萧箫发自凹非寺
量子位公众号 QbitAI
扩散模型的图像生成统治地位,终于要被 GAN 夺回了?
就在大伙儿喜迎新年之际,英伟达一群科学家悄悄给 StyleGAN 系列做了个升级,变出个 PLUS 版的 StyleGAN-T,一下子在网上火了。
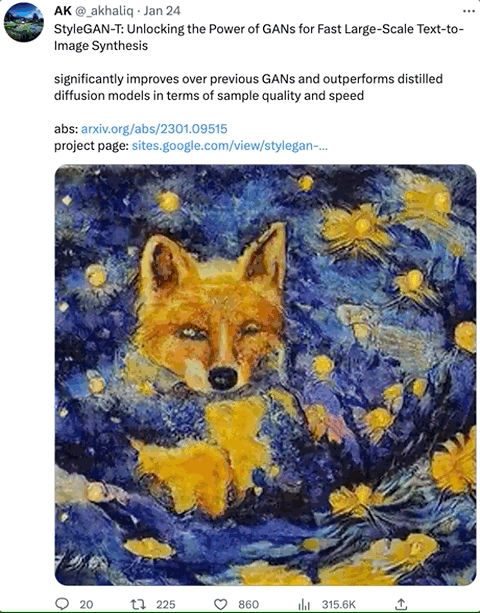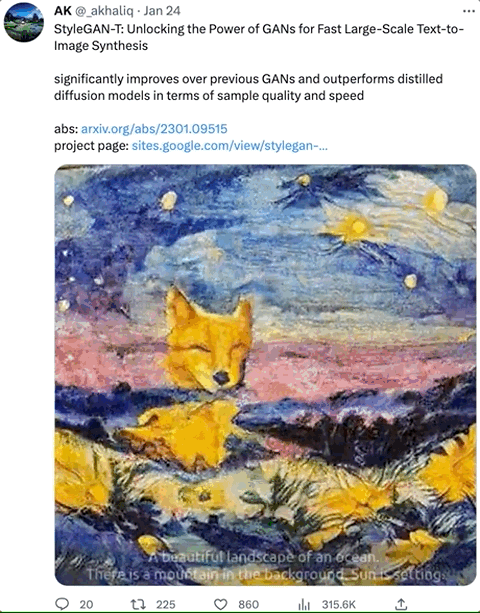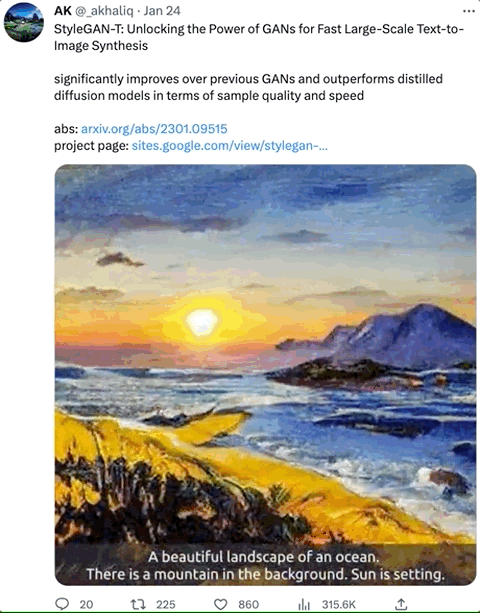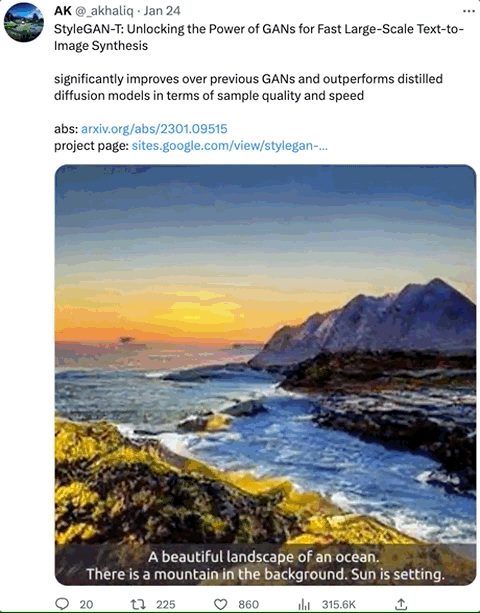
无论是在星云爆炸中生成一只柯基:

还是基于虚幻引擎风格渲染的森林:

都只需要接近 0.1 秒就能生成!
同等算力下,扩散模型中的 Stable Diffusion 生成一张图片需要3 秒钟,Imagen 甚至需要接近 10 秒。
不少网友的第一反应是:GAN,一个我太久没听到的名字了。

很快谷歌大脑研究科学家、DreamFusion 第一作者 Ben Poole 赶来围观,并将 StyleGAN-T 与扩散模型做了个对比:
在低质量图像(64×64)生成方面,StyleGAN-T 要比扩散模型做得更好。

但他同时也表示,在 256×256 图像生成上,还是扩散模型的天下。
所以,新版 StyleGAN 生成质量究竟如何,它又究竟是在哪些领域重新具备竞争力的?
StyleGAN-T 长啥样?
相比扩散模型和自回归模型多次迭代生成样本,GAN 最大的优势是速度。
因此,StyleGAN-T 这次也将重心放在了大规模文本图像合成上,即如何在短时间内由文本生成大量图像。
StyleGAN-T 基于 StyleGAN-XL 改进而来。
StyleGAN-XL 的参数量是 StyleGAN3 的 3 倍,基于 ImageNet 训练,能生成 1024×1024 高分辨率的图像,并借鉴了 StyleGAN2 和 StyleGAN3 的部分架构设计。
它的整体架构如下:
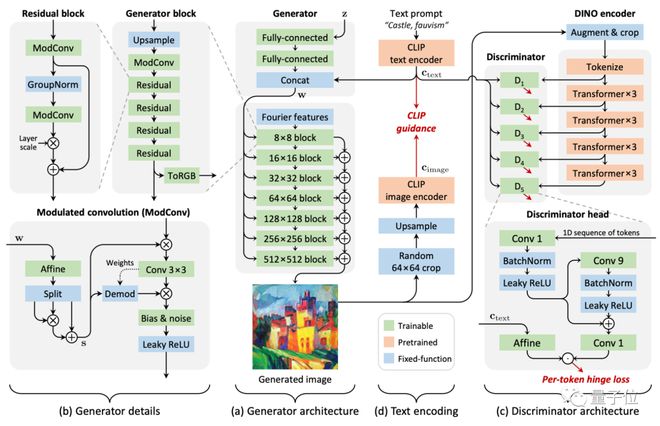
具体到细节上,作者们对生成器、判别器和文本对齐权衡机制进行了重新设计,用 FID 对样本质量进行量化评估,并采用 CLIP 来对文本进行对齐。
在生成器上,作者们放弃了 StyleGAN3 中能实现平移同变性(equivariance)的架构,转而采用了 StyleGAN2 的部分设计,包括输入空间噪声以及跳层连接等,以提升细节随机变化的多样性。
在判别器上,作者们也重新进行了设计,采用自监督学习对 ViT-S 进行训练。
随后,作者采用了一种特殊的截断(truncation)方法来控制图像生成的效果,同时权衡生成内容的多样性。
只需要控制参数ψ,就能在确保 CLIP 分数(用于评估图像生成效果)变动不大的情况下,改善生成图像的风格多样性。

随后,作者们用 64 个英伟达 A100 训练了 4 周,最终得到了这版 StyleGAN-T。
那么它的生成效果如何呢?
超快生成低分辨率图像
作者们对当前最好的几种 GAN、扩散模型和自回归模型进行了评估。
在微软的 MS COCO 数据集上,StyleGAN-T 实现了 64×64 分辨率下最高的 FID。
(其中,FID 是计算真实图像和生成图像特征向量距离的评估用值,数值越低,表示生成的效果越接近真实图像)
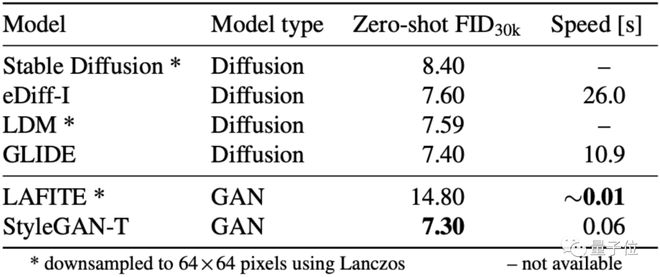
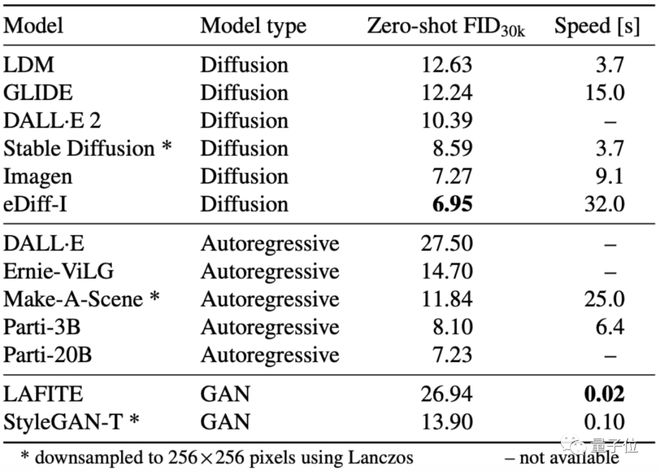
但在更高的 256×256 分辨率生成上,StyleGAN-T 还是没有比过扩散模型,只是在生成效果上比同样用 GAN 的 LAFITE 要好上不少:
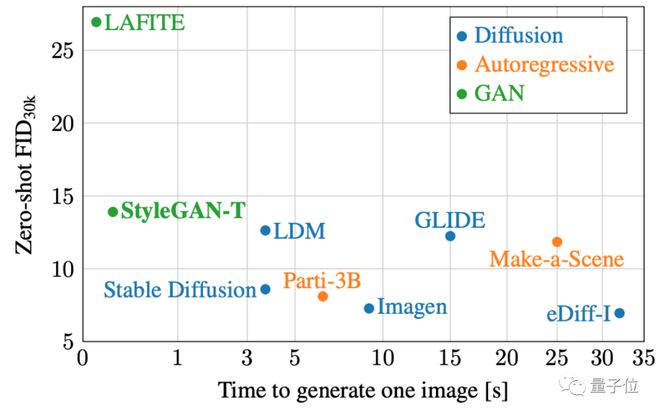
如果进一步将生成时间和 FID 分别作为纵轴和横轴,放到同一张图上来对比,还能更直观地对比生成质量和速度。
可见 StyleGAN-T 能保持在10FPS的速度下生成 256×256 分辨率图像,同时 FID 值逼近 LDM 和 GLIDE 等扩散模型:
而在文本生成图像功能上,作者们也从文本特征、风格控制等方面对模型进行了测试。
在增加或改变特定的形容词后,生成的图像确实符合描述:

即便是快速生成的图像,也能迅速控制风格,如“梵高风格的画”or“动画”等:

当然,偶尔也有失败案例,最典型的就是生成带字母要求的图像时,显示不出正常字母来:

作者们正在努力整理代码,表示不久之后就会开源。

作者介绍
作者们均来自图宾根大学和英伟达。

一作 Axel Sauer,图宾根大学博士生,此前在卡尔斯鲁厄理工学院(KIT)获得本硕学位。目前感兴趣的研究方向是深度生成模型、神经网络架构和实证研究。

二作 Tero Karras,英伟达杰出研究科学家,对英伟达 RTX 技术有重要贡献,也是 StyleGAN 系列的主要作者,主要研究方向是计算机图形学和实时渲染。

不过在这波 GAN 掀起的“文艺复兴”浪潮下,也出现了“StyleGAN 时代迎来终结”的声音。
有网友感慨:
在这之前,最新 StyleGAN 生成的图像总能让我们大吃一惊,然而现在它给我们的印象只剩下“快”了。

你认为 GAN 还能撼动扩散模型的统治地位吗?
论文地址:
https://arxiv.org/abs/2301.09515
项目地址:
https://github.com/autonomousvision/stylegan-t







