预训练视频数量的实验。探究过程的包含了两个实验:(1)使用相同的训练轮次数(epoch) 进行预训练,(2)使用相同的迭代次数(iteration)进行预训练。从图中的结果可以发现,当减小预训练样本数时,采用更多的训练迭代也能够提升模型的性能。即使只使用了 4 万 2 千的预训练视频,直接在 Something-Something V2 数据集上训练的 VideoMAE 仍然可以取得比利用 24 万视频数据的 Kinetics-400 数据集进行预训练更好的准确率(68.7% 对比 68.5%)。这个发现意味着领域差异是视频自监督预训练过程中需要注意的另一个重要因素,当预训练数据集和目标数据集之间存在领域差异时,预训练数据的质量比数据的数量更重要。同时,这个发现也间接验证了 VideoMAE 是一种针对视频自监督预训练的数据高效的学习器。
主要结果
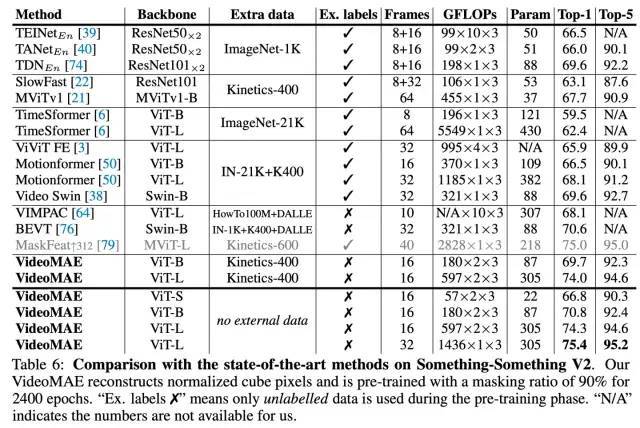
Something-Something V2 数据集实验结果
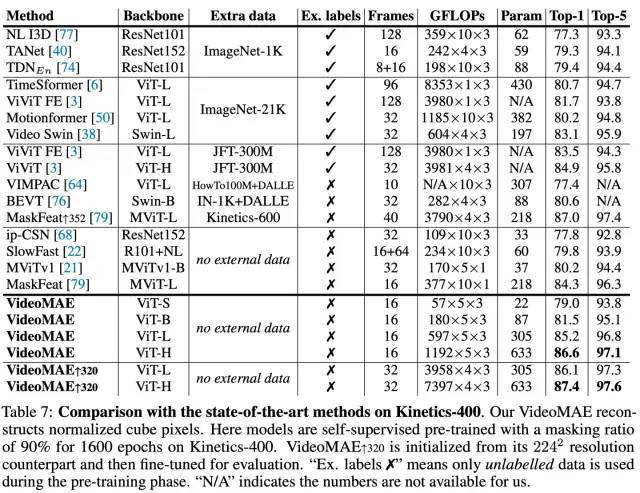
Kinetics-400 数据集实验结果
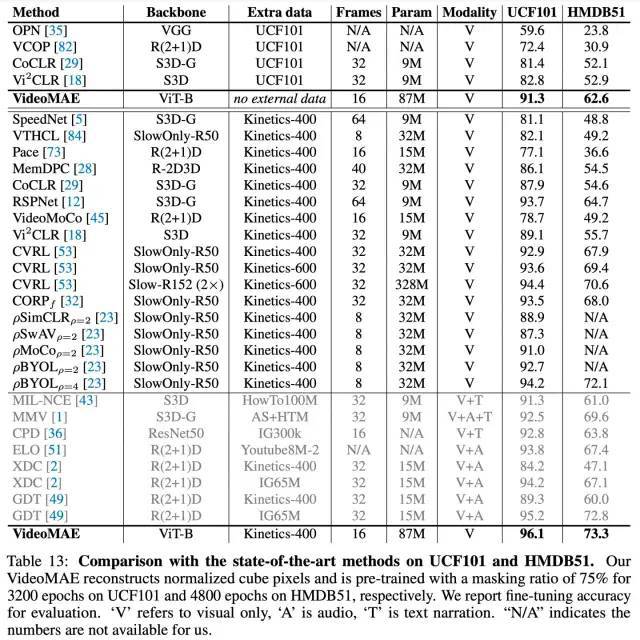
UCF101 和 HMDB51 数据集实验结果
在无需使用任何额外数据的条件下,VideoMAE 在 Something-Something V2 和 Kinetics-400 上的 Top-1 准确率分别达到 75.4% 和 87.4%。需要注意的是,Something-Something V2 数据集上目前最佳的方法都强烈依赖于在外部数据集上进行预训练的模型进行初始化。相反,VideoMAE 在没有利用任何外部数据的条件下能够显着优于之前的最佳方法的准确率约 5%。VideoMAE 在 Kinetics-400 数据集上也能取得非常卓越的性能。在视频数据有限的情况下(例如,UCF101 数据集中仅包含不到 1 万个训练视频, HMDB51 中仅包含约 3500 个训练视频),VideoMAE 不需要利用任何额外的图像和视频数据,也能够在这些小规模视频数据集上远远超过之前的最佳方法。
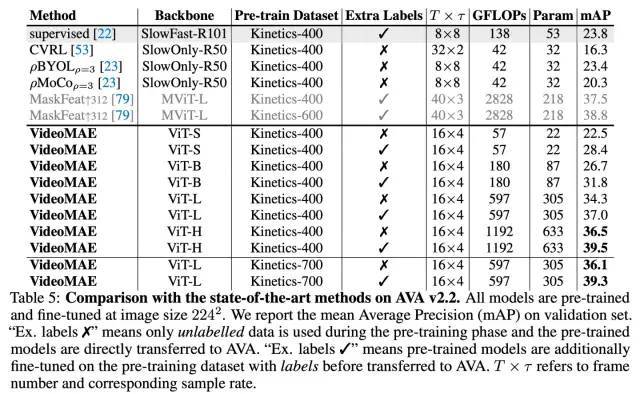
AVA v2.2 数据集实验结果
除了传统的动作分类任务,我们还进一步在视频动作检测这种更精细的理解任务上验证 VideoMAE 模型的表征能力。我们选取了 AVA v2.2 数据集进行实验。实验中,首先会加载 Kinetics-400 数据集上预训练好的模型,再对 ViT 进行有监督形式的微调。由表格可以发现,经过 VideoMAE 预训练的 ViT 模型可以在 AVA v2.2 数据集上取得非常好的结果。如果将自监督预训练后的 ViT 模型,在 Kinetics-400 上进行进一步的有监督的微调,可以在动作检测任务上去得更好的表现(3 mAP-6mAP 的提升)。这也说明了对 VideoMAE 自监督预训练后的模型,在上游数据集进行有监督的微调后再迁移到下游任务中,模型的性能可以进一步提升。
对社区的影响
我们于今年 4 月对 VideoMAE 的模型和代码进行了开源,收到了社区的持续关注和认可。

根据 Paper with Code 榜单,VideoMAE 已经分别占据 Something-Something V2[1]和 AVA 2.2[2]榜单首位长达半年时间(2022 年 3 月底至今)。如果不利用任何外部数据,VideoMAE 在 Kinetics-400[3],UCF101[4],和 HMDB51[5]数据集上的结果也是迄今为止最好的。
https://huggingface.co/docs/transformers/main/en/model_doc/videomae
几个月前,VideoMAE 的模型被 Hugging Face 的 Transformers 官方仓库收录,是该仓库收录的第一个视频理解模型!一定程度上也反应了社区对我们工作的认可!希望我们的工作能为基于 Transformer 的视频预训练提供一个简单高效的基线方法,同时也能为后续基于 Transformer 的视频理解方法带来启发。
https://github.com/open-mmlab/mmaction2/tree/dev-1.x/configs/recognition/videomae
目前视频理解仓库 MMAction2 也支持了对 VideoMAE 模型的推理。
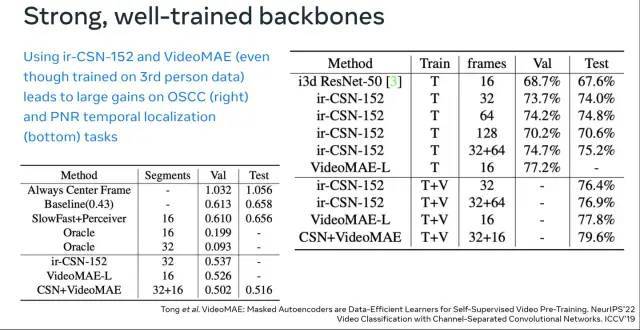

在刚刚结束的 ECCV 2022 2nd International Ego4D Workshop 上,VideoMAE 已经迅速成为了帮助大家打比赛的利器。上海人工智能实验室在本届 Ego4D Challenge 中的多个子赛道取得了冠军 。其中,VideoMAE 作为重要的 Backbone,为他们的解决方案提供了强大的视频特征。值得注意的一点是,从上面第一张图中可以发现,仅仅在 Kinetics-400 上进行预训练的 VideoMAE(ViT-L)的效果已经可以超越在 IG-65M 视频数据集(约为 Kinetics-400 样本数据的 300 倍)上预训练的 ir-CSN-152。这也进一步验证了 VideoMAE 预训练模型的强大表征能力。
总结
我们这个工作的主要贡献包含以下三个方面:
· 我们第一个提出了基于 ViT 的掩码和重建的视频自监督预训练框架 VideoMAE。即使在较小规模的视频数据集上进行自监督预训练,VideoMAE 仍能取得非常优异的表现。为了解决由时序冗余性 (temporal redundancy) 和时序相关性(temporal correlation) 导致的「信息泄漏」问题,我们提出了带有极高掩码率的管道式掩码(tube masking with an extremely high ratio)。实验表明,这种设计是 VideoMAE 最终能够取得 SOTA 效果的关键。同时,由于 VideoMAE 的非对称编码器-解码器架构,大大降低了预训练过程的计算消耗,极大得节省了预训练过程的时间。
· VideoMAE 将 NLP 和图像领域中的经验成功在视频理解领域进行了自然但有价值的推广,验证了简单的基于掩码和重建的代理任务可以为视频自监督预训练提供一种简单但又非常有效的解决方案。使用 VideoMAE 进行自监督预训练后的 ViT 模型,在视频理解领域的下游任务(如动作识别,动作检测)上的性能明显优于从头训练(train from scratch)或对比学习方法(contrastive learning) 。
· 实验过程中还有两处有意思的发现,可能被之前 NLP 和图像理解中的研究工作忽视了: (1) VideoMAE 是一种数据高效的学习器。即使在只有 3 千个左右的视频数据集 HMDB51 上,VideoMAE 也能够完成自监督预训练,并且在下游分类任务上可以取得远超过其他方法的结果。(2) 对于视频自监督预训练,当预训练数据集与下游任务数据集之间存在明显领域差异(domain gap)的时候,视频数据的质量可能比数量更加重要。
参考资料:
1. Action Recognition on Something-Something V2
https://paperswithcode.com/sota/action-recognition-in-videos-on-something?p=videomae-masked-autoencoders-are-data-1
2. Action Detection on AVA v2.2
https://paperswithcode.com/sota/action-recognition-on-ava-v2-2?p=videomae-masked-autoencoders-are-data-1
3. Action Classification on Kinetics-400
https://paperswithcode.com/sota/action-classification-on-kinetics-400?tag_filter=163
4. Self-Supervised Action Recognition on UCF101
https://paperswithcode.com/sota/self-supervised-action-recognition-on-ucf101?tag_filter=163
5. Self-Supervised Action Recognition on HMDB51
https://paperswithcode.com/sota/self-supervised-action-recognition-on-hmdb51?tag_filter=163






