
新智元报道
编辑:Aeneas 好困
威尔·史密斯的这段视频,把全网都骗了!其实 Sora 的技术路线,早已被人预言了。李飞飞去年就用 Transformer 做出了逼真的视频。但只有 OpenAI 大力出奇迹,跑在了所有人前面。
今天,全体 AI 社区都被威尔·史密斯发出的这段视频震惊了!
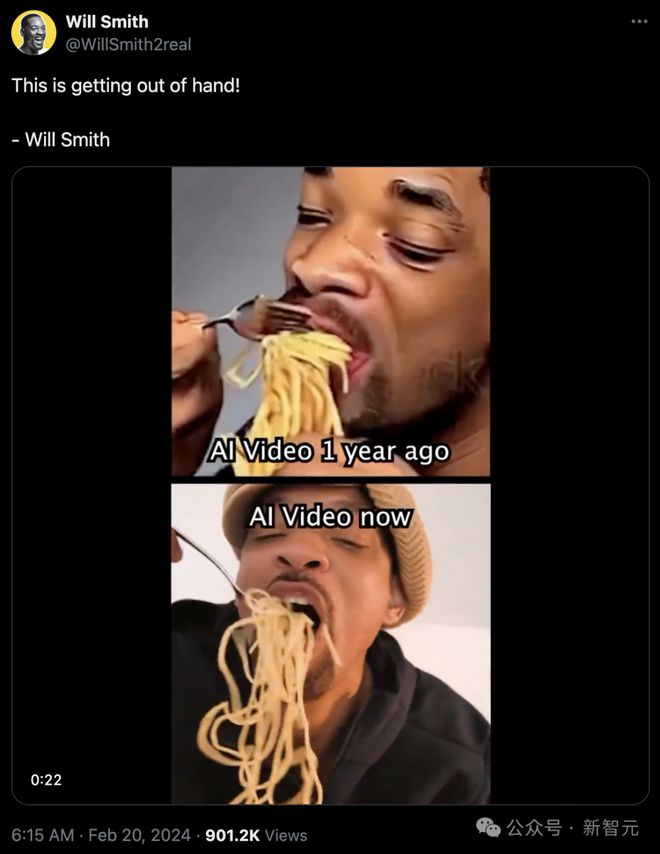
你以为,上面是一年前的 AI 视频,下面是如今的 AI 视频?

错!这个所谓 AI 生成的视频,其实正是威尔史密斯本人!

威尔·史密斯吃意面这个「图灵测试」,曾让 Runway、Pika 等屡屡翻车。
Runway 生成的,是这样的——



但如今,Sora 已经做到了逼真似真人、毫无破绽,所以才让威尔史密斯成功骗过了大众,这太可怕了!

Sora 的出现,其实在今年 1 月就已被人预言
1 月 5 日,一位前阿里的 AI 专家表示——
我认为,Transformer 框架和 LLM 路线,将是 AI 视频的一个突破口和新范式,它将使 AI 视频更加连贯、一致,并且时长更长。目前的 Diffusion+Unet 路线(如 Runway、Pika 等),只是暂时的解决方案。

无独有偶,斯坦福学者李飞飞在去年年底,就用 Transformer 就做出了逼真的视频。
而马毅教授也表示,自己团队去年在 NeurIPS 一篇论文中也已经证实,用 Transformer 可以实现 diffusion 和 denosing。

马毅团队提出:假设数据分布是 mixed Gaussians,那 Transformer blocks 就是在实现 diffusion/扩散和 denoising/压缩
能想到 Sora 技术路线的,肯定不止一个人。可是全世界第一个把 Sora 做出来的,就是 OpenAI。
OpenAI 为何总能成功?无他,唯手快尔。
Runway 和 Pika「点歪」的科技树,被 OpenAI 掰正了
在此之前,Runway、Pika 等 AI 视频工具吸引了不少聚光灯。

而 OpenAI 的 Sora,不仅效果更加真实,就是把 Transformer 对前后文的理解和强大的一致性,发挥得淋漓尽致。
这个全新的科技树,可真是够震撼的。
不过我们在开头也可以看到,OpenAI 并不是第一个想到这个的人。Transformer 框架 +LLM 路线这种新范式,其实早已有人想到了。
就如同 AI 大V「阑夕」所言,OpenAI 用最简单的话,把最复杂的技术讲清楚了——
「图片只是单帧的视频。」
科技行业这种从容的公共表达,真是前所未见,令人醍醐灌顶。

「阑夕」指出,「图片只是单帧的视频」的妙处就在于,图片的创建不会脱离时间轴而存在,Sora 实际上是提前给视频写了脚本的。
甚至无论用户怎样 Prompt,Sora AI 都有自己的构图思维。
而这,就是困住 Runway、Pika 等公司最大的问题。
它们的思路,基本都是基于一张图片来让 AI 去想象,完成延伸和填补,从而叠加成视频。比拼的是谁家的 AI 更能理解用户想要的内容。
因此,这些 AI 视频极易发生变形,如何保持一致性成了登天般的难题。
Diffusion Model 这一局,是彻底输给 Transformer 了。
ChatGPT 故事再次重演,Sora 其实站在谷歌的肩膀上
让我们深入扒一扒,Sora 是站在哪些前人的肩膀上。
简而言之,最大创新 Patch 的论文,是谷歌发表的。
Diffusion Transformer 的论文,来自 William Peebles 和谢赛宁。
此外,Meta 等机构、UC 伯克利等名校皆有贡献。
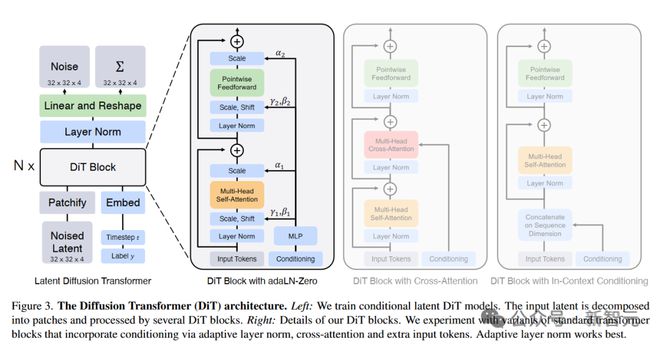
William Peebles 和谢赛宁提出的框架
纽约大学计算机系助理教授谢赛宁在分析了 Sora 的技术报告后表示,Sora 应该是基于自己和 William Peebles 提出的框架设计而成。

这篇提出了 Sora 基础架构的论文,去年被 ICCV 收录。

论文地址:https://arxiv.org/abs/2212.09748
随后,William Peebles 加入了 OpenAI,领导了开发 Sora 的技术团队。

图灵三巨头之一、Meta AI 主管 LeCun,也转发了谢赛宁的帖子表示认可。
巧合的是,谢赛宁是 LeCun 的前 FAIR 同事、现纽约大学同事,William Peebles 是 LeCun 的前伯克利学生、现任 OpenAI 工程师。AI 果然是个圈。

最近,谢赛宁对说自己是 Sora 作者的说法进行了辟谣
CVPR「有眼不识泰山」,拒掉 Sora 基础论文
有趣的是,Diffusion Transformer 这篇论文曾因「缺乏创新性」被 CVPR 2023 拒收,后来才被 ICCV2003 接收。
谢赛宁表示,他们在 DIT 项目没有创造太多的新东西,但是两个方面的问题:简单性和可扩展性。这可能就是 Sora 为什么要基于 DIT 构建的主要原因。
此前,生成模型的方法包括 GAN、自回归、扩散模型。它们都有各自的优势和局限性。
而 Sora 引入的,是一种全新的范式转变——新的建模技术和灵活性,可以处理各种时间、纵横比和分辨率。
Sora 所做的,是把 Diffusion 和 Transformer 架构结合在一起,创建了 diffusion transformer 模型。
这也即是 OpenAI 的创新之处。
时空 Patch 是谷歌的创新
时空 Patch,是 Sora 创新的核心。

它建立在 Google DeepMind 早期对 NaViT 和 ViT(视觉 Transformer)的研究之上。

论文地址:https://arxiv.org/abs/2307.06304
而这项研究,又是基于一篇 2021 年的论文「An Image is Worth 16x16 Words」。

论文地址:https://arxiv.org/abs/2010.11929
传统上,对于视觉 Transformer,研究者都是使用一系列图像 Patch 来训练用于图像识别的 Transformer 模型,而不是用于语言 Transformer 的单词。
这些 Patch,能使我们能够摆脱卷积神经网络进行图像处理。

然而,视觉 Transforemr 对图像训练数据的限制是固定的,这些数据的大小和纵横比是固定的,这就限制了质量,并且需要大量的图像预处理。

而通过将视频视为 Patch 序列,Sora 保持了原始的纵横比和分辨率,类似于 NaViT 对图像的处理。
这种保存,对于捕捉视觉数据的真正本质至关重要!
通过这种方法,模型能够从更准确的世界表示中学习,从而赋予 Sora 近乎神奇的准确性。
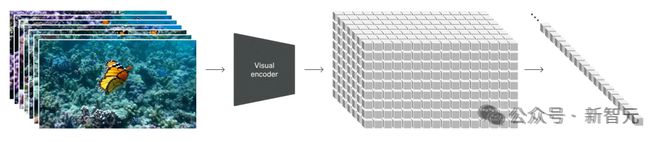
时空 Patch 的可视化
谷歌 Patch 的论文,发表于 2021 年。3 年后,OpenAI 基于这项技术,做出了 Sora。
这段历史看起来是不是有点眼熟?简直就像「Attention Is All You Need」的历史重演。
2017 年 6 月 12 日,8 位谷歌研究人员发表了 Attention is All You Need,大名鼎鼎的 Transformer 横空出世。
它的出现,让 NLP 变了天,成为自然语言领域的主流模型。

论文地址:https://arxiv.org/pdf/1706.03762.pdf
它完全摒弃了递归结构,依赖注意力机制,挖掘输入和输出之间的关系,进而实现了并行计算。
在谷歌看来,Transformer 是一种语言理解的新型神经网络架构。不过它当初被设计出来,是为了解决翻译问题。
而后来,Transformer 架构被 OpenAI 拿来发扬光大,成为 ChatGPT 这类 LLM 的核心。
2022 年,OpenAI 用谷歌 17 年发表的 Transformer 做出 ChatGPT。
2024 年,OpenAI 用谷歌 21 年发表的 Patch 做出 Sora。
这也让人不由感慨:诚如《为什么伟大不能被计划》一书中所言,伟大的成就与发明,往往是偏离最初计划的结果。
前人的无心插柳,给后人的成功做好了奠基石,而一条成功的道路是如何踏出的,完全是出于偶然。
Meta 微软 UC 伯克利斯坦福 MIT 亦有贡献
此外,从 Sora 参考文献中可以看出,多个机构和名校都对 Sora 做出了贡献。

比如,用 Transformer 做扩散模型的去噪骨干这个方法,早已被斯坦福学者李飞飞证明。
在去年 12 月,李飞飞携斯坦福联袂谷歌,用 Transformer 生成了逼真视频。
生成的效果可谓媲美 Gen-2 比肩 Pika,当时许多人激动地感慨——2023 年已成 AI 视频元年,谁成想 2024 一开年,OpenAI 新的震撼就来了!
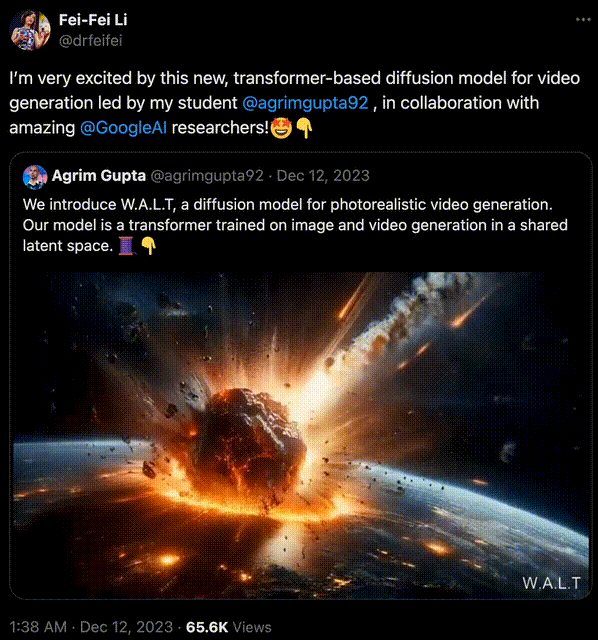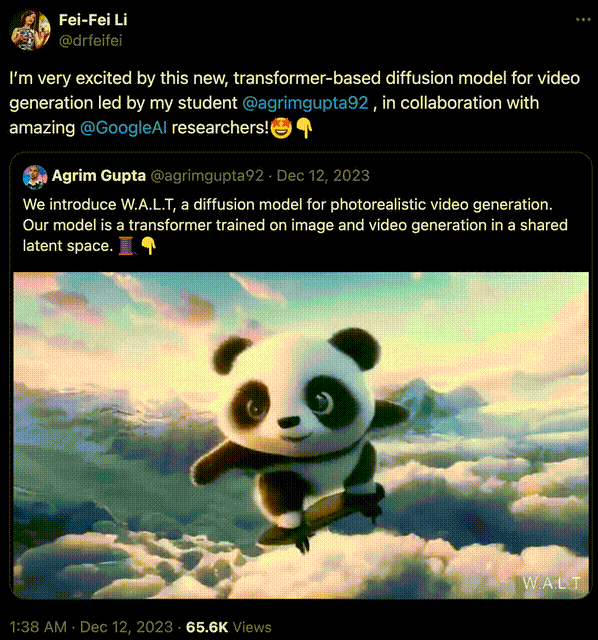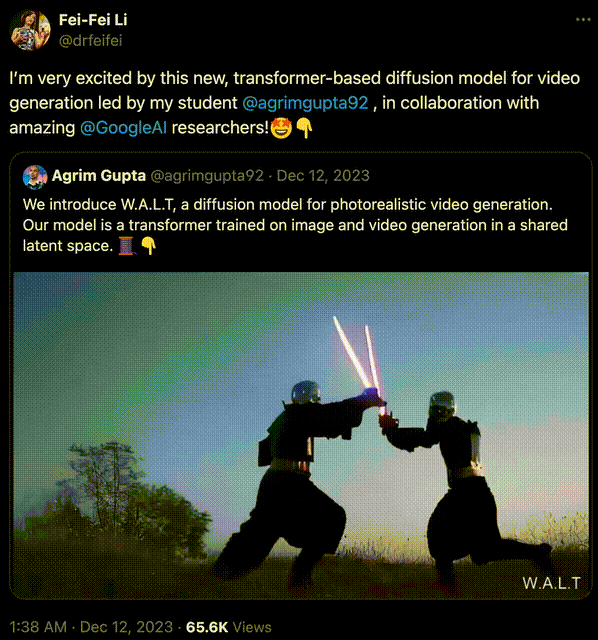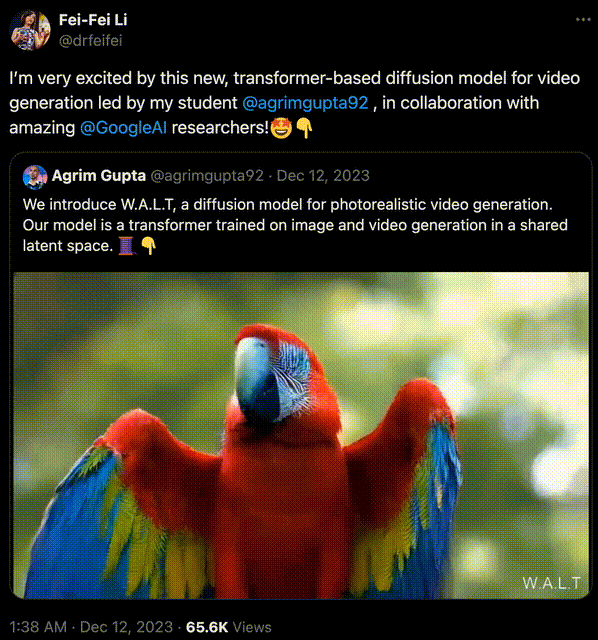
李飞飞团队做的,是一个在共享潜空间中训练图像和视频生成的,基于 Transformer 的扩散模型。
史上首次,AI 学者证明了:Transformer 架构可以将图像和视频编码到一个共享的潜空间中!

论文:https://walt-video-diffusion.github.io/assets/W.A.L.T.pdf
MSRA 和北大联合团队提出的统一多模态预训练模型——NÜWA(女娲),也为 Sora 做出了贡献。
此前的多模态模型要么只能处理图像,要么只能处理视频,而NÜWA 则可以为各种视觉合成任务,生成新的图像和视频数据。

项目地址:https://github.com/microsoft/NUWA
为了在不同场景下同时覆盖语言、图像和视频,团队设计了一个三维变换器编码器-解码器框架。
它不仅可以处理作为三维数据的视频,还可以适应分别作为一维和二维数据的文本和图像。
在 8 个下游任务中,NÜWA 都取得了新的 SOTA,在文本到图像生成中的表现,更是直接超越了 DALL-E。
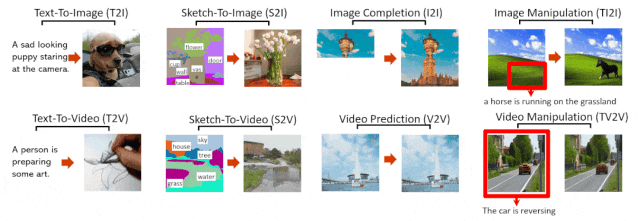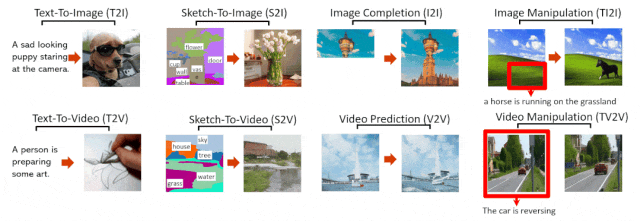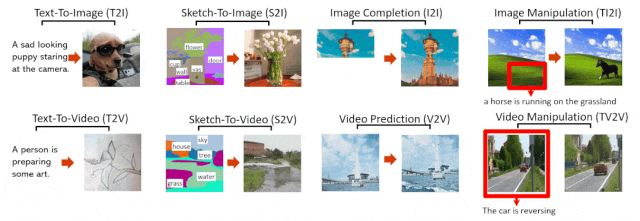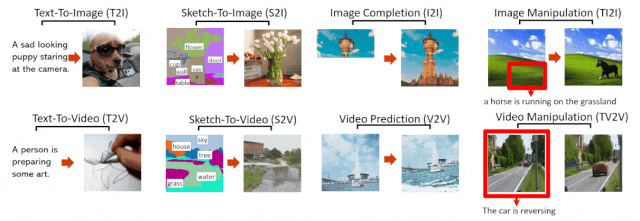
NÜWA 模型支持的 8 种典型视觉生成任务
草蛇灰线,伏脉千里。踩在前人的肩膀上,通过敏锐的直觉和不眠不休的高强度工作,OpenAI 的研究者就这样点对了科技树。
大力出奇迹的时候到了,不拿出一百亿美金的大厂就会 out
当然,还有一点不得不承认的是:OpenAI 能做出 Sora,也是因为背后大量的资金支持。
没有资金,就没有数据和算力。即使点对了科技树也无法验证。
可以说,Sora 是另一个建立在 Transformer 上的暴力美学。
现在,芯片 +AI 是人类有史以来最大的科技浪潮。
不拿出 100 亿美金的大厂,就要掉队了。
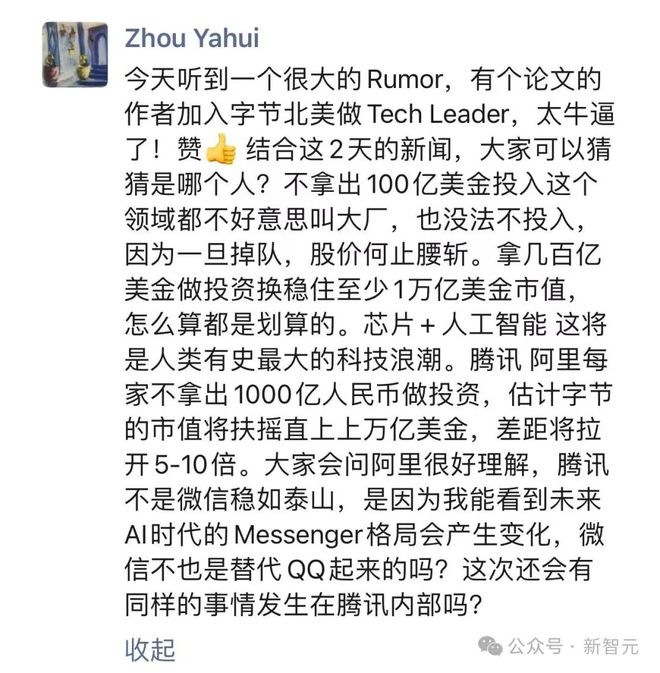
国内这边,格局又会怎样变换?让我们拭目以待。
参考资料:
https://weibo.com/1727858283/O1isjz6aw
https://openai.com/research/video-generation-models-as-world-simulators






