金磊发自凹非寺
量子位公众号 QbitAI
现在,大语言模型(LLM)迎来了“1-bit 时代”。
这就是由微软和中国科学院大学在最新一项研究中所提出的结论——
所有的 LLM,都将是 1.58 bit 的。

具体而言,这项研究提出的方法叫做BitNet b1.58,可以说是从大语言模型“根儿”上的参数下手。
将传统以 16 位浮点数(如 FP16 或 BF16)形式的存储,统统变成了三进制,也就是 {-1, 0, 1}。
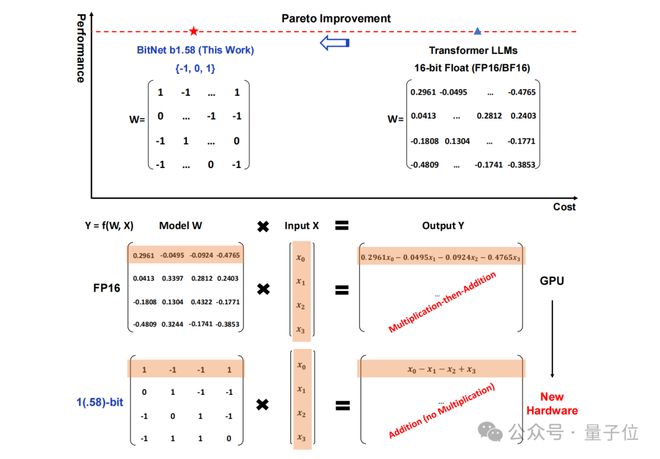
值得注意的是,这里的“1.58 bit”并不是指每个参数占用 1.58 字节的存储空间,而是指每个参数可以用 1.58 位的信息来表示。
在如此转换之后,矩阵中的计算就只会涉及到整数的加法,因此会让大模型在保持一定精度的同时,显著减少所需的存储空间和计算资源。
例如 BitNet b1.58 在 3B 模型大小时与 Llama 做比较,速度提高了 2.71 倍的同时,GPU 内存使用几乎仅是原先的四分之一。
而且当模型的规模越大时(例如 70B),速度上的提升和内存上的节省就会更加显著!
这种颠覆传统的思路着实是让网友们眼前一亮,论文在X上也是受到了高度的关注:
网友们惊叹“改变游戏规则”的同时,还玩起了谷歌 attention 论文的老梗:
1 bit is all YOU need.
那么 BitNet b1.58 具体又是如何实现的?我们继续往下看。
把参数变成三进制
这项研究实则是原班人马在此前发表的一篇论文基础之上做的优化,即在原始 BitNet 的基础上增加了一个额外的 0 值。

整体来看,BitNet b1.58 依旧是基于 BitNet 架构(一种 Transformer),用 BitLinear 替换了 nn.Linear。
至于细节上的优化,首先就是我们刚才提到的“加个0”,即权重量化(weight quantization)。
BitNet b1.58 模型的权重被量化为三元值{-1, 0, 1},这相当于在二进制系统中使用了 1.58 bit 来表示每个权重。这种量化方法减少了模型的内存占用,并简化了计算过程。

其次,在量化函数设计方面,为了将权重限制在-1、0 或 +1 之间,研究者们采用了一种称为 absmean 的量化函数。
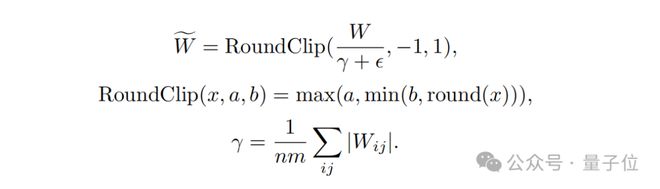
这个函数先会根据权重矩阵的平均绝对值进行缩放,然后将每个值四舍五入到最接近的整数(-1, 0, +1)。
接下来就到了激活量化(activation quantization)这一步。
激活值的量化与 BitNet 中的实现相同,但在非线性函数之前不将激活值缩放到[0, Qb]的范围内。相反,激活值被缩放到[−Qb, Qb]的范围,以此来消除零点量化。
值得一提的是,研究团队为了 BitNet b1.58 与开源社区兼容,采用了 LLaMA 模型的组件,如 RMSNorm、SwiGLU 等,使得它可以轻松集成到主流开源软件中。
最后,在实验的性能比较上,团队将 BitNet b1.58 与 FP16 LLaMA LLM 在不同大小的模型上进行了比较。
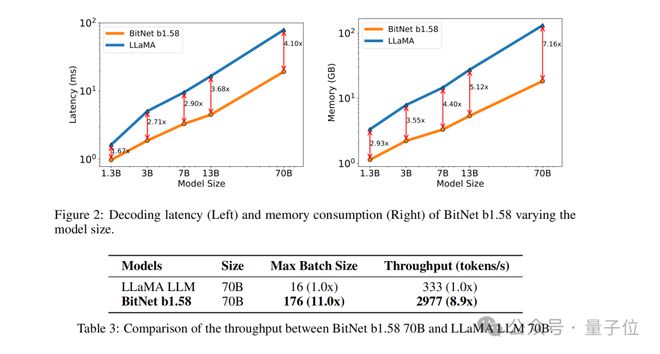
结果显示,BitNet b1.58 在 3B 模型大小时开始与全精度 LLaMA LLM 在困惑度上匹配,同时在延迟、内存使用和吞吐量方面有显著提升。
而且当模型规模越大时,这种性能上提升就会越发显著。
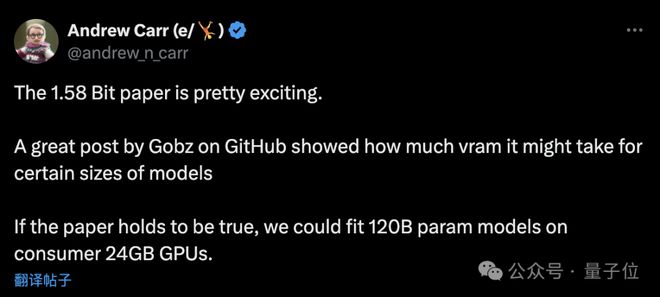
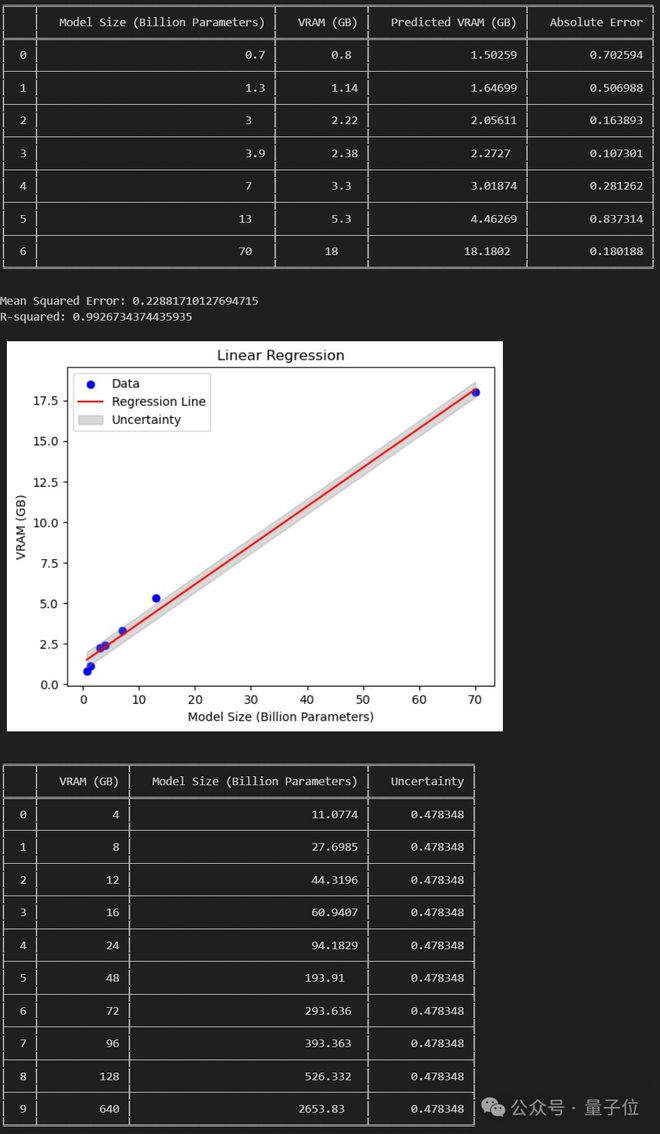
网友:能在消费级 GPU 跑 120B 大模型了
正如上文所言,这篇研究独特的方法在网上引发了不小的热议。
DeepLearning.scala 作者杨博表示:
BitNet b1.58 相比原版 BitNet,最大的特点就是允许 0 参数。我觉得稍微修改一下量化函数,也许可以控制 0 参数的比例。当 0 参数的比例很大时,可以用稀疏格式存储权重,使得平均每个参数的显存占用甚至低于 1 比特。这就相当于权重级别的 MoE 了。我觉得比一般的 MoE 更优雅。
与此同时,他也提出了关于 BitNet 的缺点:
BitNet 最大的缺点在于虽然能减少推理时的显存开销,但优化器状态和梯度仍然要用浮点数,训练仍然很费显存。我觉得如果能把 BitNet 和训练时节省显存的技术结合起来,那么相比传统半精度网络,同等算力和显存下支持更多参数,优势就很大了。目前能节省优化器状态的显存开销的办法是 offloading。能节省梯度的显存占用的办法可能是 ReLoRA。但是 ReLoRA 的论文实验只用了十亿参数的模型,并没有证据表明能不能推广到百亿、千亿参数的模型。

△图源:知乎,经授权引用
不过也有网友分析认为:
若论文成立,那么我们就能在 24GB 消费级 GPU 上跑 120B 的大模型了。
那么你觉得这种新方法如何呢?
参考链接:
[1]https://arxiv.org/abs/2402.17764
[2]https://twitter.com/_akhaliq/status/1762729757454618720
[3]https://www.zhihu.com/question/646359036/answer/3413044355






