作者:吴淑明达摩院机器智能技术团队
当前手语内容覆盖有限,听障人士难以从影音内容中获取更多的信息,在交流场景下也面临着沟通障碍。如何才能提升听障人士在社会生活日常沟通中的效率?本文将为大家分享虚拟数字人「手语翻译官」的技术实现。
一、背景
1. 1 用户规模
世界银行的数据显示,全球大约有 11 亿残障人士,全球听障人士约有 7000 万+,中国残疾人总残疾人人数为 8500 万人左右,听障人士约 2780 万,占全国残疾人口的约 30%,每年新增 20 万;浙江有 90 万。全国范围内手语老师数量不足, 专业的手语老师就更是少之又少。
1. 2 聋人生活中的困境
-
与健听人的简单交流,即便使用文字也不能顺畅交流,再加上部分年长受教育程度低的人群,文字交流也困难。
-
由于听障人群的受教育程度以及独特表达和理解方式,导致他们的文字表述和语法结构与健听人完全不同,即便通过文字也无法便捷无障碍的与健听人沟通。听障人群与健听人之间的沟通障碍,严重影响了听障人群的生活质量。听障人群与健听人的沟通需求主要集中在几下情况:
较复杂的交流,就医、纠纷、水电煤银网办事等具有一定专业性、复杂性的交流场景,需要有一个专业的手语翻译人员协助, 否则就是下面这句话:
晚上熬夜半夜早晨,他老换找位置舒服他妈妈多次断睡性帮他盖好被子别着凉,他有时翻中了我体位置得痛,看我醒酒冲来抱舒服能秒入睡了,哼!等中午他父母要补睡......
听人完全看不懂,这是在说什么?
深度交流:听障人士需要与听人进行深度的交流,通常是有一定专业性、复杂性的交流场景,如就医、水电煤银网办事等;
信息获取难度大:听障人士需要从听人世界的影音内容中获取更多的信息,而当前手语内容覆盖有限。
二、产品设计
2. 1 产品调研
2. 1.1 调研用户画像
听障人士:
1)听力受损程度在中重度及以上,在参与社会生活方面存在中度障碍,借助我们提供的产品,能有效提升其社会生活日常沟通效率;
2)会相对标准的手语,其通过手语所表达出的信息,在听障人群中,能被大多数听障人士看懂并理解;
3)至少具备普通智能手机使用能力。
听人:
1)与听障人士密切生活的非听障人群,与听障人士有较大的日常交流沟通诉求;
2)公共服务机构(政府、银行、医院、快递、商场等)的工作人员在日常工作中,可能会遇到要为听障人群提供服务的场景。
2. 1.2 痛点场景
简单交流:听障人士需要与听人进行简短的交流,对话轮次通常不超过 10 轮即可完成,内容为日常生活所需的交流场景,如日常购物、出行、问询、工作交办;
深度交流:听障人士需要与听人进行深度的交流,通常是有一定专业性、复杂性的交流场景,如就医、水电煤银网办事等;
信息获取:听障人士需要从听人世界的影音内容中获取更多的信息,而当前手语内容覆盖有限;
参加会议:听障人士需要从有声会议中获取会议信息,当前主要通过讯飞的语音识别技术转成文字;
2. 1.3 线下调研
场景一:A 开车途中遇停车时,接打视频电话。
停车期间,通过微信视频,和他人进行手语沟通。相比于常人,A 接打视频几乎是秒通,上午 3 小时的观察过程中,约有 20 次左右的视频接打。在车上主要通过车载手机支架固定手机。
分析:听障人士对手机视频通话的依赖较大,视频通话功能使用极为频繁。今天见到的几乎所有的听障朋友,均随身携带充电宝。
场景二:A 到达法院后,寻找联系对象。
A 没有去前台寻求帮助,径直走向电梯,出电梯后观察是否自己要去的地方,经历 1-4-3-2-1 多楼层寻找后,才到前台寻求帮助,打字告诉对方自己要找谁。
分析:和普通人沟通存在一定的障碍,导致听障人士非必要情况下,不会主动寻求常人协助,形成天然的鸿沟。
场景三:A 和法官沟通案件细节。
进入沟通室后,法官建议使用微信平台上的微法院进行图文沟通。但 A 坚持使用手之声 APP,在排队等待后,进入真人手语翻译视频通话。用手机支架将手机放置在桌面后,通过视频里的远程手语翻译,和法官完成了需要进行的沟通。A 先是表达了另一涉案人的近期信息,之后提出要求,在法官给出处理意见后,A 表示认可,并结束通话。适应了加入手语翻译的节奏后,对话过程的障碍相对较小。
分析:虽然能打字进行 IM 对话,但对 A 来说,还是认为远程手语翻译介入后的沟通效率更高。在环境简单不嘈杂,参与对话人数仅为 3 人(A、法官、远程手语翻译)的情况下,是可以进行沟通的。对 A 或是其他听障人士来说,使用手语翻译的效率,比起文字沟通要高很多。输入文字给对方看,适用于日常简短的沟通。如果是一个时间较长较正式的沟通,还是需要稳定的环境和手语翻译的帮助,才能顺利完成。
2. 1.4 双向手语翻译的难点
1)我们就是第一人
我们是“首个”以双向手语翻译为目标的项目,实现从 0 到 1 的过程。现阶段同类的手语合成产品,按照自然语言的语序采用逐字翻译,忽视了听障朋友的语言逻辑与健听人语言逻辑的差别,导致听障朋友理解困难。现阶段手语识别还未有成熟的商用产品,精度仍然是最大的挑战。
2)巧妇难为无米之炊
由于听障朋友对外交流有限,已有手语数据存留较少,且具备手语能力的人群数量较少,进一步减缓了数据沉淀的速度。与语音识别、语种互译相比,获取充足、高质量的手语数据难度不言而喻。
3)手语的区域特性
由于听障朋友的活动区域局限,形成大到地区、小到社区的多元化手语打法风格。这对于数据沉淀的覆盖范围,以及数据本身多样性对算法的挑战都十分巨大。
4)手语是视觉语言
手语是一门视觉语言,语言表达顺序与自然语言完全不同且没有固定语法约束。手语生成需要生成符合听障人群表达习惯,便于理解的语言;相当于学习了一门新的语言,而不是单纯的逐字翻译,例如:自然语言中“灭火”在手语中的表达是“火→灭”,因为先看到火才能灭。
5)纯视觉方案的手语识别
相对于现有基于昂贵传感器的手语识别,我们是首个采用纯视觉方案(仅依赖手机摄像头),需要实时精准的图像处理算法研发,从捕获的手语视频中提取有效的空时信息,进行手语识别。
这里涉及实时高效的处理高维度的视频数据,同时要处理手语本身的多元性、多样性表达。这对视觉算法提出了更高的要求。
手语语速快,动作精细和多变,动作间相似度高。
6)工程难度大
业务并发量大:与以往的工程架构不同(接口调用),现阶段提供流媒体服务,若高并发的时候需要大规模的集群和资源调度。
响应延时问题:流媒体本身就有几百毫秒的延时,再加上双向翻译的流程中嵌入了大量的算法模块,导致延时加长。延时翻译非常影响产品的交互体验。
2. 2 双向手语翻译
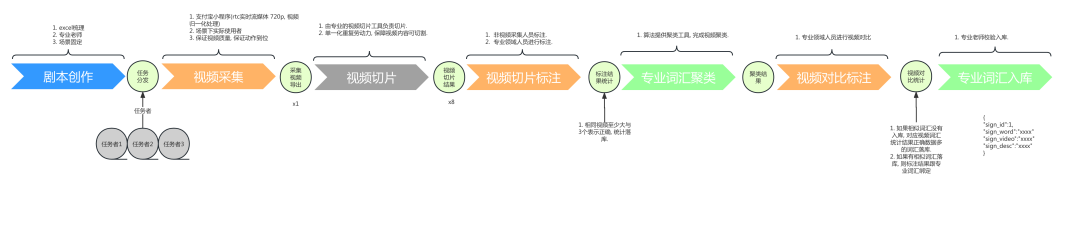
本文主要讲解技术实现,产品上仅仅放了实现后的一些产品使用。大家可以在支付宝上搜索《现声》体验。
产品链路:
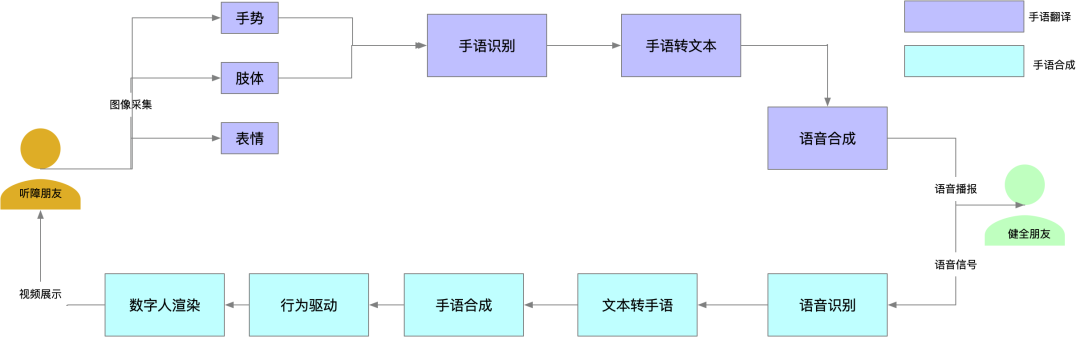
2. 3 手语合成
可以在数字人手语播报平台进行手语内容的生产:https://avatar.aliyun.com/#home
三、技术落地
依托云原生技术,池化数字人云渲染服务,实现数字人的不同业务模型下的快速服务,完成手语翻译单设备单工开发及手语合成实时翻译、文本转手语合成翻译、视频转手语合成翻译。
3. 1 技术方案设计
1)因为涉及实时图像识别,对于网络带宽的要求非常高,所以我们当前将视觉相关算法和流媒体部署在同一个 pod,从而降低网络开销及识别时延。
2)手语识别技术最大难度是“手语识别的图像数据来源,以及图像数据的标注团队”,技术上必须解决训练数据的生成效率问题。
3)由于听障和听人信息交互方式存在差异,听障朋友给出的是物理世界能形容的事物,整句话是由一堆动/名词组成,还会涉及到倒装,所以必须加一个手语词汇转自然文本的翻译模块。
4)相同与第 3 点,手语合成也需要一个文本转手语模块,将自然文本转换成手语词汇,同时面临第 2 点一样的数据问题。
-
专有名词解释
-
媒体服务:流媒体模块,负责编 &解码,rtc 渠道的订阅和推送,本地视频转码录制,解码后图片推送。
-
手语识别:算法模块,按照协定的图片格式输入图片,输出一系列手语词汇。
-
手语转文本:算法模块,输入手语词汇,输出自然文本。
-
手语合成:算法模块,输入手语词汇,情绪及等级,输出手语 keypose 和 bs 数据。
-
文本转手语:算法模块,输入自然文本,输出手语词汇,并且传输给 BH 模块。
-
行为交互逻辑:工程模块,统一决策调用数字人交互逻辑。
-
agent:工程模块,负责各个 POD 容器之间的消息传输。
-
3D 渲染引擎:渲染模块,负责数字人实时渲染,生成数字人帧数据。
3. 2 方案落地
初期产品上希望实现单设备双工模式,确实也实现了一个单设备双工模式,但由于环境噪音依赖终端设备的降噪,手语摄像头安放位置等等因素,最终确定使用单设备单工模式。
3. 2.1 单设备单工模式-《现声》
-
解决 ASR 识别不准确问题, 可实时在线进行人工干预。
-
解决手语识别不准确的情况下进行人工干预。
-
单工模式下手语翻译官支持主动打断,这需要依赖行为交互逻辑模块的实现交互逻辑的处理。
实时手语识别链路技术方案

1)手语识别帧数据要求为 10FPS、360P。
2)端上通过 RTC 将帧数据推送上来。
3)media 在数字人没有启动的前提下,会自动向手语转手语词汇模块发送空白帧数据,空白帧数据为全 0 图片数据,算法不会产出任何结果。
4)数字人开始工作后,流媒体解码出第一帧时候,并且发送手语转手语词汇模块, 手语识别才开始工作,手语转手语词汇发送识别结束事件给行为树。
5)手语识别中间会实时返回识别结果,结果为累积数据,并且通过手语识别结果事件发送给行为树模块。
6)行为树模块将手语识别结果发送给手语词汇转自然文本模块。
7)手语词汇转自然文本模块会产生手语识别结束事件,并且进行本地 redis 缓存。
8)行为树决策引擎,等收到手语识别结束后,行为树向前端发送手语识别结束事件,默认回到数字人界面,等待播报内容。
9)如果需要进行语音播报,行为树会发送播报文案给媒体,并且发送文案给前端展示,流媒体合成 tts 后,插入到流媒体里面。
实时手语合成链路技术方案

-
实时手语合成算法处理方案
关于手语标注数据,可以参考《手语众包》这一章节。
算法核心会计算词汇动作与词汇动作之间的过渡帧,及词汇动作到空闲动作的过渡帧,这要求数据标注的时候,尽量标注出空间最接近于空闲动作的那一帧数据。
-
实时手语合成 unity 处理方案,通过实时渲染加媒体视频编码转 RTC 的方式实现。
行为树编排
核心目的:解决数字人交互过程中, 工程、算法、前端等各个模块对数字人行为变化及 C 端 GUI 交互反馈。抽象数字人行为节点,降低代码开发,通过编排的方式快速实现数字人业务落地。
例如:
用户切换成手语识别时, TTS 要主动打断。
用户呼叫时, 要等待 C 端用户订阅流成功后, 数字人才开始打招呼。
TTS 开始播报是, TTS 文案才显示在前端页面。
TTS 结束播报后, TTS 自动消失, 或者长期维持不变。
1)行为树提供大量的流程控制方法,使得状态之间的改变更加直观;
2)整个游戏 AI 使用树型结构,方便查看与编辑;
3)方便调试和代码编写;
4)最重要的:行为树方便制作编辑器,可以交由策划人员使用。
3. 2.2 手语合成
1)算法及协议复用单设备单工流程,修改行为树逻辑实现,仅实现行为树任务流程管理。
2)实时手语翻译、离线文本手语翻译及视频手语翻译保持同一套架构。
3)离线音视频手语合成,因为手语的速度与音频播报速度不一致,针对手语给出的时间消耗是不一样的,所以需要离线音视频手语合成专门做定制。
4)实时手语合成,由 BH 模块复用行为树实现,但是行为树的编排存在差异。
5)离线文本 &离线视频合成由 BH 模块实现定时任务实现。
6)离线音视频手语合成音视频用左对齐的方案实现。
7)离线合成整体的渲染流程与实时渲染保持一致。
8)表情驱动:
-
文本转手语输入文本,识别用户情感类型及情感强度。
-
词汇转手语输入用户情感类型和强度,从而输出数字人表情和动作。(表情和动作是事先标注和制作完成的。)
-
情感分 7 个类别和 3 个强度来进行表情驱动。
四、数据生产
1)数据对于手语来说是最核心组成部分。
-
数据的产出是特殊人群。
-
数据的定义和拆解无法靠听人解决。
2)3D 手语动作数据的采集方案、成本等都没有可参考的成功案例。
4. 1 3D 数据资产
4. 1.1 3D 资产静态生产流程
-
静态资产包含“原画”,“中之人 3D 超高精度模型 5000 万面”,“高/中/低灰模”,“蒙皮贴图”,“服装道具”,“头发”,“BS&骨骼绑定”,“蒙皮绑定”。静态资产做完之后,才能进入动捕阶段。
-
为了降低整体的生产成本, 我们打算使用手语老师作为中之人, 防止由于 3D 模型服装道具的变化,引入的动作资产的修改。
-
人物原型设计主要是人物原画的输出。
-
模型制作
-
蒙皮贴图
-
BS 面部绑定
-
keypose 绑定
-
衣服 &道具制作
4. 1.2 3D 动态资产制作
-
动捕设备确定,最终我们确定使用光学动捕。
-
手套,使用数据手套进行动捕。
-
动捕场地和供应商由我们指定。
-
动捕完成后由指定供应商进行精修。
-
动捕资产交付上线。
4. 2 手语众包
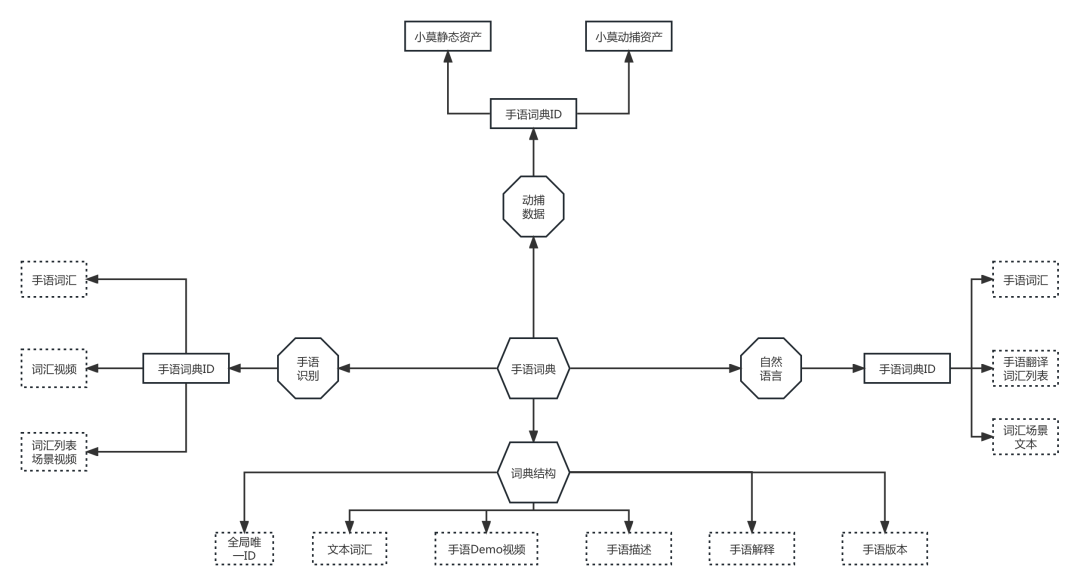
4. 2.1 手语词典
难点:如何组织一批无法沟通,特殊领域的群体,生产我们需要的数据。因此我们选择支付宝作为手语众包的载体。
4. 2.2 词汇定义
-
词根:指单一一个手语动作,最小手语颗粒度
-
融合词汇:由多个词根组成的手语词汇
-
专有名词:应用于特殊领域的专业词汇
-
敏感词:指不可以进行播报的词汇,比如涉黄、涉毒等等
-
一词多义:一个自然词汇有多种打法
-
相似打法:一种打法可以映射到多个自然词汇上
4. 2.3 词典组成
4. 2.4 数据标注