
新智元报道
作者:李朴恒
编辑:好困
宾夕法尼亚大学苏炜杰教授提出让作者提供投稿文章质量排序以改善会议同行评议质量的新方法,该方法于今年的 ICML 会议中投入实验。
近年来,以 ICLR、NeurIPS、ICML 等为代表的机器学习会议的文章投稿量呈指数级增长,投稿人数以及每人的投稿数量都在不断增加,部分高产作者甚至会在单个会议投稿三十余篇甚至四十余篇论文。
如今的会议通常采用同行评议制度,一篇投稿论文通常有 3 位左右的审稿人进行审稿,给出评分以及修改意见。
一篇论文往往有至少几个月甚至几年的研究周期,在同行评议的审稿制度下,必须要求审稿人在短时间内阅读大量文章并给出审稿意见,这一现象无疑是对于审稿质量的巨大冲击。

同行评议的制度意味着审稿人具有一言九鼎的话语权,这已成为被众多科学家所诟病的话题。
美国学 Adam Mastroianni 指出,同行评议这一起源于上世界 60 年代,长达 60 年的「科学实验」已经以失败告终。 他对此发表的文章 Things Could be Better 受到了广大学者的支持。
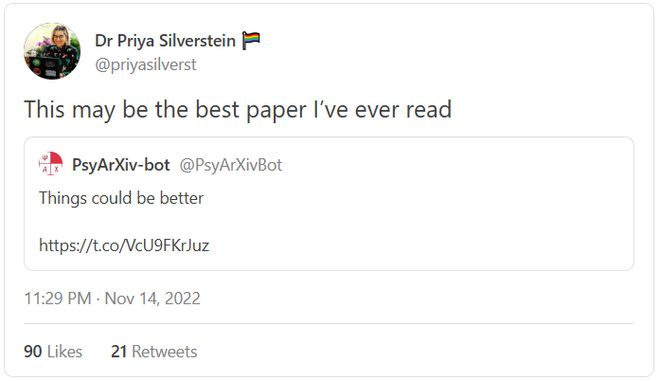
为什么同行评议审稿质量越来越差?
据一项调查统计,2016 年 NeurIPS 会议中,有 70% 的审稿人都是 PhD 在读学生。(Nihar Shah, 2022)
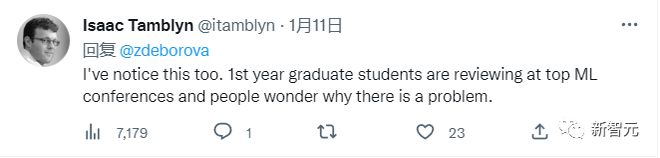
也有出现学生代替老师审稿的情况。
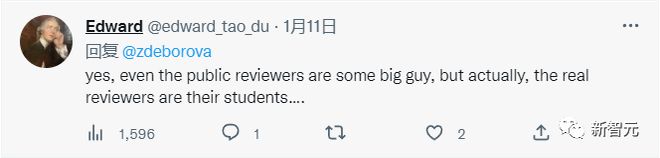
甚至在顶级学术会议中还会出现本科生作为审稿人的情况,这令各行各业的学者们感到可笑又无奈。
对于本科生而言,大部分时间都用在了完成学校的课业任务上,有科研经历的本科生少之又少,有非常成熟科研经历的本科生几乎不存在。 对于 PhD 学生而言,他们的科研也大多是在起步和尝试阶段。
让学生来审稿,无疑会使得审稿结果非常不可信,因为这些学生们面对的大多是自己还不太熟悉的领域的一篇新论文,要他们根据自己非常有限的科研经历来给出一个详实而可靠的审稿意见实在是太难了。
对于一些比较有经验的审稿人,他们有时也会因为自身研究方向的利益关系而在审稿过程中加入一些主观因素影响最终决定。
有人戏称说现在的审稿在某种意义上甚至不如随机审稿,说得也不无道理。
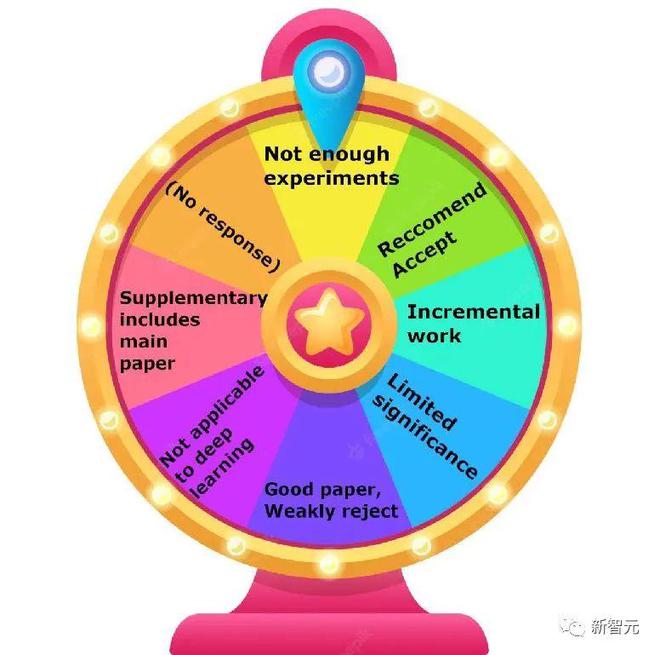
投稿量的激增,审稿人水平的下滑,审稿时间的减少,审稿人利益冲突,审稿报酬低下……这一系列问题造成了如今糟糕的同行评议质量。
诺奖获得者 Sydney Brenner 曾说过:「我不相信同行评议,因为我认为这是非常扭曲的,这只是回归到平均水平。我认为同行评议正在阻碍科学。事实上,我认为它已经成为一个完全腐败的系统。」
那么,在同行评议仍无法避免的今天,有什么办法挽救这一正危及整个科学界的现状呢?
不少会议已采用公开审稿的制度,即将投稿和审稿过程完全公开,这既可以限制投稿人投稿一些「水文」,也可以让审稿人对自己的审稿意见更加上心。
然而由于审稿人的匿名性以及自身专业水平的限制,公开审稿某种意义上来说「治标不治本」,对于审稿质量的改善并不大,大多是一些无关痛痒的改变。
为了进一步改善审稿质量问题,在 2021 年,来自宾夕法尼亚大学的苏炜杰教授提出了一种让投稿人自己「审稿」的方法,该论文已发表在 NeurIPS 2021 中。
值得一提的是,该方法并不是真的让投稿人去审稿自己的论文,而是让投稿人提供一个对自己投稿文章的质量排序,并使用保序回归(Isotonic Regression)帮助审稿人提高审稿质量。

论文地址:https://arxiv.org/abs/2110.14802
为什么作者的信息可以被利用?
对于一位审稿人来说,他在一次会议中可能被要求在短短十几天内审稿十余篇互不相关的文章,如果缺乏相关背景知识,这无疑是一项巨大的挑战。
相对于审稿人,作者对于自己的文章的了解度肯定是更高的。如果有一种方案可以让作者告诉审稿人自己对于自己的文章的真实看法,这些有效的信息无疑会给审稿过程提供一个另一维度的帮助。
该方法自提出以来受到了学界的广泛关注,在今年的 ICML 会议上,该方法已被应用到实验中。
值得一提的是,该方法原被设定用于处理一些处于“极端情况”的投稿(如审稿人与投稿人意见相差甚远的情况)。

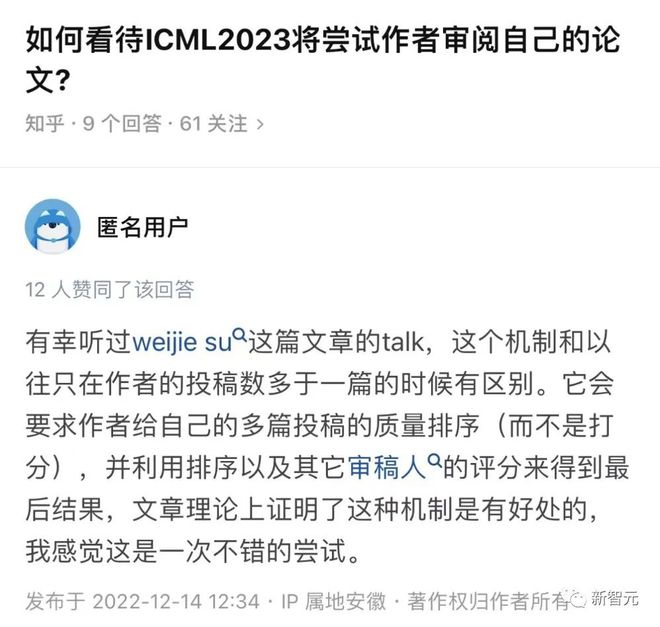
然而,该政策在国内外知乎、推特等平台上引起了一些争议,不少人把这个方法误解为让投稿人给自己的文章提供真正的文字评价。
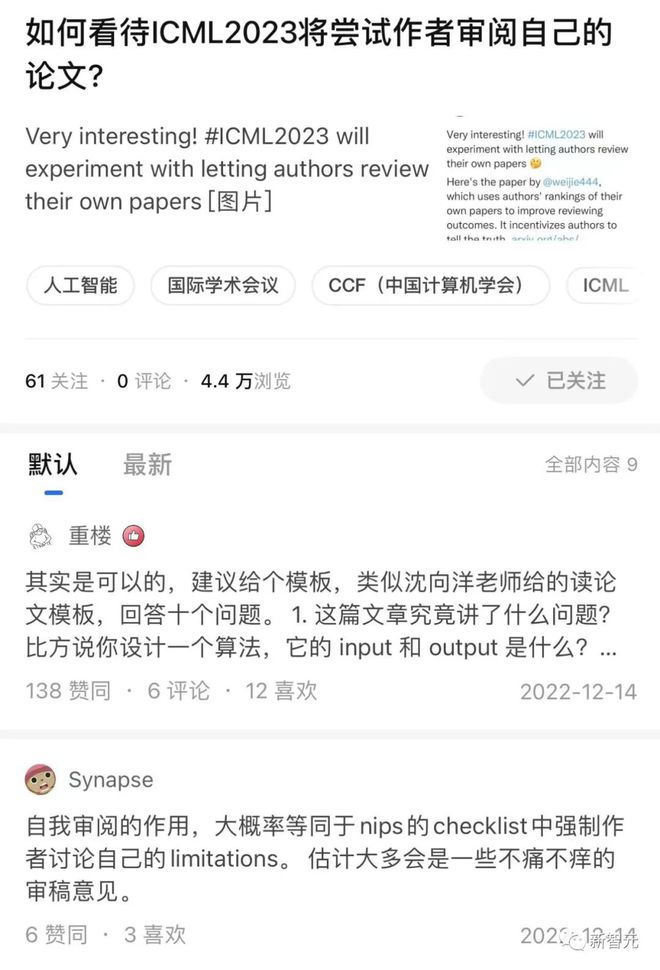

诚然,文字评价过于主观,无法有效阻止作者将自己的文章夸得天花乱坠的情况,且在 ChatGPT 等工具的帮助下,大段的文字往往会对于审稿增加更多的阻碍,自然不会是一个很有效的方法。
为什么让作者提供排序是合理的?
首先,在会议投稿量大大增加的情况下,投稿人单次会议投稿量超过一篇的情况也会大大增加,这也意味着排序对于很多作者来说是可以实现的(投稿量大于一篇即可)。
其次,排序不同于实际打分,作者所要做的只要提供对自己投稿的文章的一个好坏优先级顺序,这对于作者对自身的文章了解程度来说往往是容易的,所以让作者提供排序是一个低成本且较为客观的方式。而排序蕴含的信息量却不少,假设作者提供了一个真实的 5 篇文章的排序,它所蕴含的就至少有5! = 120 个两两比较的有效信息。
事实上,排序(ranking)有着广泛的应用场景。以 ChatGPT 为例,它的训练过程分为两个步骤,首先是根据同一个问题生成不同的回答,其次是让人类来对这些回答按照偏好进行排序。因为人类比机器更加懂得伦理与道德,且排序对人类来说非常容易,这样的训练过程是十分高效的。

在各平台上都有人对部分人群的误解给出了澄清,说明了这只是一个实验性质的尝试,且只要求作者给出排序而并非实际评价。
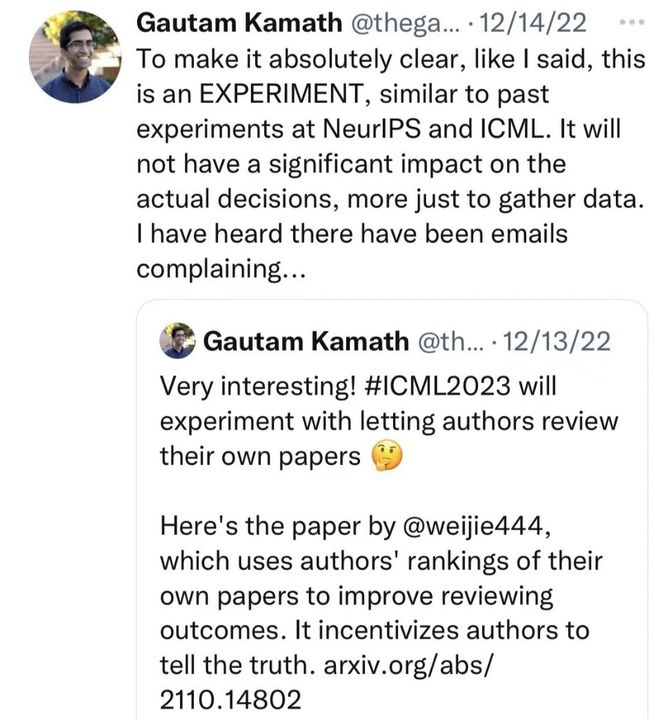
然而可惜的是,最终该方法还是被 ICML 组委会为了避免争议而修改为了」仅供实验用途」,并不会影响到任何一篇文章的最终接收意见。

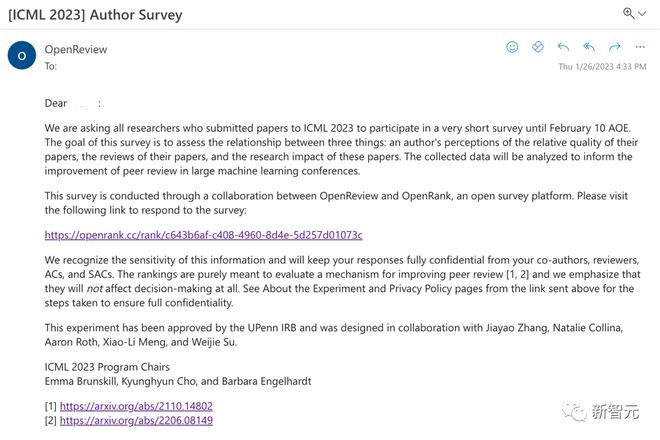
团队建立了一个网站(https://openrank.cc)和 OpenReview 合作的形式实现了该实验。
在 ICML 截止日 1 月 26 号当天,所有 ICML 作者收到了一封参加实验的邀请邮件。实验的最终目的是评估在未来的会议中将作者和审稿人的意见结合以提高审稿同行评议的质量的可行性,如果实验成功,未来将进一步推广并真正应用到实际审稿决策过程中。

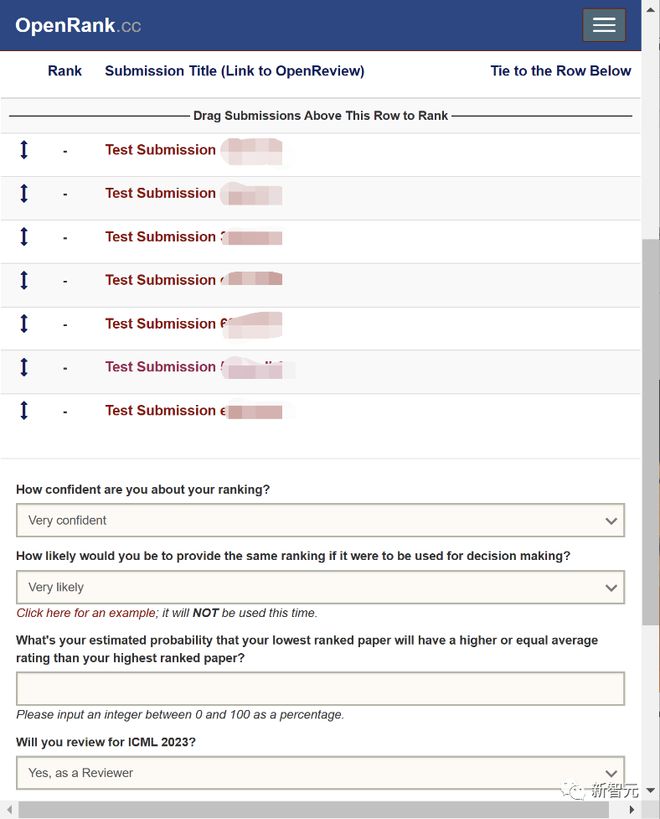
以下是 ICML2023 实验中投稿人所看到的画面示例。
可以发现,界面中并没有让作者给自己的文章提供实际文字评价的部分,只要求作者给出投稿文章的排序。
目前 ICML 的投稿已经截止,实验收集到近一万位作者的提交数据。基于独立伦理委员会和 ICML 程序委员会主席的要求,在 ICML 论文接收决定日 4 月 22 号之前不会进行数据分析。
如果该实验取得了成功,它将成为学术会议同行评议制度的一个里程碑,它为审稿制度开拓了作者评审这一全新的维度。
对于如何让作者的意见与价值观加入审稿过程,比如是否有除了排序以外其他的形式,未来也会有更多的可能性值得被探索。
作者简介
文章作者李朴恒现为北京大学数学科学学院大四本科生,即将赴斯坦福大学攻读博士学位。
该方法提出者苏炜杰是宾夕法尼亚大学沃顿商学院统计与数据科学系和工学院计算机系副教授。任宾大机器学习研究中心联合主任。分别于北京大学和斯坦福大学获得本科和博士学位。曾获得 NSF CAREER Award、斯隆研究奖、。
参考资料:
- https://icml.cc
- https://openrank.cc
- https://arxiv.org/abs/2110.14802
- https://arxiv.org/abs/2206.08149
- https://www.zhihu.com/question/572146140
- https://mp.weixin.qq.com/s/CmgHPLhVGnd1ifXdY5q3iw
- https://zhuanlan.zhihu.com/p/599192947?utm_source=wechat_session&utm_medium=social&s_r=0
- https://mp.weixin.qq.com/s/sLll4ZdNWoegSL_kykanBQ






