
1 月 29 日消息,百川智能发布超千亿参数的大语言模型 Baichuan 3。据介绍,Baichuan 3 取得了系列新突破。
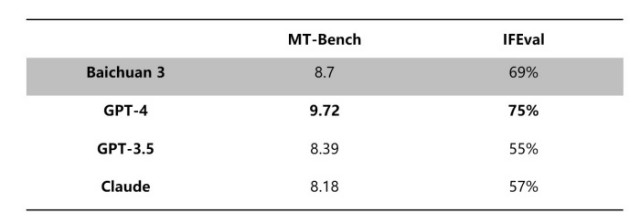
其中基础能力方面,Baichuan 3 在 CMMLU、GAOKAO 和 AGI-Eval 多个权威通用能力评测中都表现出色,尤其在中文任务上更是超越了 GPT-4。在数学和代码专项评测如 MATH、HumanEval 和 MBPP 中 Baichuan 3 同样表现出色。
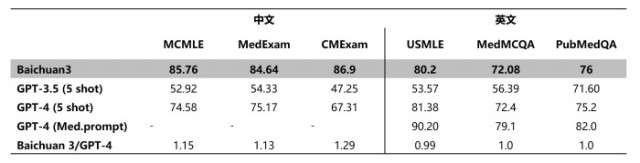
值得注意的是,百川智能对 Baichuan 3 在医疗领域的能力进行了针对性优化,在对逻辑推理能力及专业性要求极高的 MCMLE、MedExam、CMExam 等权威医疗评测上的中文效果同样超过了 GPT-4,成为中文医疗任务表现最佳的大模型。
另外,Baichuan 3 还突破“迭代式强化学习”技术,进一步提升了语义理解和生成能力,在诗词创作的格式、韵律、表意等方面表现优异,领先于其他大模型。
中文任务成绩超越 GPT-4
Baichuan 3 在多个英文评测中表现出色,达到接近 GPT-4 的水平。而在 CMMLU、GAOKAO、HumanEval 和 MBPP 等多个中文评测榜单上,更是超越 GPT-4 展现了其在中文任务上的优势。
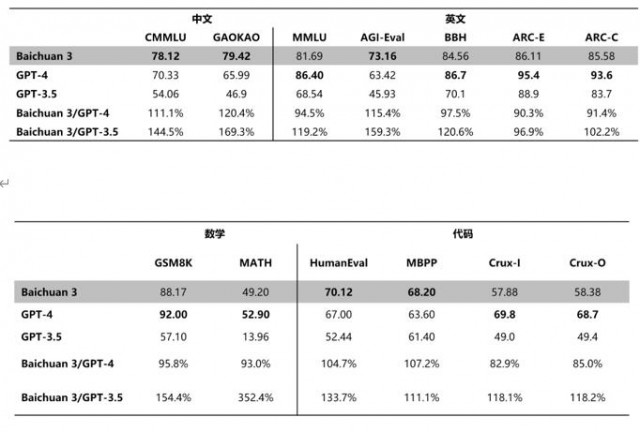
此外,在 MT-Bench、IFEval 等对齐榜单的评测中,Baichuan 3 超越了 GPT-3.5、Claude 等大模型,处于行业领先水平。
据介绍,百川智能在训练过程中针对性地提出了“动态数据选择”、“重要度保持”以及“异步 CheckPoint 存储”等多种创新技术手段及方案,有效提升了 Baicuan 3 的各项能力。训练效率方面, Baichuan 3 的训练框架在性能方面相比业界主流框架提升超过 30%。
医疗能力逼近 GPT-4
在医疗领域,大模型的全能特性发挥着至关重要的作用。诸如 OpenAI、谷歌等头部大模型企业都将医疗作为模型的重点训练方向和性能评价的重要体系。ChatGPT 早在 2023 年 2 月便已通过了美国医学执照考试(USMLE),显示出其在医学领域的强大能力。而谷歌对医疗领域的重视更甚,基于 PaLM 模型打造了医疗大模型 Med-PaLM,迭代后的 Med-PaLM 2 在医学考试 MedQA 中的成绩超过 80 分,达到了专家水平。
为了给 Baichuan3 注入丰富的医疗知识,百川智能在模型预训练阶段构建了超过千亿 Token 的医疗数据集,包括医学研究文献、真实的电子病历资料、医学领域的专业书籍和知识库资源、针对医疗问题的问答资料等。该数据集涵盖了从理论到实际操作,从基础理论到临床应用等各个方面的医学知识,确保了模型在医疗领域的专业度和知识深度。
针对医疗知识激发的问题,百川智能在推理阶段针对 Prompt 做了系统性的研究和调优,通过准确的描述任务、恰当的示例样本选择,让模型输出更加准确以及符合逻辑的推理步骤,Baichuan 3 在医疗领域的任务效果提升显著,在各类中英文医疗测试中的成绩提升了 2 到 14 个百分点。
Baichuan 3 在多个权威医疗评测任务中表现优异,不仅 MCMLE、MedExam、CMExam 等中文医疗任务的评测成绩超过 GPT-4,USMLE、MedMCQA 等英文医疗任务的评测成绩也逼近了 GPT-4 的水准,是医疗能力最强的中文大模型。
创作精准度提升
另外,百川智能还强调,Baichuan 3 突破“迭代式强化学习”技术,进一步提升了语义理解和生成能力,在诗词创作的格式、韵律、表意等方面表现更优了。
语义理解和文本生成是大模型最基础的底层能力,为提升这两项能力,业界进行了大量探索和实践,OpenAI、Google 以及 Anthropic 等引入的 RLHF (基于人类反馈的强化学习)和 RLAIF (基于 AI 反馈的强化学习)便是其中的关键技术。
百川智能采用了 RLHF 与 RLAIF 结合的方式来生成高质量优质偏序数据,在数据质量和数据成本之间获得了更好的平衡。在此基础上,对于“探索与利用”这一根本挑战,百川智能通过 PPO 探索空间与 Reward Model 评价空间的同步升级,实现“迭代式强化学习”(iterative RLHF&RLAIF),让 Baichuan 3 的语义理解和生成创作能力大幅提升。
百川智能强大,Baichuan 3 结合“RLHF&RLAIF”以及迭代式强化学习的方法,让大模型的诗词创作能力达到全新高度。可用性相比当前业界最好的模型水平提升达 500%,文采远超 GPT-4。以下为 Baichuan 3 所写的两首诗词,可以看看:







