
新智元报道
编辑:编辑部
线性 RNN 赢了?近日,谷歌 DeepMind 一口气推出两大新架构,在d基准测试中超越了 Transformer。新架构不仅保证了高效的训练和推理速度,并且成功扩展到了 14B。
Transformer 又又又被挑战了!
这次的挑战者来自大名鼎鼎的谷歌 DeepMind,并且一口气推出了两种新架构,——Hawk 和 Griffin。

论文地址:https://arxiv.org/abs/2402.19427
这种将门控线性 RNN 与局部注意力混合在一起的模型新架构的表现相当亮眼。
首先,同为线性 RNN 架构的 Griffin,凭借着1/2 的训练数据,在所有评测中全面优于之前大火的 Mamba。
更重要的是,Griffin 将模型成功扩展到了 14B,做到了 Mamba 想做却没能做的事。
其次,面对基于 Transformer 架构的模型,Griffin 则凭借着1/6 的训练数据,打平甚至超越了同等参数量的 Llama 2!
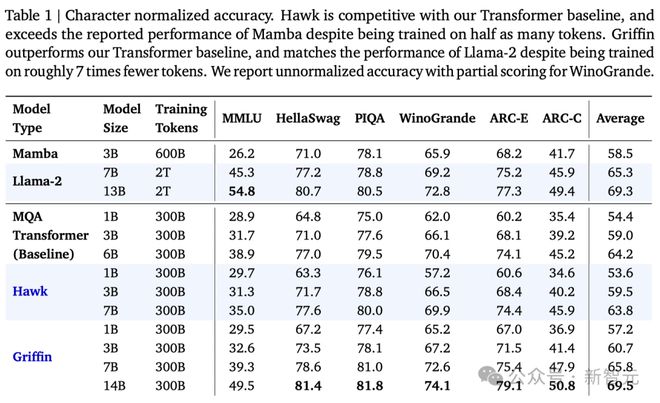
同时,模型能够利用很长的上下文来改进其预测,表明线性 RNN 的外推能力可以远远超出它们训练的序列长度。
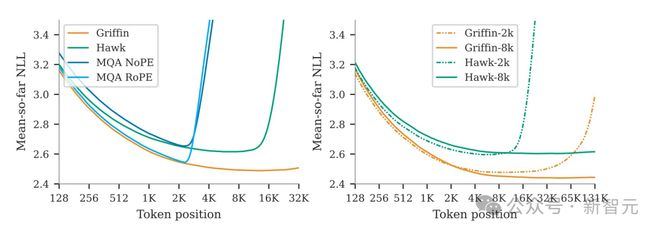
此外,团队还证明了这种组合构架保留了 Transformer 在合成任务上的许多功能,例如从长上下文中复制和检索 token。
文章共同一作兴奋地发推表示,Griffin 这种新的模型构架效率非常高——它集合了线性 RNN 的所有的效率优势和 Transformer 的表现力(expressiveness)和规模化的优势。

推上给的配图也很有趣,还记得之前 Mamba 配图用自己的蟒蛇挑战变形金刚吗?这次 Griffin(狮鹫)直接霸气占据C位,在赛道上领先。
小编莫名觉得 Griffin 对 Mamba 的伤害比较大,毕竟老鹰抓蛇......
不过这只是玩笑,因为我们可以发现 Mamba 的作者 Albert Gu 也在这篇文章的作者之中——所以有可能天下的线性 RNN 都是一家人。
说回正题,虽然现在 Transformer 称霸江湖,但它平方级别的计算和存储开销对科研和工业界都造成了很大的压力(尽管喂饱了老黄......)。
大家在拼命做优化(比如 Mamba 另一位作者 Tri Dao 开发的 FlashAttention 系列)之余,也想另辟蹊径,于是就诞生了这些挑战 Transformer 的架构。
——如果真成了,就能跟「Attention Is All You Need」一样名留青史。
最近大火的几个著名研究都与线性 RNN 相关,比如 RWKV、Mamba,以及我们今天的 Hawk 和 Griffin。
循环神经网络(RNN)在处理长序列数据时表现出色,因为它的推理开销是线性的,相比于 Transformer 有天然的计算和存储优势。
不过 RNN 系列在记忆和选择性提取信息方面相对于 Transformer 又有着原理上的劣势,所以在当前的这些任务上表现力不行。
另外,由于结构问题,训练大规模的 RNN 是非常困难的。
为此,研究人员提出了 Hawk,一种采用了门控线性循环的 RNN;以及 Griffin,一个将门控线性反馈与局部注意力机制相结合的混合模型。
首先,研究人员提出了 RG-LRU 层,这是一个新颖的门控线性循环层,并围绕它设计了一个新的循环块来替代 MQA。
接着研究人员以这个循环块为基础,构建了两个新模型:Hawk(将 MLP 与循环块混合使用),以及 Griffin(将 MLP 与循环块和局部注意力混合使用)。
具体来说:
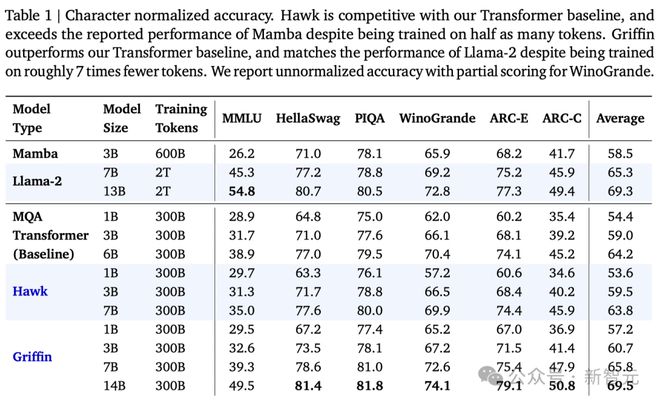
1. Hawk 和 Griffin 模型在训练 FLOPs 和保留损失方面,展现出了与 Transformer 模型类似的幂律缩放关系,即使参数量达到 7B 以上也是如此(图1(a))。
2. 在所有模型规模上,Griffin 的保留损失略低于强大的 Transformer 基线。
3. 对 Hawk 和 Griffin 模型在不同规模下使用 300B token 进行了过训练。在一系列下游任务中,Hawk 的表现超越了 2 倍 token 训练的 Mamba 模型,而 Griffin 则可以和 6 倍 token 训练的 Llama-2 相媲美。
4. 在 TPU-v3 上,Hawk 和 Griffin 达到了与 Transformers 相当的训练效率。通过在 Pallas 中设计的 RG-LRU 层内核,研究人员在最大限度地减少内存传输的同时,克服了由于对角线 RNN 层的内存限制带来的挑战。
5. 在推理阶段,Hawk 和 Griffin 的吞吐量显著高于 MQA Transformers(图1(b)),并且在处理长序列时延迟更低。
6. Griffin 在处理训练期间未见过的更长序列时,表现优于 Transformers,同时还能高效地从训练数据中学习复制和检索任务。然而,如果不进行微调,直接使用预训练模型进行复制和精确检索任务的评估,Hawk 和 Griffin 的表现则不如 Transformers。
模型架构
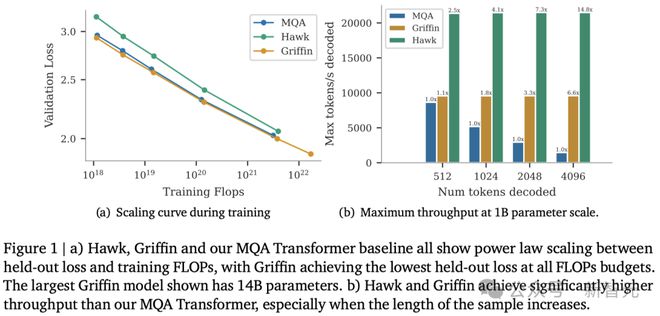
所有的模型都包含以下三大核心部分:(1) 一个残差块,(2) 一个 MLP 块,以及 (3) 一个时间混合块。
残差块和 MLP 块在所有模型中保持不变,而时间混合块则有三种不同的实现方式:
1. 全局多查询注意力(MQA);
2. 局部(滑动窗口)MQA;
3. 研究人员提出的循环块。
在循环块中,研究人员受线性循环单元的启发,提出了一种新型的循环层——真实门控线性循环单元(RG-LRU)。
如图2(a)所示,模型的全局结构由残差块定义,其设计灵感来源于预归一化的 Transformers 架构。
首先将输入序列进行嵌入处理,然后让它通过个这样的残差块(这里的代表模型的深度),接着应用 RMSNorm 生成最终激活。
为了计算 token 的概率,研究人员在最后加入了一个线性层和一个 softmax 函数。值得一提的是,这个线性层的权重是与输入嵌入层共享的。
像 Transformer 一样高效扩展
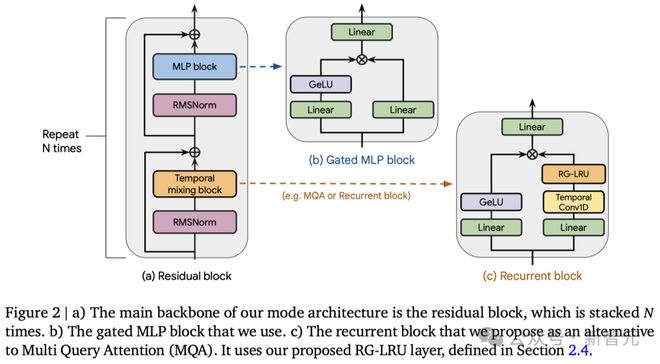
缩放研究评估了三种不同的模型,并展示了它们在参数量达到并超过 7B 时的性能表现。
1. MQA Transformer 基准模型
使用了残差模式和门控 MLP 块,并结合了 MQA 和 RoPE 技术。
2. Hawk 模型
Hawk 遵循了与 MQA Transformer 相同的残差模式和 MLP 块设计,但在时间混合部分采用了一种新的循环块(包含 RG-LRU 层),而不是 MQA。通过将循环块的宽度扩大约约3/4,其参数量也达到了与多头注意力块大致相当的水平,从而可以匹配模型维度的设置。
3. Griffin 模型
Griffin 的一个显著优点是,相比于全局注意力机制,它通过固定的状态大小来总结序列,而不是像 MQA 那样让 KV 缓存随着序列长度的增加而线性增长。由于局部注意力具有相同的特性,因此将循环块与局部注意力相结合,可以保持这一优点。结果显示,这种组合非常有效,因为局部注意力能够精准模拟近期的信息,而循环层则能够在长序列中传递信息。
Griffin 使用了与 Transformer 基线相同的残差模式和 MLP 块,但与上述两种模型不同的是,它采用了循环块和 MQA 块的混合。具体而言,研究人员设计了一种分层结构——先交替使用两个残差块和一个循环块,然后再使用一个基于局部注意力机制的残差块。通常,局部注意力的窗口大小为 1024 个 token。
大规模并行训练
随着模型大小的增加,我们无法在训练期间将模型安装在单个设备上,即使每个设备的批大小为1。
因此,在训练期间,作者使用模型并行性跨设备对大型模型进行分片。由于不同训练设备之间的通信成本很高,因此有效地对模型进行分片对于大规模快速训练至关重要。
对于 gated-MLP,这里使用 Megatron 式的分片(即张量并行),这需要在前向和后向传递中执行 all-reduce 操作。相同的策略也可以应用于注意力块中的线性层,将多头分配给不同的设备。
循环块包含每个分支的两个线性层。所以也可以高效地应用 Megatron 的分片方式。而 Conv1D 层跨通道独立运行,可以在设备之间拆分其参数,并不会产生任何通信开销。
为了避免额外的跨设备通信,研究人员对 RG-LRU 中的 gate 使用 block-diagonal weights(下面的公式 1 和2),而不是密集矩阵。

对于本文中的所有实验,作者使用 16 个块作为 recurrence gate 和 input gate。recurrence 的对角线结构具有与 Conv1D 相同的优势,允许在没有任何通信的情况下进行参数分片和计算。使用这种策略,循环区块的通信要求与 MLP 区块的通信要求相同。
另外优化器(比如 Adam)的状态参数可能会消耗大量内存,超过模型参数本身的大小。
为了解决这个问题,研究人员采用了 ZeRO,还使用 bfloat16 表示模型参数和激活,从而最大限度地减少任何数据传输开销。
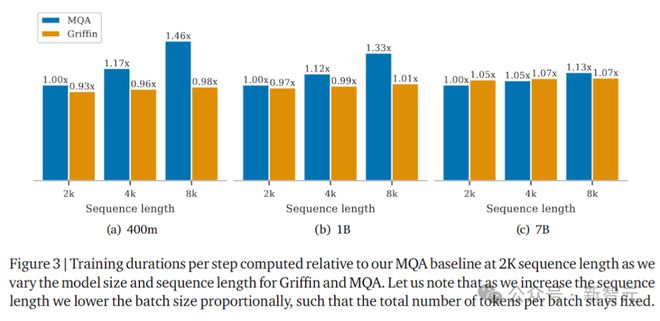
上图以 2K 序列长度的 MQA 作为基线,显示了 Griffin 和 MQA 的训练耗时,这里测试了不同的模型大小和序列长度。
随着序列长度的增加,实验中会按比例降低批大小,以便每个批的 token 总数保持不变。
为什么不使用卷积或者关联扫描?
线性 RNN 模型的优势之一是高并行化,源于它计算的关联性,可以通过卷积或前缀和算法(关联扫描)在设备上高效执行。
然而,RG-LRU 的门控机制与卷积视图不兼容。虽然原则上仍然可以使用关联扫描减少所需的 FLOP 数,但不会减少内存开销,这是在实践中的主要瓶颈。
根据经验,在 TPU-v3 上,关联扫描明显慢于原生 Jax 线性扫描。作者推测,并行前缀-求和算法的树重组的随机访问性质不太适合 TPU 架构,导致内存传输速度更慢。
推理速度
在评估推理速度时,需要考虑两个主要指标。
第一个是延迟,它衡量在特定批大小下生成指定数量的 token 所花费的时间。第二个是吞吐量,衡量采样指定数量的 token 时,每秒可以在单个设备上生成的最大 token 数。
由于吞吐量与 token 采样、批大小以及延迟有关,因此可以通过减少延迟或减少内存使用量来提高吞吐量,从而允许在设备上使用更大的批大小。
对于需要快速响应时间的实时应用程序,可以考虑延迟。而在考虑其他语言应用程序时,吞吐量很重要,例如人类反馈强化学习(RLHF)或评分语言模型输出。
这里测试了大小为 1B 参数的模型的推理结果,基线为 MQA(Transformer)。MQA 在推理过程中比文献中经常使用的标准 MHA 要快得多。
参与比较的模型是:MQA Transformer,Hawk,和 Griffin。
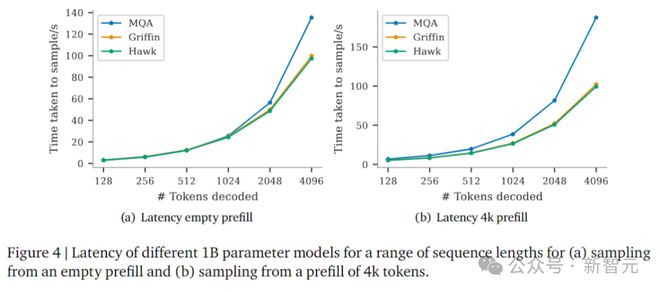
图 4 比较了批大小为 16 的模型的延迟,预填充为空,或 4096 个 token。对于长序列,Hawk 和 Griffin 的采样延迟比 MQA Transformer 更快。
当序列长度和预填充长度(影响 KV 缓存的大小)增加时,这一点尤其明显。Griffin 实现了与 Hawk 相似的延迟,展示了线性 RNN 和局部注意力的出色兼容性。
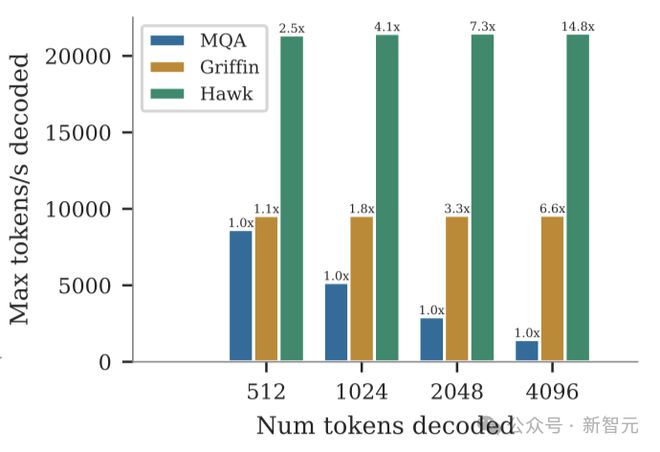
随后,研究人员比较了相同模型在空提示下对 512、1024、2048 和 4196 个 token 进行采样时的最大吞吐量(token/秒)。
如上图所示,我们可以看到 Griffin 和 Hawk 的吞吐量都明显高于 MQA Transformer 基线。
这在一定程度上是由于重复模型具有较低的延迟,但也主要是因为 Griffin 和 Hawk 可以在单个设备上容纳比 MQA Transformer 更大的批大小,因为它们的缓存更小。
Hawk 实现了比 Griffin 更高的吞吐量,因为当批大小较大时,本地注意力缓存的大小最终会与参数的大小相当。
网友评论
虽然论文的效果显著,但也有网友并不买账,质疑本文的模型与 Mamba 的比较并不「公平」:

「这篇论文说明了 LLM 研究中的一个巨大问题。他们声称在更少的 token 上表现优于 Mamba。然而,直到第 3.2 节,他们才承认使用了与 Mamba 完全不同的数据集进行训练。」
「由于数据实际上是最重要的东西,因此性能的比较是没有用的。完全没用。无法获得任何科学结论或见解......」
还有通过阴谋论推导出模型不行的:

「DeepMind 有什么动机来发表这样的研究?如果他们想要在与 OpenAI 的竞争中占据优势,那么如果他们发现一些很棒的新架构,他们会将其保密。」
「这是否意味着这些结果现在是好的,但还不够好,不足以在提供竞争优势方面具有革命性?」
大浪淘沙,结果如何,让我们期待时间的检验。
作者介绍
Albert Gu

Albert Gu 也是之前爆火的 Mamba 架构的作者

2015 年,Albert Gu 在卡内基梅隆大学(CMU)取得了计算机科学和数学双学士学位。
随后就读于斯坦福大学,专业是计算机科学,目前在 CMU 担任 Assistant Professor。
2011Albert Gu 曾在 Facebook 做过软件工程实习生,2015 年又在英国伦敦的 Jump Trading 做算法交易实习生。
2019 年,Albert Gu 到 DeepMind 实习,作为研究科学家实习生。
他的研究方向包括:
用于机器学习的结构化表示,包括结构化线性; 代数和嵌入,序列模型的分析和设计; 关于长上下文,非欧几里得表示学习。
Albert Gu 近年来在 ICML、ICLR、NeurlPS 等 AI 顶级会议上发表了多篇高被引文章:
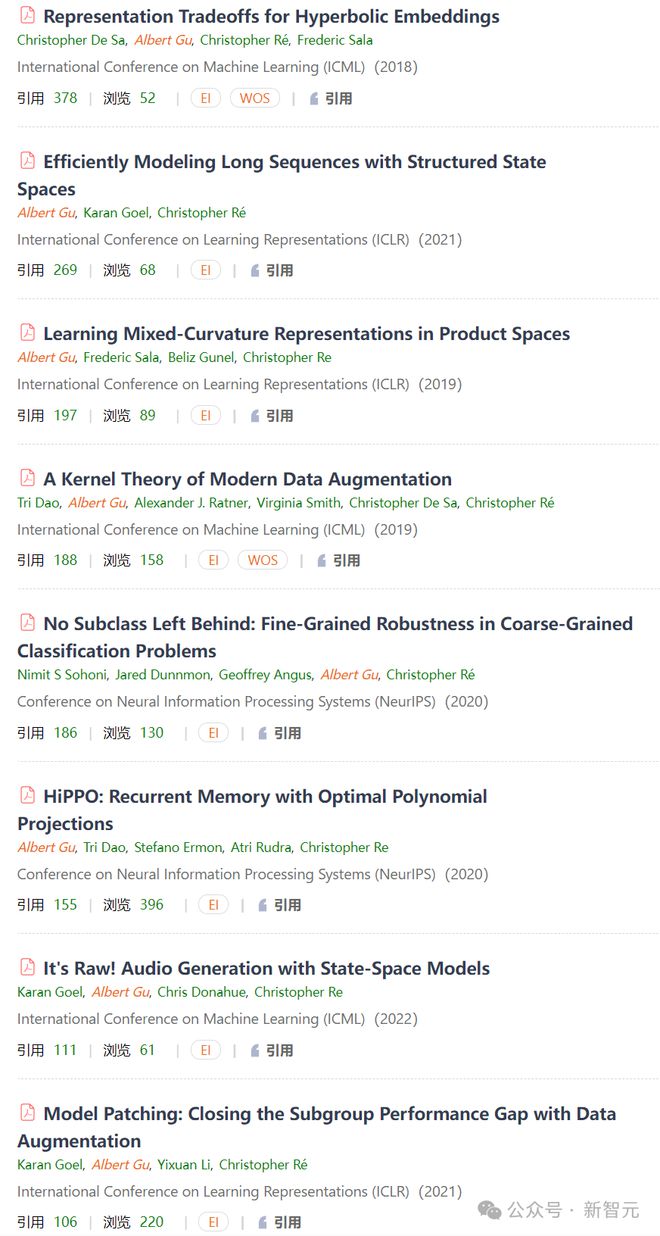
Soham De

论文共一 Soham De 是谷歌 DeepMind 的研究科学家,工作重点是深入理解并提升大规模深度学习的性能。
此前,他于 2018 年在美国马里兰大学取得博士学位,导师是 Dana Nau 教授和 Tom Goldstein 教授,期间主要研究用于机器学习问题的快速随机优化算法。
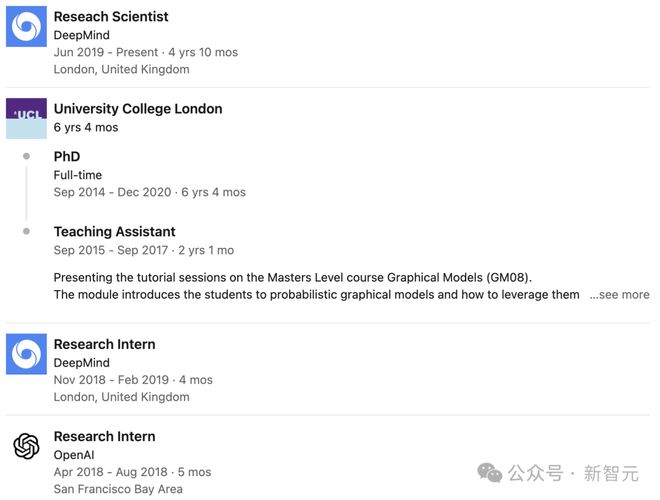
Samuel L. Smith

论文共一 Samuel 在剑桥大学一路本硕博,2016 年获得理论物理学博士学位,随后在谷歌大脑和 DeepMind 工作。
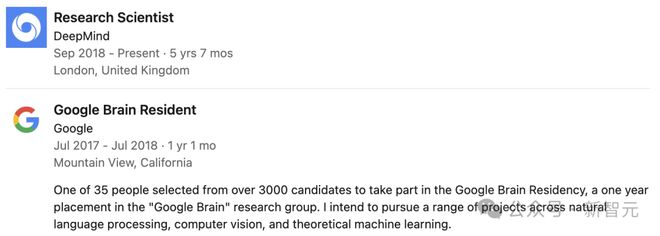

George-Cristian Muraru

论文共一 George-Cristian Muraru 也是谷歌 DeepMind 的软件工程师,在谷歌的工作之前,他曾在彭博干过程序员。
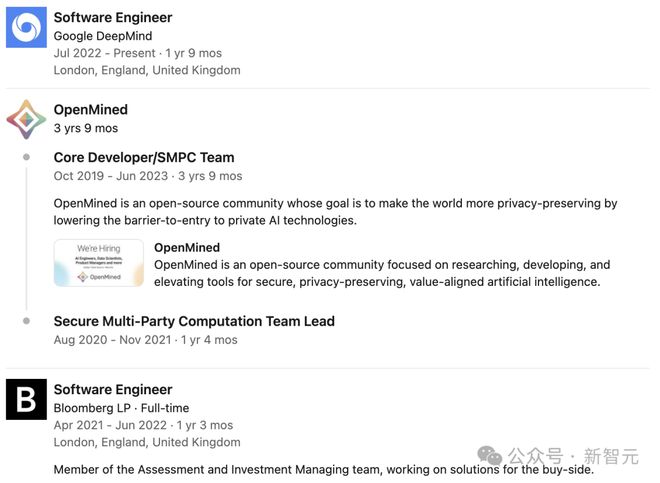
Aleksandar Botev

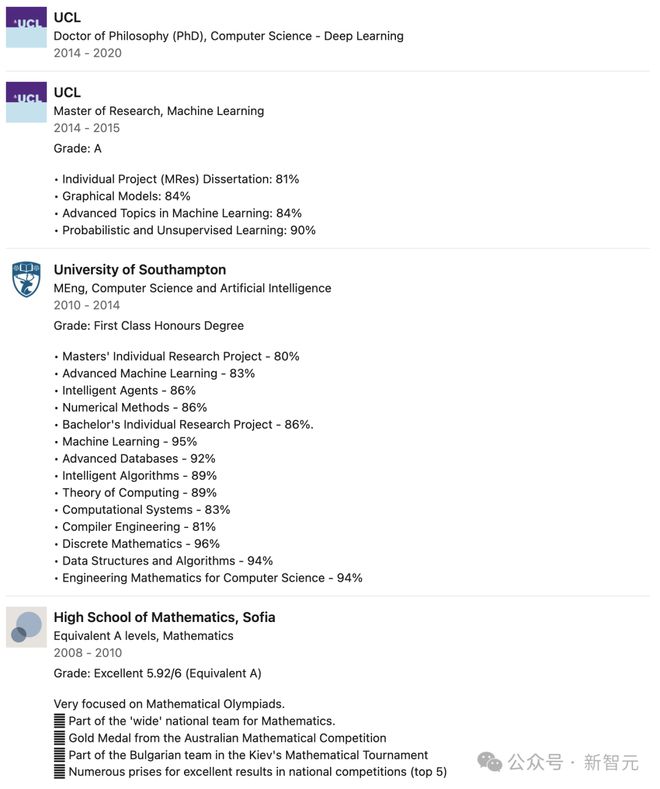
论文共一 Aleksandar Botev 毕业于英国伦敦大学学院,获得机器学习硕士学位,深度学习博士学位,曾在 OpenAI 和谷歌 DeepMind 实习,于 2019 年加入 DeepMind,担任 Reseach Scientist。
参考资料:






