金磊发自凹非寺
量子位公众号 QbitAI
搞科研的最新姿势,被一位华人小哥解锁了——
告诉 AI 你的研究目标,再把数据集“投喂”进去,完事。

这就是来自伯克利的博士生 Zhong Ruiqi 等人的最新研究,把从海量数据集中繁琐的“取证”过程,统统交给GPT-3来解决:

他们还发现,这种用 AI 搞科研的方法不仅效率高,而且还能得出人类没有想到的“意外惊喜”。

让 GPT-3 帮你搞科研
那么小哥他们为什么突发奇想地要用这种方式搞科研呢?
这是因为他们发现,对大型语料库做深入的挖掘确实能得到一些有用的结果,但这个过程要是让人类来搞,那简直就太费时费力了。
因此,他们便决定把这个繁琐的过程交给 GPT-3 来处理,并把这个任务命名为“D5”:GoalDrivenDiscovery ofDistributionalDifferences via LanguageDescriptions.
- 通过语言描述,实现目标驱动的分布式差异的发现。
“D5”任务的过程,简单来说就是两个动作:
- 输入研究目标
- 输入两个语料库

例如在上面这个案例中,小哥先是给 AI 输进去了两个语料库:
- 语料库A:服用药物A后患者的反应报告
- 语料库B:服用药物B后患者的反应报告
然后再向 AI 确定自己的研究目标,即“我想了解一下药物A的副作用”。
在 AI 收到任务后,立刻开始执行分析工作,最后得出了它的结论:语料库A中的样本,有更多的患者会提到“妄想症”(paranoia)。
不过试想一下,若让人类科研人员做这项工作,光是了解语料库A和B就需要花费大量的时间,更别提还得进一步做对比分析等工作了。
而 D5 任务之所以能够做得如此丝滑,是因为小哥他们在此背后还做了不少工作。
例如构建 OpenD5 元数据集,它包含符合 D5 任务的 675 个开放式问题,所涉及领域涵盖商业、社会科学、人文科学、健康和机器学习等。
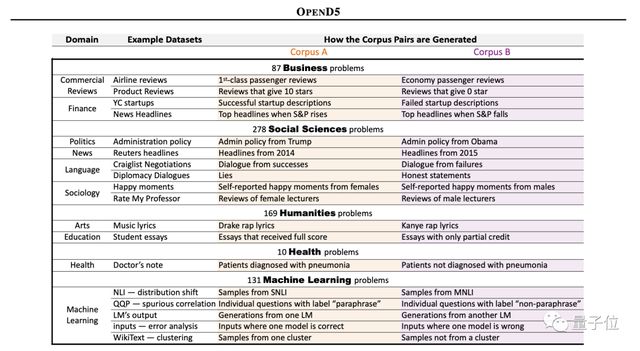
并且每个开放式问题都会对应一个语料库对儿(语料库A和语料库B),平均有 17000 个样本。
小哥还把每个语料库中的 50% 作为研究部分,另外 50% 则是拿来做验证。
基于此,小哥他们再构建了一个“D5 系统”,它的工作原理和人类从数据库中获取发现类似,分为两个阶段,即创造性地提出一个假设,再在数据集上严格验证这个假设。
按照这种思路,研究人员接下来用 GPT-3 做了次实验。
他们先是向 GPT3 展示研究目标和每个语料库中的一些样本,然后让它提出一个假设列表。
最终实验发现,GPT-3 可以使用目标描述来提出更相关、更新颖、更有意义的假设。

也正因为 OpenD5 数据集所涵盖的领域众多,因此小哥表示他们的 D5 系统具备应用范围广的特点。
也存在一些缺陷
但对于这套 D5 系统,小哥也直言不讳地道出了它的缺陷。
例如,若是语料库中含有较多的俚语、俗语或者带有情绪的词汇,那么 AI 所给出的“发现”就会存在偏差。
简而言之,就是 AI 对于特定情况的词汇或描述产生了错误的理解和分析。
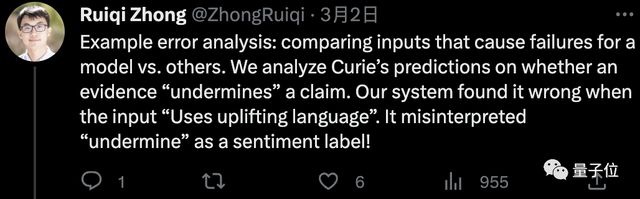
除此之外,小哥也表示更灵活的语料库、更具扩展性的系统,也是他们在未来重点研究的方向。
不过似乎这项研究让小哥也是兴奋不已,毕竟离他“构建一个用 AI 稿科研”的梦想更近了一步。

[1] https://arxiv.org/abs/2302.14233
[2] https://twitter.com/ZhongRuiqi/status/1631109680859865089?s=20






