
文光锥智能,作者周文斌
如果要给 4 月定一个主题,“大模型”应该当仁不让。
从 4 月 7 日阿里突然放出“通义千问”内测开始;8 日,华为放出盘古大模型;10 日,商汤推出类 ChatGPT 产品“商量 SenseChat”;之后,11 日的阿里云峰会,毫末 AI DAY,以及之后昆仑万维号称即将发布的“天工”......大模型如雨后春笋般涌现,成为所有活动的主题。
另一方面,当所有的目光都集中在企业最新的技术动态、产品质量,以及可能带来哪些商业革命的同时,另外一些事情在同样挑动人们的神经。
4 月 10 日,有网友通过 AI 技术“复活”了自己的奶奶,在网上引起广泛讨论。有人说,看到图像的那一刻眼眶就湿润了;也有人说,这有些不尊重逝者;更有人联想到如果有不法之徒利用这种技术,几乎可以随意将一个陌生人带回家当电子宠物......

图源扬子晚报
和通用 AI 技术的惊艳发展一样,安全伦理也是这场“AI 实验”的重要且关键主题。
事实上,从春秋战国时期钢铁冶炼技术的突破,到西方 18 世纪 60 年代出现的珍妮机,自古以来,当革命性的技术推动社会跨越式发展的同时,也会给社会的传统文化、社会范式带来冲撞和破坏。
AI 大模型同样也是如此,关于伦理道德的讨论只是其中的一个方面,这背后所有与人直接相关的,比如数据安全问题、AI 的可信度问题、隐私保护问题等等,都在冲撞着当前的数据治理格局。
就像 20 年前,我们打开每一个网页都害怕被病毒侵袭、被黑客攻击一样,在大模型飞速发展的今天,安全问题正在被重新抬回桌面。
因此,在享受技术突破带来发展红利的同时,如何应对这种冲撞,成为当代人需要思考的问题。
01 大模型来临,AI 安全迎来新挑战
大模型带来的关于伦理道德、数据安全和可信度的讨论,可能来的比所有人想象的都更早。
2021 年初,韩国人工智能初创公司 Scatter Lab 上线了一款基于 Facebook Messenger 的 AI 聊天机器人“李 LUDA”,但仅仅不到 20 天,Scatter Lab 就不得不将“李 LUDA”下线,并公开道歉。
道歉的原因,是“李 LUDA”失控了。
“李 LUDA”上线后,很快在韩国网络平台上受到欢迎,有 75 万名用户参与了互动。但在交流过程中,一些用户将侮辱“李 LUDA”作为炫耀的资本,对其发泄自身恶意,并在网上掀起“如何让 LUDA 堕落”的低俗讨论。
很快,随着各种负面信息的介入,“李 LUDA”还开始发表各种歧视性言论,涉及女性、同性恋、残障人士及不同种族人群。

而在“李 LUDA”变得越来越“暗黑”的同时,关于“李 LUDA”的数据安全和隐私保护也在受到诘问。
“李 LUDA”是 Scatter Lab 基于 Science of Love 数据开发的,Science of Love 可以分析韩国国民级聊天应用 KakaoTalk(类似于微信)的对话,显示用户间的情感水平,这也导致韩国个人信息保护委员会和互联网安全局开始介入调查。
“李 LUDA”的故事只是一个序曲,在两年之后的今天,在全球掀起技术革命的 OpenAI 也同样面临安全和可信的问题。
事实上,从 ChatGPT 推出的第一天起,到后来的谷歌 Bard,再到国内的文心一言,以及阿里的“通义千问”,几乎都面临着 AI“一本正经的胡说八道”的问题。
仍然以 ChatGPT 举例,有网友让其推荐 3 家西湖区的新兴咖啡馆,ChatGPT 正经地给出了名字、地址和介绍。但网友查询后却发现,压根没有这样三家咖啡店的存在。
同样的例子还有很多,因为 AI 的回答本质上是一个“概率问题”,即通过前一个字去猜后一个字的可能性,然后根据概率和语义选择最适合的组成一个句子。
所以当问到 AI 不曾了解的内容时,它仍然会随机生成答案。但这会给许多没有分辨能力的人带来误解。
在可信问题之外,数据安全是 AI 大模型面临的一个重要考题。
3 月底,OpenAI 发布一份报告显示,由于 Redis 的开源库 bug 导致了 ChatGPT 发生故障和数据泄露,造成部分用户可以看见其他用户的个人信息和聊天查询内容。
仅仅十天左右,意大利数据保护局 Garante 以涉嫌违反隐私规则为由,暂时禁止了 ChatGPT,并对相关事项展开调查。
事实上,这样的事情正在许多地方同时发生,比如三月中旬,自三星电子允许部分半导体业务员工使用 ChatGPT 开始,短短 20 天有三起机密资料外泄事件。
数据安全公司 Cyberhaven 的一份调查显示,在员工直接发给 ChatGPT 的企业数据中,有 11% 是敏感数据。在某一周内,10 万名员工给 ChatGPT 上传了 199 份机密文件、173 份客户数据和 159 次源代码。

众所周知,以 ChatGPT 为代表的 AI 大模型通过“人类反馈强化学习”来不断进化,这也要求类 ChatGPT 产品需要不停地收集用户使用数据。但这些数据回到后台之后,并没有进行脱敏处理,也无法被删除,而是进一步被纳入到了模型训练的数据库中,并随时面临可能被泄露的风险。
整体上,AI 大模型被广为人知以来,伦理、可信、数据安全的问题也逐渐被越来越多人感受到。但这其实就像一条新建成的自动化生产线,生产效率很高,但还有许多地方的卫生条件没有达到要求。
我们并不应该因为这一些局部的瑕疵而否认整个生产线的价值,但这些潜在的隐患也同样需要去规避和完善。
02 AI 安全,任重道远
事实上,无论是产业界还是相关的监管机构,其实都早已意识到了问题,并且也都在积极寻求改变。
比如 OpenAI 就在积极提高其预训练大模型的安全性,在 GTP-4 发布时,OpenAI 的安全测试显示,GPT-4 比 GPT-3.5 的得分要高出 40%。
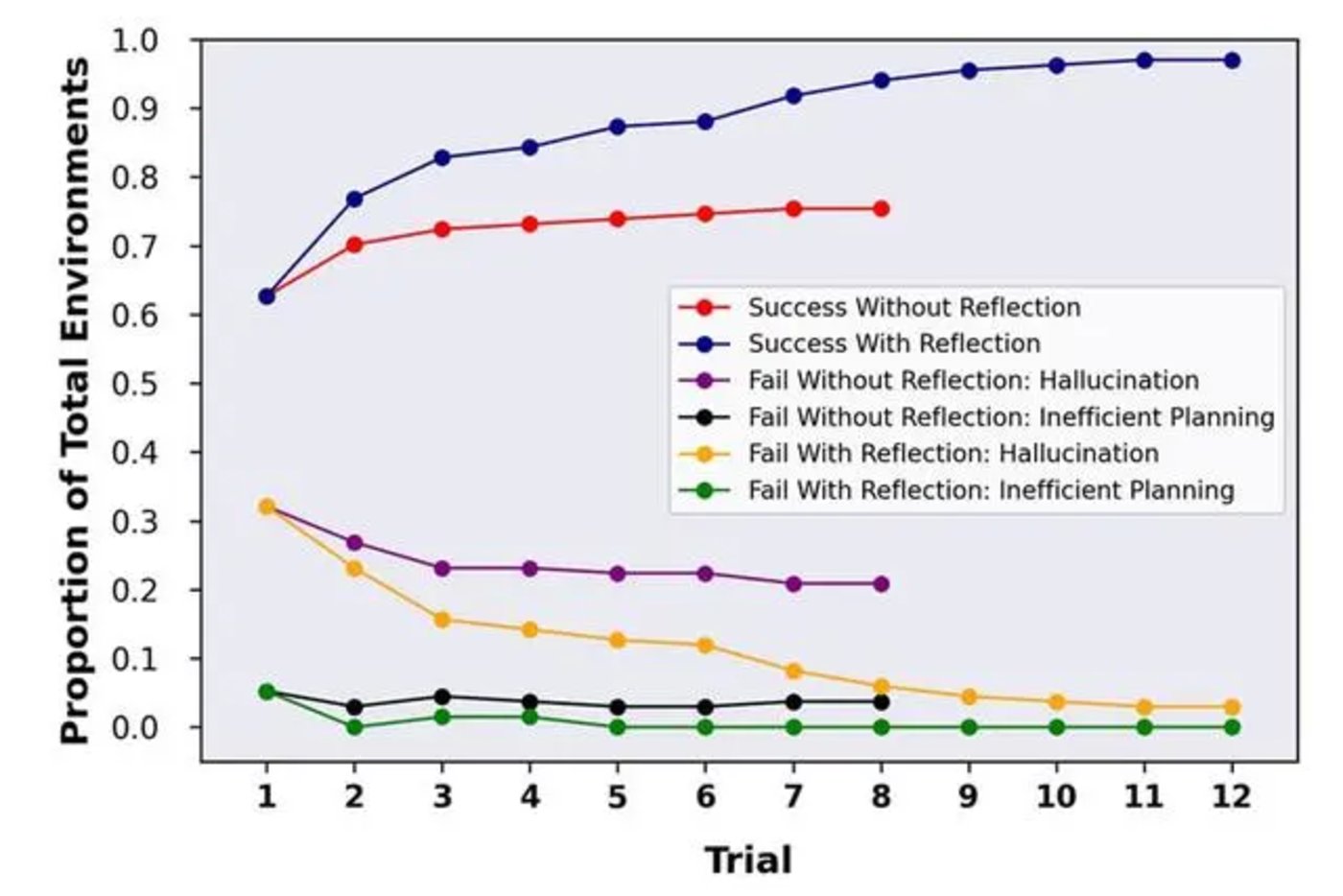
OpenAI 开发了一项新技术,让 AI 能够模拟人类的自我反思。这让 GPT-4 在 HumanEval 编码测试中的准确率从 67% 上升到 88%。在 Alfworld 测试中准确率从 73% 提高到了 97%;在 HotPotQA 测试中准确率从 34% 提高到 54%。
当然,Open AI 官网仍然在警告用户,在使用 GPT-4 输出的内容时应格外小心,特别是在高风险场景下(如医学、化学等领域)需要人工核查事实准确性,或者压根避免使用 AI 给出的答案。
除了在模型阶段介入新技术之外,更多公司开始从数据阶段就将隐私考虑了进去,比如数据合成和隐私计算就是两种有效的解决方案。
其中,合成数据是指计算机通过模拟技术,或算法自己生成的标注信息,能够在数学上或统计学上反映原始数据的属性,因此可以作为原始数据的替代品来训练、测试、验证大模型。但由于数据是合成的,因此不会涉及到真实的用户隐私和数据安全问题。
而隐私计算则是一种保护数据隐私的计算方法,它可以在不暴露数据内容的前提下进行数据处理、分析、共享等操作,关键就是让数据“可用,但不可见”。
除了在通过研发新技术提高 AI 能力之外,微软在开放 NewBing 时也考虑从其他方式限制 AI 胡说八道。
现在使用微软更新的 NewBing 时,AI 不仅会告诉你答案,还会像论文标注一样,将得出结论的数据来源进行标注,方便用户回溯,确认信源是否可靠。

当然,在这方面投入努力的也不只是企业,并且也不局限在技术和产品上。
从 2021 年开始,为了保障数据安全、个人隐私、道德伦理、以及从跨国市场规范、AI 平权等多项目标考虑,欧盟就开始推进《人工智能法案》,按既定节奏,该项法案在 3 月底提交欧盟议会审议。
在欧盟推进立法的同时,联合国教科文组织(UNESCO)总干事奥德蕾·阿祖莱也在 3 月 30 日发表声明,呼吁各国尽快实施该组织通过的《人工智能伦理问题建议书》,为人工智能发展设立伦理标准。
中国在这方面同样也在推进相关监管法案的落地。4 月 11 日,国家网信办起草《生成式人工智能服务管理办法(征求意见稿)》并向社会公开征求意见。该《办法》聚焦隐私安全、技术滥用、知识产权和他人权益三大问题,为 AIGC 的发展建立防护栏。
除此之外,学界和企业界也在积极探索新的方式。比如 4 月 7 日,清华大学与蚂蚁集团达成合作,双方携手攻坚可信 AI、安全大模型等下一代安全科技,在可信 AI 方面联合攻克安全对抗、博弈攻防、噪声学习等核心技术,来提升规模化落地中的 AI 模型的可解释性、鲁棒性、公平性及隐私保护能力;并基于互联网异构数据,构建面向网络安全、数据安全、内容安全、交易安全等多领域多任务的安全通用大模型。
除此之外,作为互联网时代的安全企业,周鸿祎在新智者大会上也提到人工智能的安全挑战。周鸿祎将其归纳为七点:硬件、软件、通信协议、算法、数据、应用和社会伦理。但周鸿祎也提到:“仅靠一家企业不能解决所有威胁,需要注重生态合作。”
整体上,自 ChatGPT 以来,AGI 的大门也才刚刚打开,就如同 AI 大模型仍在探索一样,其与传统产业、安全、社会伦理等方面的冲突也才刚刚开始,整个治理、重建、规范的过程也都还仍重道远,需要整个社会的共同努力。






