鱼羊发自凹非寺
量子位公众号 QbitAI
大神 Karpathy 从 OpenAI 离职,原本扬言要大休一周。
但转眼,新项目就已上线 GitHub,日增上千星的那种。
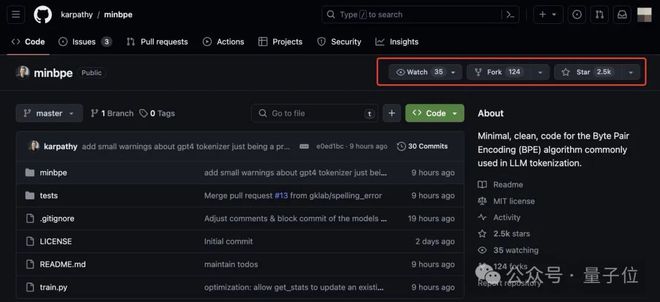
还是熟悉的卡式配方:
74 行 Python 代码搞定大模型标记化(tokenization)中常用的 BPE(Byte Pair Encoding)算法,实现该算法的最小、最干净代码版本。
甚至:

是不是有点快 3 万标星的nanoGPT内味儿了?
这波啊,还真是让网友们给猜着了:
Time to cook。

毕竟,Karpathy 除了前特斯拉 AI 总监、OpenAI 创始成员的 title,最为网友所熟悉的,就是“AI 领域大善人”、“擅长将复杂问题简单化的卡老师”这样的身份了(手动狗头)。
BPE 代码最小化版本
还是具体来看一下,Karpathy 老师这次又煮出了一锅什么样的饭。

项目名minbpe已经说明一切:BPE 算法的最小、最干净代码版本。
BPE(字节对编码)是随着 GPT-2 而流行起来的标记化算法。现在,包括 GPT 系列、Llama 系列和 Mistral 在内,一众大模型都用到了这一算法来训练分词器。
BPE 的主要优势在于:
- 高效:通过合并频繁出现的字节对来逐步构建词汇表,可以有效地减少模型需要处理的词汇量。
- 灵活:可以将词汇表外的单词分解为已知子词来进行处理,有助于模型理解和生成未在训练中出现的单词。
而在 minbpe 这个项目中,Karpathy 提供了两个 Tokenizer(分词器),它们都可以执行分词器的 3 个主要功能:
- 基于特定文本训练词汇表和合并操作
- 把文本编码成 token
- 把 token 解码为文本
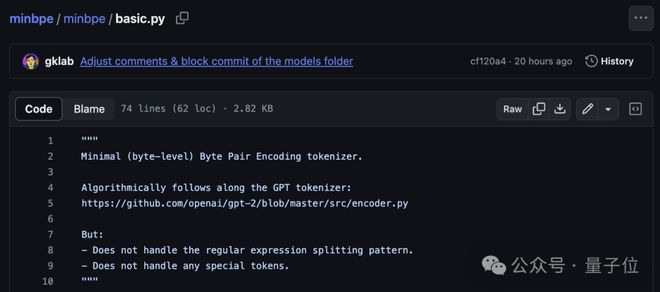
具体而言,在basic.py中,minbpe 用 74 行 Python 代码,完成了对直接在文本上运行的 BPE 算法的最简单实现。
在regex.py中,minbpe 实现的是一个正则表达式分词器,该分词器利用正则表达式进一步拆分输入的文本。
另外,在正则表达式分词器的基础之上,minbpe 还在gpt4.py中提供了一个 GPT4Tokenizer,可以准确在线 tiktoken 库中的 GPT-4 标记化。
注:tiktoken 是一种快速 BPE 分词器。
base.py 则是一个基类,包含了训练、编码和解码的存根(stubs),提供了保存和加载的功能,并集成了一些常见的辅助工具函数。在实际应用中,开发者应该通过继承这个基类来实现具体的分词器功能。
Karpathy 提到,他在霉霉的维基百科文本上尝试训练了两个主要的分词器。train.py 在他的 M1 MacBook 上运行时间大概为 25 秒。
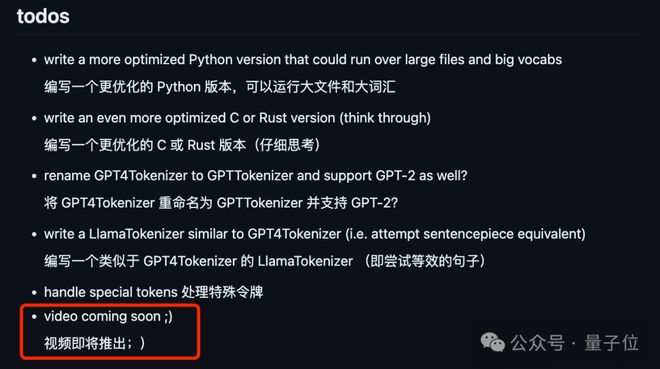
如果你还有什么不清楚的地方,别担心,卡老师已经计划要出视频了:
Karpathy 出走 OpenAI,许多猜测指向他的“下一篇章”是大语言模型系统(LLM OS):
如今正式工作还未揭示,但看样子 Karpathy 已经拾起了“教学育人”的副业,小伙伴们可以蹲起来了(doge)。
参考链接:
https://github.com/karpathy/minbpe/
— 完 —






