新智元报道
作者:郑哲东
编辑:QQ
攻击是为了更好的防御。
这篇文章初版 2018 年 5 月就写好了,最近 2022 年 12 月才中。四年中得到了老板们的很多支持和理解。
(这段经历也希望给在投稿的同学们一点鼓舞,paper 写好肯定能中的,不要轻易放弃!)
arXiv 早期版本为:Query Attack via Opposite-Direction Feature:Towards Robust Image Retrieval

论文链接:https://link.springer.com/article/10.1007/s11263-022-01737-y
论文备份链接:https://zdzheng.xyz/files/IJCV_Retrieval_Robustness_CameraReady.pdf
代码:https://github.com/layumi/U_turn
作者:Zhedong Zheng, Liang Zheng, Yi Yang and Fei Wu
与早期版本相比,
-
我们在公式上做了一些调整;
-
加入了很多新的 related works 讨论;
-
加入了多尺度 Query 攻击 / 黑盒攻击 / 防御三个不同角度的实验;
-
加入 Food256,Market-1501,CUB,Oxford,Paris 等数据集上的新方法和较新的可视化方式。
-
攻击了 reid 中的 PCB 结构,攻击了 Cifar10 中的 WiderResNet。
实际案例
实际使用的话。举个例子,比如我们要攻击 google 或者百度的图像检索系统,搞大新闻(大雾)。我们可以下载一张狗的图像,通过 imagenet 模型(也可以是其他模型,最好是接近检索系统的模型)计算特征,通过把特征调头(本文的方法),来计算对抗噪声(adversarial noise)加回到狗上。再把攻击过后的狗使用以图搜图,可以看到百度谷歌的系统就不能返回狗相关的内容了。虽然我们人还能识别出这是狗的图像。
P.S. 我当时也试过攻击谷歌以图搜图,人还能识别出这是狗的图像,但谷歌往往会返回「马赛克」相关图像。我估计谷歌也不全是用深度特征,或者和 imagenet 模型有较大差异,导致攻击后,往往趋向于「马赛克」,而不是其他实体类别(飞机啊之类的)。当然马赛克也算某种程度的成功!
What
1. 本文的初衷其实特别简单,现有 reid 模型,或者风景检索模型已经达到了 95% 以上的 Recall-1 召回率,那么我们是不是可以设计一种方式来攻击检索模型?一方面探探 reid 模型的老底,一方面攻击是为了更好的防御,研究一下防御异常 case。
2. 检索模型与传统的分类模型的差异在于检索模型是用提取出来的特征来比较结果(排序),这与传统的分类模型有较大的差异,如下表。
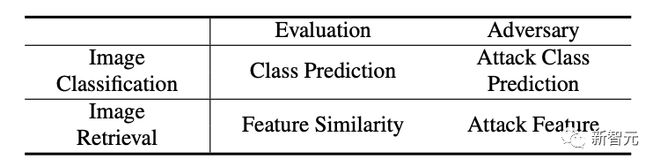
3. 检索问题还有一个特点就是 open set 也就是说测试的时候类别往往是训练时没见过的。如果大家熟悉 cub 数据集,在检索设置下,训练的时候训练集合 100 多种鸟,和测试时测试 100 多种鸟,这两个 100 种是没有 overlapp 种类的。纯靠提取的视觉特征来匹配和排序。所以一些分类攻击方法不适合攻击检索模型,因为攻击时基于类别预测的 graident 往往是不准的。
4. 检索模型在测试时,有两部分数据一部分是查询图像 query,一部分是图像库 gallery(数据量较大,而且一般不能 access)。考虑到实际可行性,我们方法将主要瞄准攻击 query 的图像来导致错误的检索结果。
How
1. 很自然的一个想法就是攻击特征。那么怎么攻击特征?基于我们之前对于 cross entropy loss 的观察,(可以参考 large-margin softmax loss 这篇文章)。往往我们使用分类 loss 的时候,特征f会存在一个放射形的分布。这是由于特征在学习的时候与最后一层分类层权重W计算的是 cos similarity。如下图,导致我们学完模型,同一类的样本会分布在该类W附近,这样f*W才能到达最大值。
2. 所以我们提出了一个特别简单的方法,就是让特征调头。如下图,其实有两种常见的分类攻击方法也可以一起可视化出来。如(a)这种就是把分类概率最大的类别给压下去(如 Fast Gradient),通过给-Wmax,所以有红色的梯度传播方向沿着反 Wmax;如(b)还有一种就是把最不可能的类别的特征给拉上来(如 Least-likely),所以红色的梯度沿着 Wmin。

3. 这两种分类攻击方法在传统分类问题上当然是很直接有效的。但由于检索问题中测试集都是没见过的类别(没见过的鸟种),所以自然f的分布没有那么紧密贴合 Wmax 或者 Wmin,因此我们的策略很简单,既然有了f,那我们直接把f往-f 去移动就好了,如图(c)。
这样在特征匹配阶段,原来排名高的结果,理想情况下,与-f 算 cos similarity,从接近 1 变到接近-1,反而会排到最低。
达成了我们攻击检索排序的效果。
4. 一个小 extension。在检索问题中,我们还常用 multi-scale 来做 query augmentation,所以我们也研究了一下怎么在这种情况下维持攻击效果。(主要难点在于 resize 操作可能把一些小却关键的抖动给 smooth 了。)
其实我们应对的方法也很简单,就如 model ensemble 一样,我们把多个尺度的 adversarial gradient 做个 ensemble 平均就好。
实验
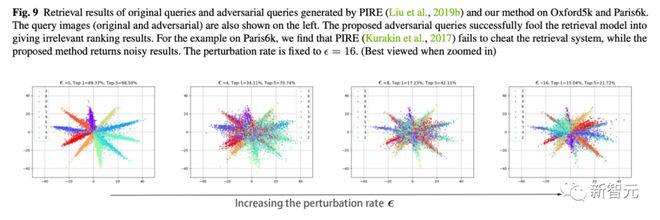
1. 在三个数据集三个指标下,我们固定了抖动幅度也就是横坐标的 epsilon,比较在同样抖动幅度下哪一种方法能使检索模型犯更多错。我们的方法是黄色线都处在最下面,也就是攻击效果更好。
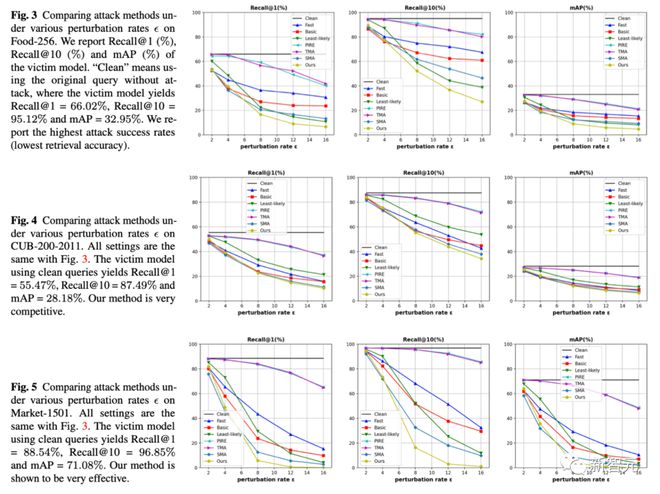
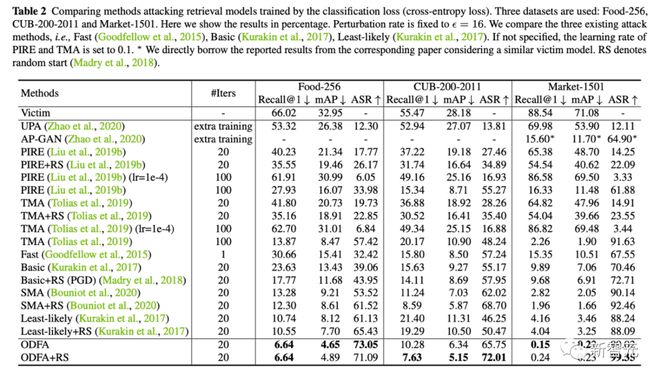
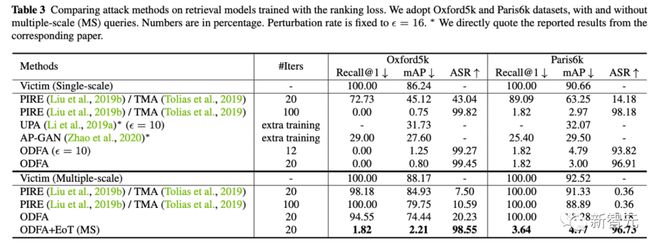
2. 同时我们也提供了在 5 个数据集上(Food,CUB,Market,Oxford,Paris)的定量实验结果
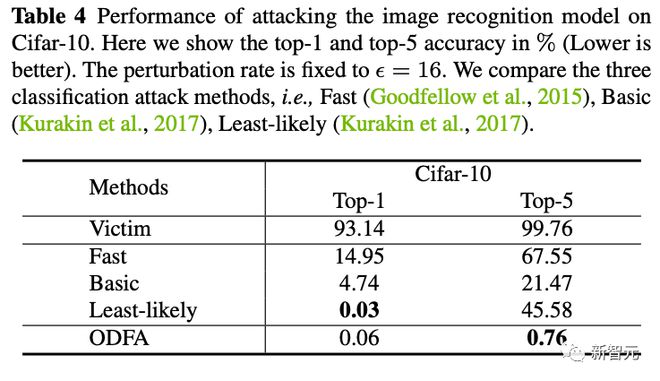
3. 为了展示模型的机制,我们也尝试攻击了 Cifar10 上的分类模型。
可以看到我们改变最后一层特征的策略,对于 top-5 也有很强的压制力。对于 top-1,由于没有拉一个候选类别上来,所以会比 least-likely 略低一些,但也差不多。
4. 黑盒攻击
我们也尝试了使用 ResNet50 生成的攻击样本去攻击一个黑盒的 DenseNet 模型(这个模型的参数我们是不可获取的)。发现也能取得比较好的迁移攻击能力。

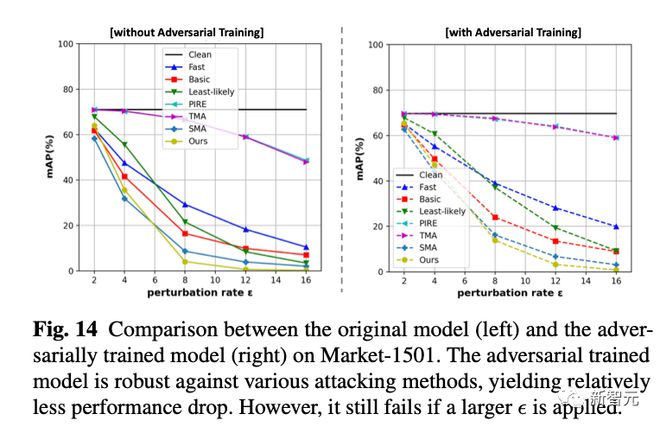
5. 对抗防御
我们采用 online adversarial training 的方式来训练一个防御模型。我们发现他在接受新的白盒攻击的时候依然是不行的,但是比完全没有防御的模型在小抖动上会更稳定一些(掉点少一些)。
6. 特征移动的可视化
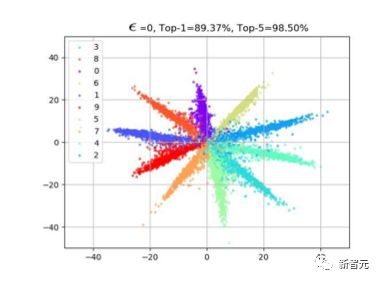
这也是我觉得最喜欢的一个实验。我们利用 Cifar10,把最后分类层的维度改为2,来 plot 分类层的 feature 的变化。
如下图,随着抖动幅度 epsilon 的变大,我们可以看到样本的特征慢慢「调头」了。比如大部分橙色的特征就移动到对面去了。