明敏发自凹非寺
量子位公众号 QbitAI
AI 画画通用模型,新增一员大将!
由阿里达摩院副院长周靖人等人打造的可控扩散模型 Composer,一经发布就小火了一把。

这个模型由 50 亿参数训练而来,和 Stable Diffusion 原理不同。它更进一步把训练图像拆解成了多个元素,然后基于这些元素训练扩散模型,让它们能够灵活组合。
由此一来,模型的创造能力就比仅基于图像大很多。如果有 100 张能拆分成 8 个元素的图像,那么就能生成一个数量为 100 的 8 次方的结果组合。

网友们看了纷纷表示,AI 画画发展速度也太快了!
团队表示,模型的训练和推理代码都在路上了。
有限手段的无限使用
该框架的核心思想是组合性(compositionality),模型名字就叫做 Composer。观察到现下很多 AI 画画模型,在细节的可控性上还没有做到很好,比如准确改变颜色、形状等。研究团队认为,想要实现图像的可控生成,不能依赖于对模型的调节,重点应该放在组合性上,这种方式可以将图像的创造力提升到指数级。
引用语言学大师诺姆·乔姆斯基的经典语录来解释模型,就是:有限手段的无限使用。具体来看,该模型就是将每个训练图像拆解成一系列基础元素,如蒙版图、草稿图、文字描述等,用它们来训练一个扩散模型。

然后让这些被拆分的元素,在推理阶段灵活组合,生成大量新的图像输出。

它可以支持多种形式作为输入。比如文字描述作为全局信息,深度图和草图作为局部引导,颜色直方图为低级细节等。
在保证生成图像可控的基础上,作为一个通用框架,该模型还能不用再训练就可以完成大量经典生成任务。
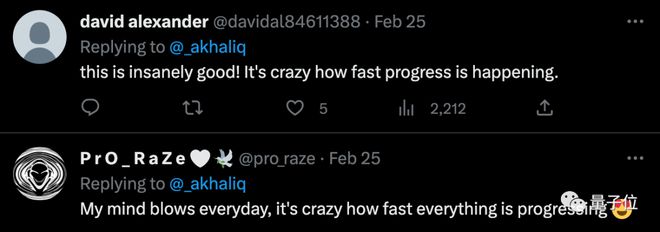
举例来看,图(a)中,最左边的是原图,后面 4 个是通过对 Composer 不同子集的表示进行调节而生成的新结果。
图(b)展示的是图像插值的结果。

图像重构的话是酱婶儿的,Composer 能够简单地改变图像表示来重新配置图像,比如草稿图和分割图。

还有对图像的特定部分进行编辑。
比如给蛋糕派换口味、把珍珠耳环少女的脸换成梵高、让兔子长一张熊猫脸等。

比较经典的图像生成任务也能挑战,而且无需再训练。

团队表示,现有成果还存在一定局限性,比如在单一条件输入的情况下,生成效果不是很好。以及输入不同语义的图像和文本嵌入时,生成结果会降低对文本嵌入的权重。
而针对 AI 画画模型都需要面对的风险问题,团队表示为避免被滥用,他们会在公开模型前先创建一个过滤版本。
达摩院副院长带队
该研究由阿里及蚂蚁团队完成。

通讯作者为周靖人。

他现任阿里达摩院副院长、阿里云智能 CTO,是 IEEE Fellow。
2004 年于哥伦比亚大学获得计算机博士学位,后加入微软担任研发合伙人。
2015 年,周靖人加入阿里巴巴集团,先后负责过达摩院智能计算实验室、大数据智能计算平台、搜索推荐事业部等。
论文一作Huang Lianghua同样来自达摩院,研究方向为扩大模型规模和数据来表示学习和内容生成。
论文地址:
https://arxiv.org/abs/2302.09778
GitHub 地址:






