
©产业象限原创
作者丨山茶
2 月 22 日,英伟达发布 2024 财年四季报,营收 221 亿美元,同比增长 265%,净利润 123 亿美元,同比激增 769%,双双大超市场预期。
然后,英伟达就杀疯了。
一夜之间,英伟达市值暴涨 2770 亿美元,创下华尔街单日最大涨幅的历史记录。如今,英伟达的市值已经逼近 2 万亿美元。以国内生产总值计算,英伟达市值超过了大多数其他国家经济体的规模。
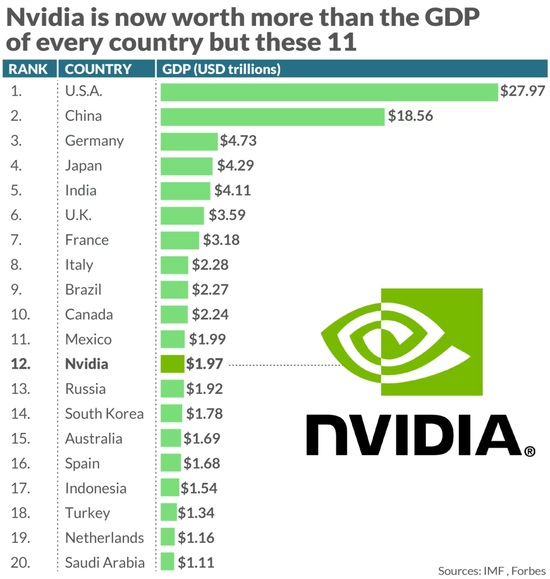
▲图源:福布斯
从企业层面看,这一市值也超越 Meta,成为仅次于微软、苹果和沙特阿美的全球第四大市值的巨无霸。
但有意思的现象是,虽然已经跻身第一梯队,但无论是营收还是利润,英伟达都与微软、苹果、甚至被它超过的 Meta 差距较远。
可以对比来看:
-
微软 2024 财年 Q2 营收 620.2 亿美元,净利润 218.7 亿美元;
-
苹果 2024 财年 Q1 营收 1195 亿美元,净利润 339.16 亿美元;
-
Meta2023 年 Q4 营收 401 亿美元,净利润 140.17 亿美元。
《巴伦周刊》使用基于 FactSet 预测的 2023 年至 2026 年预期平均盈利增长,以及基于 2024 年预测的市盈率,对美股 7 大巨头企业的 PEG 比率(市盈率除以盈利增长率)也做了预测,英伟达是其中最低的。
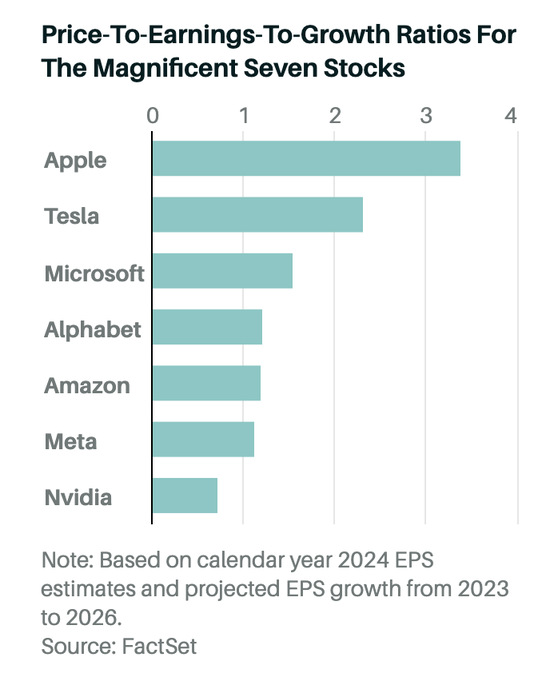
▲图源:FactSet
毫无疑问,如今英伟达的市值存在巨大泡沫,但从国内到国外,投资者却都愿意为这样的泡沫买单。
整个市场对英伟达充满信心,因为在某种程度上,市场已经将英伟达与 AI 时代的未来划上了等号。
投资英伟达,就是投资属于未来的 AI 时代,在这样的逻辑下,英伟达似乎值得任何市值。
那么,英伟达真的不可替代吗?谁又会成为英伟达的对手,谁又能将它赶下神坛?
01
英伟达,凭什么遥遥领先?
和其它半导体企业相比,英伟达是“遥遥领先”的,起码在市值上如此。
如今,在全球前十的半导体企业中,不算台积电和阿斯麦这样的纯代工厂和光刻机厂商,英伟达的市值约等于剩下七家市值的总和,甚至还有富余。
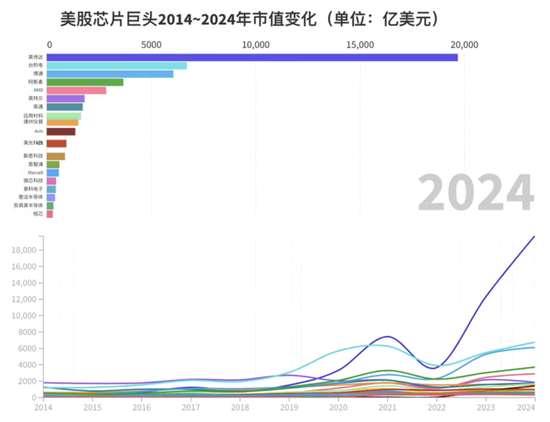
▲图源:芯东西
撑起英伟达市值的,是其全球领先的 AI 计算芯片,包括 A100、H100 和即将上市的 H200。根据富国银行的统计,英伟达目前在全球数据中心 AI 加速市场拥有 98% 的份额,处于绝对的统治地位。
很多时候,这些芯片花钱也都很难买到。早在 2023 年 8 月的时候,就有媒体报道,英伟达的订单排到了 2024 年。其芯片的交付周期,也曾一度高达8~11 个月(如今已经缩短为3~4 个月)。马斯克曾为此吐槽,“英伟达的芯片比毒品还难搞到”。
产能不足,供不应求,这些需求应该自然溢出到其他厂商。从供应链安全的角度考虑,面对如此集中的市场,企业似乎也不应该只选择英伟达这一家的产品。
但全球的企业排着队将订单送到英伟达手中,难道,除了英伟达的芯片之外,AMD、英特尔这些企业的芯片都办法训练大模型吗?
答案当然不是,但使用英伟达的芯片,目前仍然是训练和运行大模型的最优选择。这种优势体现在四个方面,包括硬件性能、软件生态、适用范围和整体性价比。
首先是硬件性能。
以英伟达在 2020 年 5 月发布的 NVIDIA A100 GPU 为例,这款芯片采用 7nm 制程和 NVIDIA Ampere 架构,拥有 540 亿个晶体管和 6912 个 CUDA 核心,最高可以提供 80GB 的 GPU 显存,以及 2TB/s的全球超快显存带宽。在大模型训练和推理常用的 FP16(半精度浮点运算)Tensor Core 峰值性能可以达到 312TF,使用稀疏计算的情况下,可以达到 624TF。
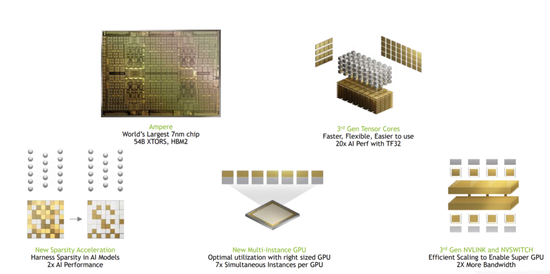
▲图源:CSDN,NVIDIA GPU A100 Ampere (安培)架构深度解析
很多人对这些指标没什么概念,我们来简单解释一下。
芯片的制程决定着同样大小的芯片能够放下的晶体管的数量,而晶体管的数量越多,芯片的计算能力越强,这也是 5 纳米的芯片一定比 7 纳米的芯片先进的原因。
至于 CUDA 核心,即 CUDA 线程,是英伟达 CUDA 平台编程模型中的基本执行单元。我们都知道,GPU 最强的能力是并行计算,而 CUDA 核心越多,意味着芯片能同时并行计算的数量也就越多,芯片的性能更强,完成同样任务的速度更快。
需要注意的是,芯片的计算能力强和计算效率高是两个概念。制程和晶体管的数量代表着计算能力,而 CUDA 核心的数量,代表着计算效率。
至于显存和带宽,则决定了 GPU 在运行时的效率。其中显存决定 GPU 同时能够存储的最大数据,而显存带宽,则决定显存和显卡之间的数据传输速度。
举一个简单直白的例子,在一个流水线上,原材料需要从库房运送到车间进行装备,然后将成品再运回库房。显存决定了库房能够放多少原材料,而显存带宽,则决定每次从库房送原材料的速度。如果库房不够大,或者材料传输速度不够快,那车间的生产能力再强,也无法生产出成品。所以显存和带宽,其实决定芯片能够参与训练多大参数规模的大模型,以及训练大模型的速度。
明白了这些基本概念,我们再用最有代表性的两家企业,进行对比。
首先是 AMD,目前主打的芯片是 MI250X,发布于 2021 年年底,采用 7nm 工艺,拥有 582 亿个晶体管,显存 128G,显存带宽 3.2768 TB/s,FP16 峰值性能为 369 TF,只有 60 个计算单元。

▲图源:AMD 官网,MI250X
其次是英特尔,目前主打芯片 Ponte Vecchio,同样发布于 2021 年,采用 7nm 工艺,宣称晶体管数量达到 1020 亿,是全世界晶体管数量最多的芯片。这款芯片显存 128GB,显存带宽 3.2TB/s,FP16 峰值性能 184TF,计算单元 102 个。

▲图源:英特尔 Hot Chips 演示的幻灯片,展示了 PVC 上的小芯片
我们会发现,即使从单纯的数据上看,英特尔和 AMD 也没有完全被英伟达甩开,甚至在某些领域,这两家的芯片还领先英伟达的 A100。
但是这里有两个误区,第一个误区是,英特尔和 AMD 这两款芯片的发布时间比 A100 都要晚一年,他们真正对标的对手,其实应该是英伟达在 2022 年初发布的 H100,而现在英伟达的芯片已经更新到 H200 了。
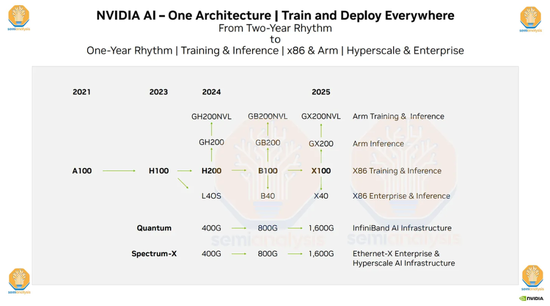
▲图源:Semianalysis
第二个误区在于,硬件指标并不完全等于芯片的整体能力,软件生态是决定芯片性能和使用的第二个关键指标。
这就像手机和操作系统一样,手机的硬件配置再好,没有一个好的操作系统,对于消费者来说仍然不是一款好的手机。而这里需要提到的,就包括英伟达的 CUDA 平台、NVLink 和 Tensor Core 等软件生态。
比如 CUDA 平台,我们前面提到的 CUDA 核心就是这个平台的产物,它可以提高芯片的并行计算能力;它可以通过编程,提高 GPU 的能效比,让同样的工作耗费更少的能源。
此外,CUDA 平台还支持广泛的应用程序,包括科学计算、深度学习、机器学习、图像处理、视频处理等等,它还允许技术人员通过 C++ 等常用的编程语言来编写 GPU 代码。打一个不恰当的比方,这相当于中国人不用学习英文,直接使用中文指挥外国人做事情,帮助技术人员节省了巨大成本。
但目前市面上大多数程序员已经深度依赖 CUDA 平台和开发工具,就像我们使用微信许多年了,你的朋友、聊天记录、朋友圈都在这个微信上,即使现在出现一个更好用的社交软件,你也很难迁移。
CUDA 带来的生态壁垒也类似这个道理,其他平台虽然也有自己的软件生态,比如 AMD 有自己的 GCN 架构,英特尔有 Xe 架构,甚至为开发者提供类似“一键换机”迁移功能,但都很难与英伟达竞争。
当然,这里面也有一些曲线救国的做法,比如以 AMD 为首,越来越多的芯片企业采用了“打不过就加入”的策略,选择将自己的芯片兼容到 CUDA 平台,早在 2012 年的时候,AMD 就与 Nvidia 达成了一项协议,允许 AMD 在其 GCN 架构 GPU 中使用 CUDA 技术,所以现在我们在 AMD 的芯片中,也会看到 CUDA 核心。
当然,对于英伟达来说,CUDA 也只是护城河的一部分,其他的技术如 NVLink 也至关重要。
作为大模型训练的 GPU,没有哪家企业会单独使用一张 GPU,每次都会使用至少几百张卡,甚至上万张卡一起建立计算集群。NVLink 是一种链接技术,可以实现 GPU 之间的高速、低延迟的互联。如果没有这种技术,整个芯片算力的集群就无法实现1+1>3 的效果,而且会增加 GPU 之间的通信延迟,执行任务的效率会降低,芯片的功耗会增加,最终增加整个系统的运行成本。
大模型训练实际上是一个非常消耗能源的事情,国盛证券做过一个计算,假设每天约有 1300 万独立访客使用 ChatGPT,那每天的电费就需要 5 万美元。而如果没有 NVLink,这笔成本还会指数级上升。
芯片某种程度上就像购车一样,购车只是第一次成本,之后的油费、保养、保险才是成本的大头。所以黄仁勋才说,“AI 系统最重要的不是硬件组成的成本,而是训练和运用 AI 的费用。”
所以,虽然 AMD、英特尔在某些芯片上把价格定得比英伟达更低,但是从长期成本来考虑,具有更优软件生态和协同、配套工具的英伟达芯片仍然是性价比最高的选择。
当然,这里面还要考虑到使用场景的问题。
比如英伟达的大客户,主要是以 Meta、微软、亚马逊、Google 为代表的云计算平台。有媒体报道,头部云计算厂商在英伟达 H100 GPU 整体市场份额中的占比达到 50%。
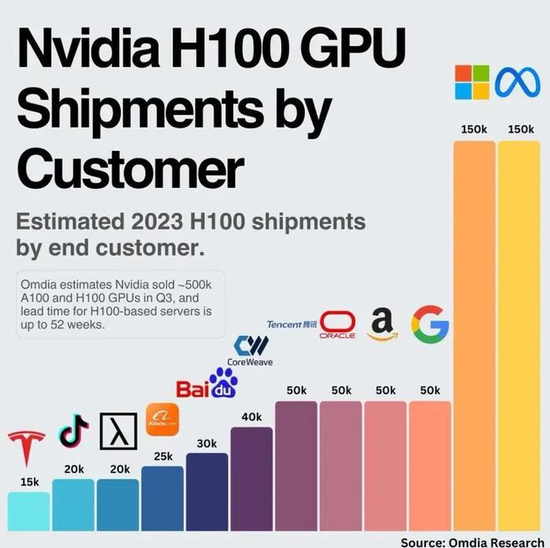
▲图源:Omida Research
而云厂商采购芯片的逻辑,主要是构建算力集群,然后通过云服务平台将这些算力再卖出去。但这里就会存在一个问题,就是云厂商并不知道客户会拿这些算力来做些什么,比如有的企业会用来做机器学习,有企业需要大模型训练,也有企业需要做大模型推理。
不同的需求,背后对应的算力配置也不尽相同,它需要底层的芯片能够支持多种编程模型,支持多种数据类型,有较好的可拓展性和良好的性能和功耗等等。而这些,恰恰是英伟达硬件能力加软件生态带来的优势。
综合来看,无论是从硬件性能,还是软件生态;无论是从开发工具和部署工具,到长期使用的成本和可开发应用场景。对比同类竞争对手,英伟达都属于最有性价比,且遥遥领先的存在。
这就是为什么明明需要排着长队、忍受长时间等待,大家却仍然执着于英伟达芯片的原因。
02
谁想替代英伟达?
难道英伟达真的不能被超越吗?当然也不是,在巨大的市场利益面前,从传统半导体巨头到初创企业,围剿英伟达的呼声从来就没有停止过。
特别是最近几年,随着云计算和云端 AI 芯片的火爆,已经有无数的半导体公司说过,自家芯片已经在部分性能上超过了英伟达 A100,就像今天也有无数大模型企业会说自己已经在某些方面超过 OpenAI GPT-3.5 一样。
在最新披露年报中,英伟达是这样描述自己的竞争风险的。
公司的竞争来源主要有两个,一个是 GPU、CPU、DPU、嵌入式 SoC 和其他加速 AI 计算处理器产品的公司,比如英特尔、AMD、高通、华为;另一个是提供基于 InfiniBand(无线带宽技术)、以太网、光纤通道和专有技术的半导体高性能互连产品供应商,比如华为、思科、惠普这样的通信公司,以及亚马逊、微软、阿里、谷歌、华为这样的云服务公司等等。
特别是第一次被英伟达列为对手且被反复提到的华为。从芯片硬件到软件,从云服务到通信解决方案,英伟达几乎将华为当做所有领域的竞争对手。
奇怪的是,虽然在 2023 年 8 月,科大讯飞创始人刘庆峰就提到华为的 GPU 已经可以对标 A100 了,但其实从客观的性能、使用成本,软硬件生态工具,华为与英伟达之间仍然有着代际的差距。
华为被如此重视,关键在于两点:
一是市场环境的问题,由于众所周知的原因,英伟达的高端芯片在国内的销路并不畅通,在全面国产替代的背景下,其针对中国的特供版芯片在中国的竞争力也在降低。在这样的背景下,华为拥有更多的成长空间,不必直接对标英伟达最先进的 H200。
另一个关键是华为的生态能力非常齐全,作为通信起家的企业,华为不仅拥有自己的芯片,服务器,还拥有自己的云计算平台和大模型。基本上,华为覆盖了 AI 这条产业链从头到尾的所有环节,对比英伟达拥有更大的潜力和可能。
如今,华为的昇腾 910B 正在疯狂席卷中国市场,除了科大讯飞之外,国内多地的智算中心也都已经用上了华为的芯片。《财经》之前报道,华为昇腾系列产品目前处在供不应求状态,价格约只有英伟达 A100 的 60% 甚至可以更低。
为了应对国内市场的变化,英伟达也在积极推出新的产品。2 月初,有媒体报道,英伟达的新款国内专供芯片 H20 已经开始在接受经销商的预定。
▲图源:NVIDIA 由 H2O.ai 和 NVIDIA 提供支持的融合 AI 生态系统
而有趣的是,作为新产品,英伟达 H20 每张的定价换算成人民币仅在 8.6 万~11 万左右,刚好略低于华为昇腾 910B 12 万元左右的价格。在英伟达承受中国市场压力的背景下,这被看做是一种防守策略。
除了在国内有被黄仁勋亲自认证的竞争对手华为之外,海外市场英伟达其实也是群狼环伺。
最虎视眈眈的自然是 AMD。
2023 年 6 月,AMD 发布了 Instinct MI300,目标是对标英伟达 H100,其晶体管数量达到 1530 亿,内存 192GB、内存带宽 5.3TB/s,分别是英伟达 H100 的大约 2 倍、2.4 倍和 1.6 倍。
软件上,AMD 仍然延续兼容 CUDA 的策略,一方面通过迁移工具,翻译 CUDA 应用的策略吸引英伟达的开发者,另一方面开源自家的 ROCm 软件,提高企业和开发者的自主权。
对于芯片算力这么基础的部分,没有企业希望英伟达成为自己的唯一供应商,所以在 MI300 推出之后,包括 OpenAI、微软、Meta 都纷纷表态将采购 MI300。
除了 AMD,即使是已经在 AI 上落后的英特尔,也不甘心错过这场泼天富贵。

▲图源:彭博社英特尔公司首席执行官 Patrick Gelsinger 于 2023 年 12 月 14 日星期四在美国纽约举行的英特尔 AI Everywhere 发布会上发表讲话
英特尔最新的 AI 芯片 Gaudi3 将在 2024 年上市,这款芯片采用 5nm 工艺,最高配备 128GB 的内存。按英特尔的宣传,这款芯片的带宽是 Gaudi 2(7nm 工艺)的 1.5 倍,BF16 功率是其 4 倍,网络算力是其 2 倍,并表示 Gaudi3 的性能将优于英伟达的 H100。同时,美国政府也在对英特尔进行扶持,预计将向英特尔提供超过 100 亿美元的补贴。
从战略上,与英伟达的优势在云端不同,英特尔的优势在与其广阔个人终端市场。所以英特尔其实将更大的赌注压在了个人终端的 AI 化上。英特尔 CEO 基辛格多次提到,要重构 PC 体验,并表达对未来 AI PC 市场的看好。英特尔希望依靠其 CPU 在个人 PC 上的优势,率先抢占这一市场,然后再通过消费市场反向促进云端市场的繁荣,打一波农村包围城市的战役。
事实上,芯片的行业特点与软件、或者互联网的商业可以通过建立用户规模,或者生态就建立壁垒实现赢者通吃不同。作为高度技术密集型产业,芯片技术的代际变化非常大,只要存在技术迭代的机会,后来者就永远有弯道超车的可能。
芯片不同于软件,或者互联网等其他业务模式,建立起一定的用户规模之后可以一直赢者通吃。只要存在技术迭代的机会,后来者就永远有弯道超车的可能。
而无论是 AMD 还是英特尔,亦或者华为,他们都有深厚的技术研发能力和充裕的资金,这些企业可能会在这个阶段暂时落后,但也谁无法笃定,这些企业不会出现一次技术涌现,或者抓住某个技术迭代的关键时期后来居上。
从最新财报看,AMD 2023 年 Q4 数据中心的销售额 22.8 亿美元,同比增长 38%,表明市场已经在逐步接纳其 AI 芯片的使用。
而除了 AMD 和英特尔这样的老牌玩家之外,这个市场上还有很多创业者在前赴后继。
最近比较出名的如 Groq,其针对大语言模型量身定制的 LPU 芯片每秒可以生成 500 个 token,远超英伟达芯片的效率。当然,这个成绩仍然是在实验场景下的结果,最终工程化交付还有很长的距离,且这款芯片也还有许多技术问题有待解决。
但这本质上代表,面对新的场景,如今的芯片的技术仍有创新空间。
所以我们会看到,作为全球最具代表的 AI 企业,OpenAI 也宣布了自己的造芯计划。其创始人 CEO Altman 前段时间不仅传出 7 万亿美元的募资芯片,在这之前更是已经投资了包括 Cerebras、Rain Neuromorphics 和 Atomic Semi 在内的至少三家芯片公司。
远在日本的孙正义,在互联网时代已经功成名就的他也打算放过这次机会,刚刚从巨额的投资亏损中解套的他,立马就提出了募集 1000 亿美元以创立一家人工智能半导体芯片企业的计划。
有媒体报道,在这次计划中,软银将出资 300 亿美元资金,另有 700 亿美元的资金可能来自中东地区的机构。而在 2023 年,软银集团曾以 640 亿美元的估值收购 ARM 公司 25% 股份,这也是孙正义投入芯片的底气之一。
当然,对于英伟达来说,更大或者更直接的危险还是来自其最大的客户——云厂商。
面对巨大的算力需求,国内如百度、华为、阿里都相继推出了自己的 AI 芯片,在国外,包括微软、亚马逊、Google 也同样在开发自己芯片。
当然,这些芯片主要针对的是特定场景的计算需求,与英伟达面向通用场景的 GPT 仍然有不同。但这也代表,云计算厂商正在逐步减少对英伟达的依赖。而正如前面所提到的,这部分企业才是真正支撑英伟达业绩的主要客户。
面对这些既定的,或者潜在的市场变化,英伟达自然也没闲着。据路透社报道,英伟达近期已与微软等主要云厂商联系,商讨为云厂商定制 AI 芯片的问题。
同时,英伟达也在持续推出新的芯片,以期望不断拉开与后来者的距离。目前,英伟达已经公布了其下一代 AI 芯片 B100 的消息,设计性能要比 H100 快 3 倍。
所以,虽然超越英伟达的机会仍然存在,这个世界也从不缺少挑战“霸权”的勇士,但这个任务显然还很漫长。






