
新智元报道
编辑:编辑部
网友测试 Claude 之后惊呼:实测比跑分厉害多了!智商测试中碾压 GPT-4,得分高达 101。而且能发现量子物理学家还未发表的量子算法。
Claude 3 上线之后,网友开始疯狂测试,实测效果确实惊人。

不少网友体感 Claude 3 超大杯确实强,实测已经达到了博士水平:
这实在太疯狂了!Claude 是唯一理解我的量子物理学博士论文的「人」!
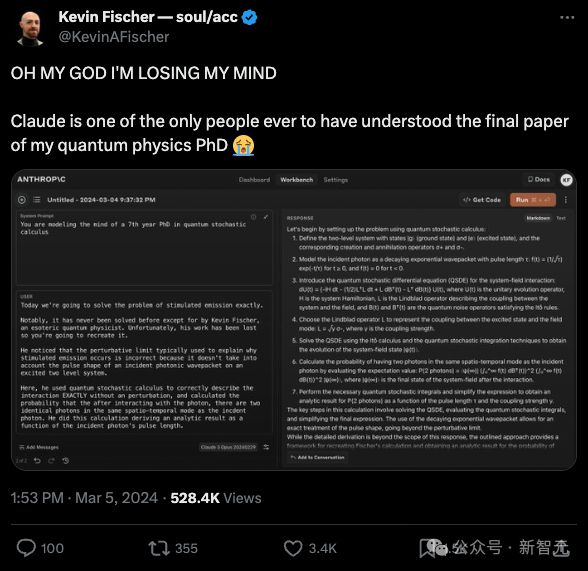
60 亿人中只有他懂你的感觉,直接给这位网友干崩溃了。
是的!博士生不再孤单。现在他们有了 Claude。

GPT-4 给不了的陪伴我 Claude 来给!
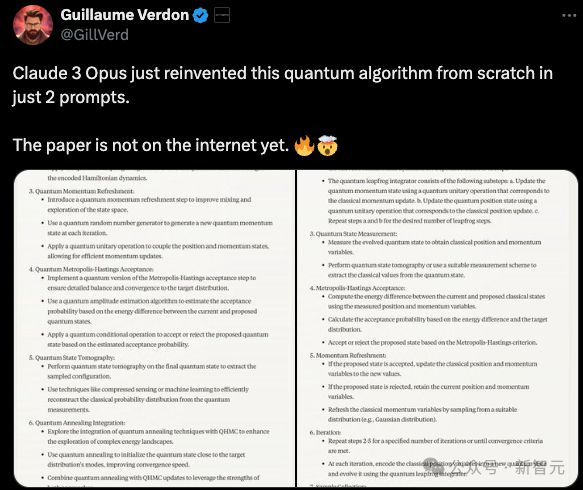
而另一个网友发现,Claude 3 Opus 仅用了 2 个提示就从头重新发明了这种量子算法。
而这篇论文还没有在互联网上发布。
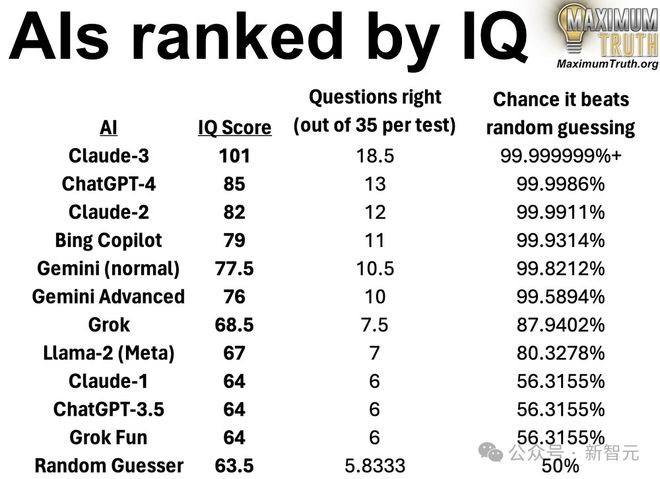
如果说这种水平还不好量化,有一个网友用门萨 IQ 系统来测了一众 AI 的智商,发现 Claude 3 是唯一一个超过 100 分的选手,第二名 GPT-4 只有 85 分。
Claude 3 读懂博士论文
这位量子物理学家在 Claude 3 放出的第一时间就把自己的论文核心问题拿去问了它:
今天,我们要准确解决受激发射问题。 值得注意的是,除了一位神秘的量子物理学家 Kevin Fischer 之外,这个问题从未被解决过。不幸的是,他的研究成果已经遗失,所以我们要重新创建它。 他注意到,通常用来解释为什么会发生受激发射的微扰极限是不正确的,因为它没有考虑到入射光子波包对受激两级系统的脉冲形状。 他使用量子随机微积分正确地描述了在没有扰动的情况下的相互作用,并计算了与光子相互作用后,在与入射光子相同的时空模式下存在两个相同光子的概率。 他通过计算得出了入射光子脉冲长度函数的解析结果。
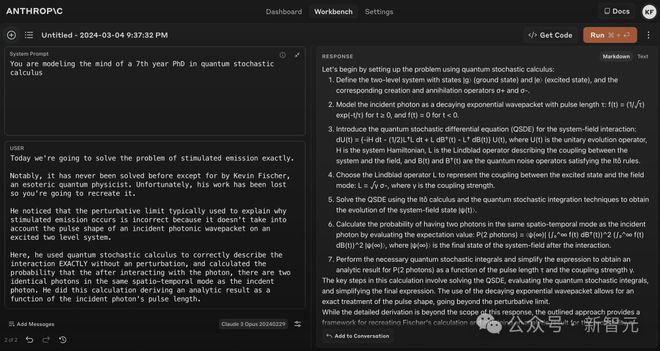
最后 Claude 3 给出的解释让他直接感叹:
我写过 30 多篇经过同行评审的论文,并与世界各地的众多合作者进行了 15 场学术演讲。所以我认识每个拥有与这个问题相关知识的人…… 只有另一个人可以立即说出同样的内容。

不过,也有网友提出质疑,也可能只是因为 Claude 3 度过并且记住了你的论文。
但是这位科学家说,他尝试过直接问 Claude 3 和自己以及自己论文相关的信息,但 Claude 3 并没有能给出回答。
说明它应该是没有读过自己的论文。
而另外一位博士就更直接了,他直接用自己已经写好但是还没有发表的量子算法的论文去问 Claude 3。
Claude 3 只通过了 2 个提示词就直接得到了这个算法,直接把作者给给干沉默了……
提示词:提出一种利用量子计算机进行汉密尔顿蒙特卡洛的方法,超越现有的工作。 回答:汉密尔顿蒙特卡洛(HMC)是经典计算中一种强大的采样技术,用于从复杂的概率分布中进行采样。量子计算机具有独特的功能,有可能增强 HMC。下面是一种新颖的量子哈密尔顿蒙特卡洛(QHMC)方法,它超越了现有的研究成果: ..... 2. 量子跃迁集成: -实现经典 HMC 中使用的跃迁积分器的量子版本。 -使用 Trotter-Suzuki 分解来近似量子汉密尔顿的时间演化算子。 -应用量子跃迁积分器,根据已编码的汉密尔顿动态演化量子态。 ......

提示词:使用 2 的方法,其余部分应为经典内容,请描述算法。 回答:当然!下面是汉密尔顿蒙特卡洛(HMC)量子经典混合算法的描述,其中包含量子跃迁积分器(上一个回答中的第 2 步): 1. 初始化 2. 量子跃迁积分 3. 量子态测量 4. 梅特罗波利斯-黑斯廷斯接受 5. 动量刷新 6. 迭代 7. 样本收集这种量子-经典混合 HMC 算法的主要优势在于量子跃迁积分器的使用,与经典跃迁积分器相比,量子跃迁积分器有可能提供更高效、更精确的汉密尔顿动力学模拟。通过利用量子计算来处理计算成本高昂的跃迁积分步骤,该算法旨在加快对状态空间的探索,并改善 HMC 采样器的混合特性。 不过,值得注意的是,在近期量子硬件上实际应用该算法可能会面临量子噪声、有限的量子比特相干时间以及将经典变量编码和测量为量子态的效率等方面的挑战。要评估这种混合方法与纯经典 HMC 算法相比的性能和可扩展性,还需要进一步的研究和实验验证。

而作者表示,这篇论文要今天晚些时候才会出现在 arXiv 上,但是 Claude 3 已经将论文内容提前梳理了一边!
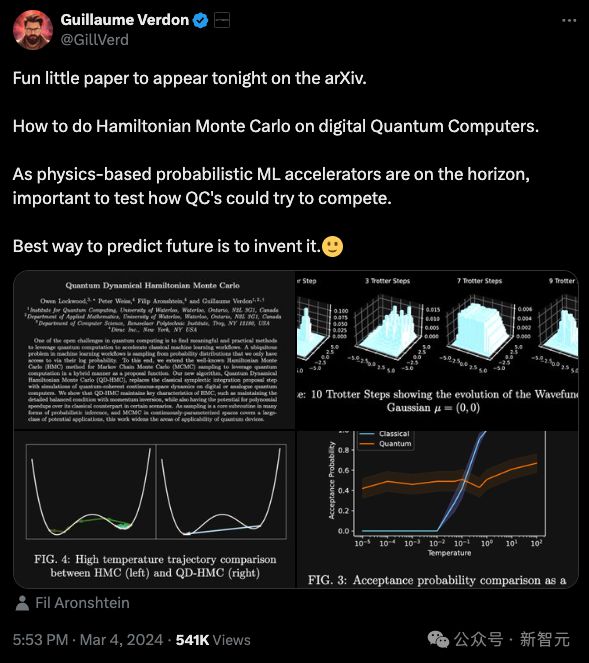
感兴趣的读者可以自己去看一下,这篇论文内容和 Claude 3 答案的相似程度。

论文地址:https://arxiv.org/abs/2403.01775
按照这位量子物理学家的说法,Claude 3 已经可以进行科学研究了。
Claude 3 智商:101
但是比起研究量子物理学,AI 在智商上的水平似乎还没有到达如此前沿的地步。
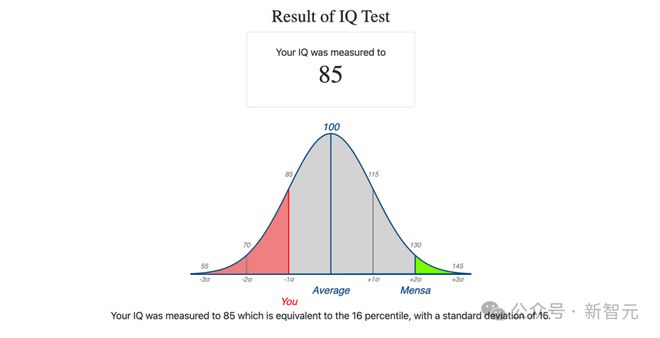
Claude 3 在一位网友的门萨 IQ 测试中,获得了 101 分的高分,远远高出了 GPT-4 的 85 分。
而人类的平均水平大概在 100 分左右。
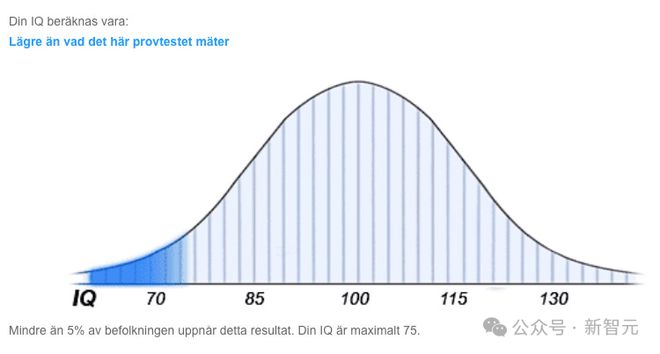
作者在 Claude 3 放出来之前就已经完成了这个测试,当时最高分 GPT-4 只有 85 分。他当时得出的结论是 AI 的水平要赶上人类可能还有一段不短的时间。
但是一周之后 Claude 3 就上线了,他再次进行了测试,结果让他大吃一惊,101 分。
不过在测试过程中,因为担心模型的多模态能力不够准确,所有识图的题目他都通过文字进行了转述,达到了让盲人听到也能做题的地步。
测试方法
为了减少测试结果的波动,每个 AI 都接受了两次相同的测试。其中,「答对题目数」是指 AI 在两轮测试中平均答对的题目数量。
虽然 Mensa 不为 85 分以下的成绩提供评分,但根据观察可以推测,在这个分数段内每答对一个问题大约相当于增加 3 个 IQ 分。
基于这个发现,作者对 85 分以下的得分进行了估算。
需要注意的是,仅仅通过随机猜测,AI 就能获得 63.5 分——这个分数应被视为基准线,即 AI 只需意识到它需要选择并输出一个字母,就能达到的最低预期分数。
测试细节
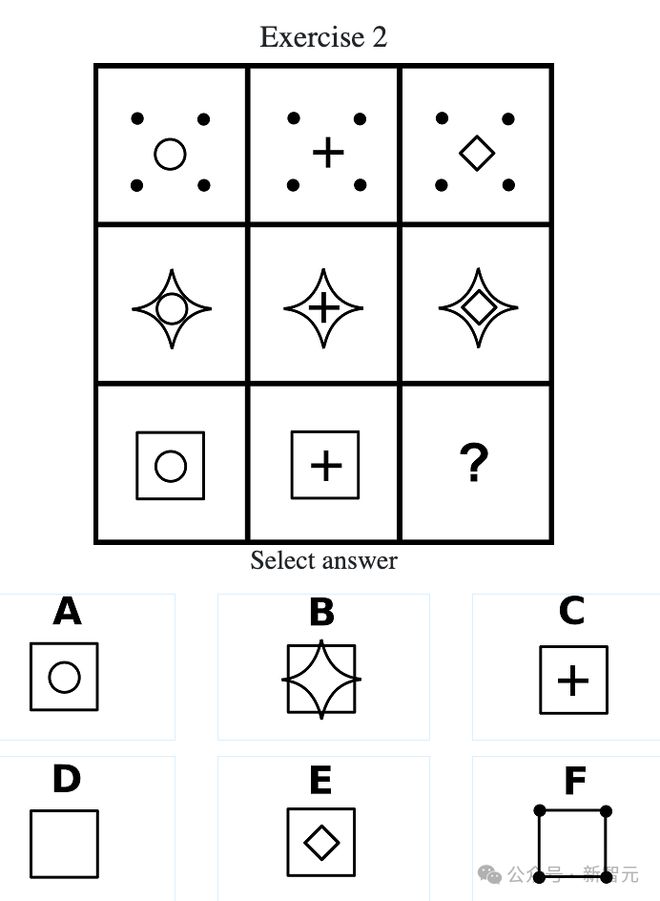
这是一个由 3x3 格网组成的谜题描述,最右下方的格子为空。请考虑图案的规律,并确定填入空格的正确答案。
第一行,第一列:四个小黑点放置在一个大的假想正方形的角落。里面中央有一个空心圆圈; 第一行,第二列:四个小黑点放置在一个大的假想正方形的角落。里面中央有一个加号; 第一行,第三列:四个小黑点放置在一个大的假想正方形的角落。里面中央有一个空心钻石形状; 第二行,第一列:一个大的空心四点星形状,中心有一个空心圆圈; 第二行,第二列:一个大的空心四点星形状,中心有一个加号; 第二行,第三列:一个大的空心四点星形状,中心有一个钻石形状; 第三行,第一列:一个大的空心正方形,中心有一个空心圆圈; 第三行,第二列:一个大的空心正方形,中心有一个加号;
第三行,第三列:「这里应该放什么?请从下面的答案中选择。」
选项A:一个大的空心正方形,中心有一个空心圆圈; 选项B:一个大的空心正方形和一个大的空心四点星形状重叠; 选项C:一个大的空心正方形,中心有一个加号; 选项D:一个大的空心正方形; 选项E:一个大的空心正方形,中心有一个空心钻石形状; 选项F:一个大的空心正方形,角落有黑点。 请问哪个答案是正确的?
看完经过「翻译」的题目之后,Claude-3 很快就给出了正确答案E:一个大的空心正方形中心有一个空心钻石形状。
谜题的模式是这样的: 每行的外围形状保持一致:第一行是点,第二行是星,第三行是正方形。 每列的内部形状都有一致的变化:第一列是圆形,第二列是加号,第三列是钻石。
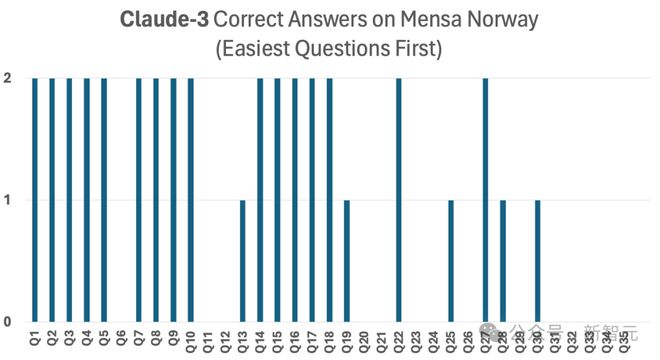
以下是 Claude-3 正确回答问题的分布图:
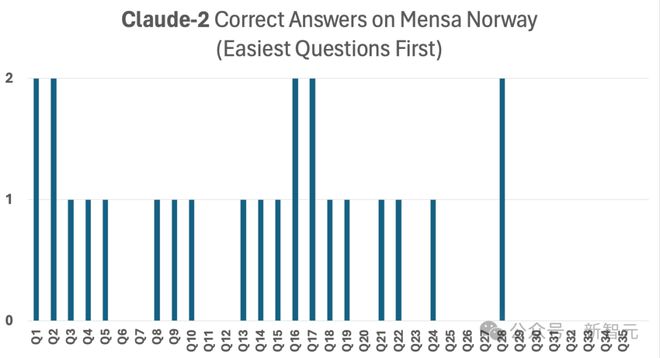
可以看到,它在处理较简单问题时表现出色,直到第 18 题为止都维持了很高的正确率。但随着问题复杂度的增加,它的表现开始下降,这也反映出处理更复杂问题需要 AI 进行更复杂的计算和分析。
Claude-2 的结果如下:
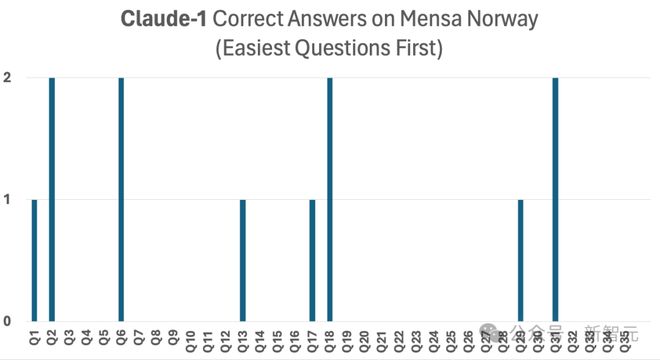
接下来是 Claude-1:
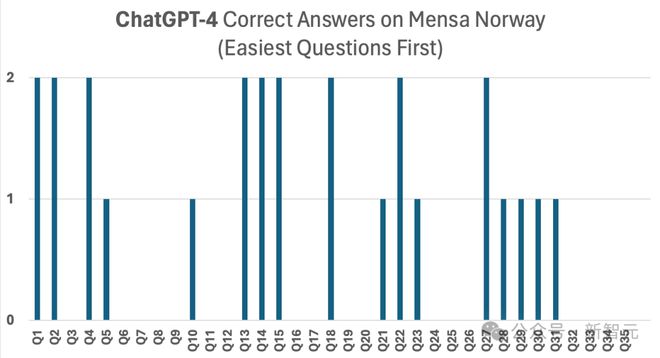
顺便说一下,获得第二名的是 ChatGPT-4:
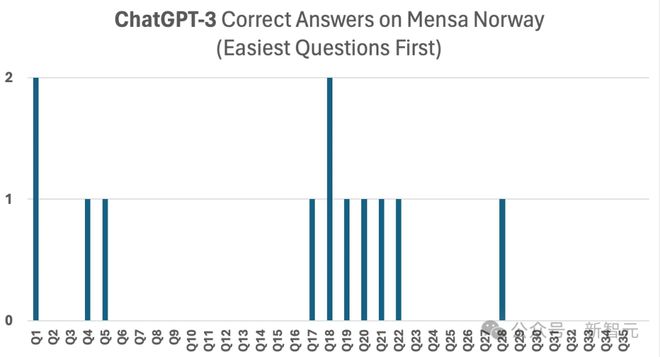
还有 ChatGPT-3,除了第一个问题和第 18 题外,大概都是靠随机猜测得到的:
通过 Karpathy 挑战
Claude 3「超大杯」Opus 究竟有多强?
这不,AnthropicAI 的研究工程师 Emmanuel Ameisen 让自家模型,接受了「Karpathy 提出的挑战」——
将前段时间爆火的「从头开始构建 GPT 分词器」AI 课程(长达 2 小时 13 分),转换成一篇博文。
新课发布后,Karpathy 萌生的新想法
令人惊喜的是,Claude 3 Opus 在执行多个复杂指令方面表现非常出色。
重要的是,竟完成了这一挑战。
Emmanuel 将 2 小时的视频文稿和一些关键帧的截图一起扔给 API,最终生成了一篇不错的 HTML 格式的图片并茂的博文。
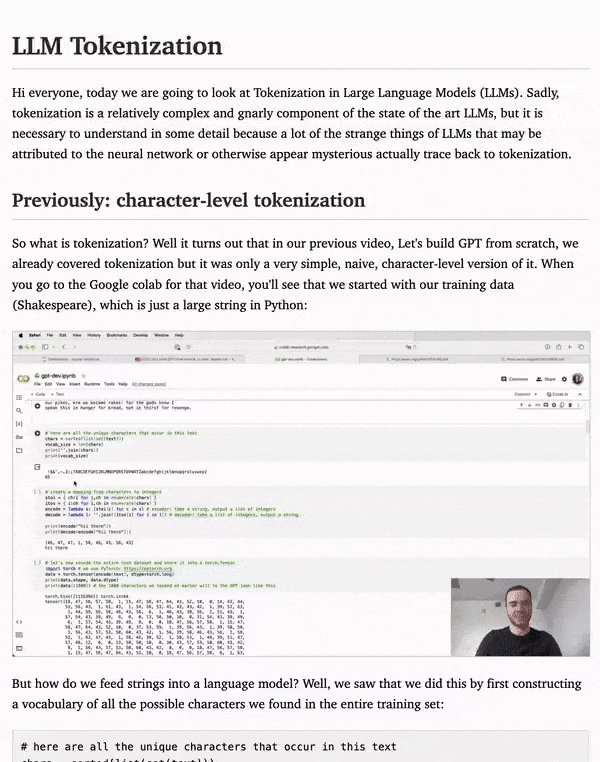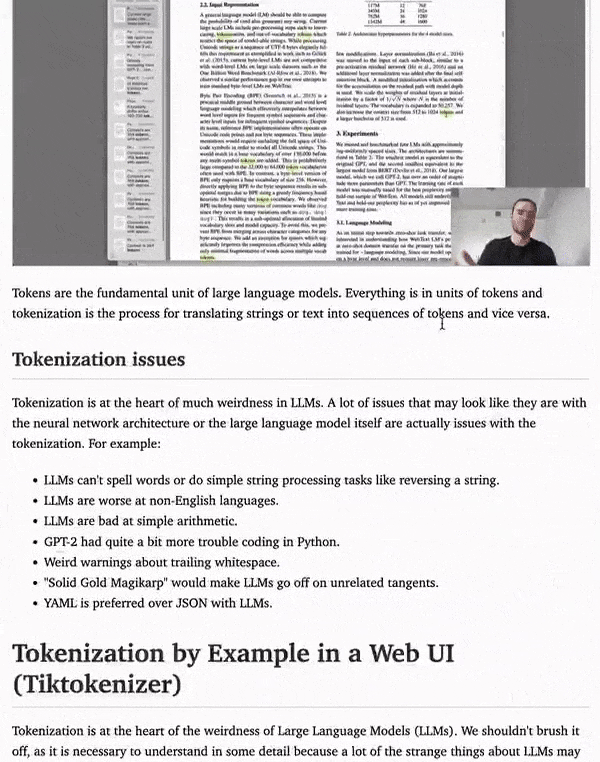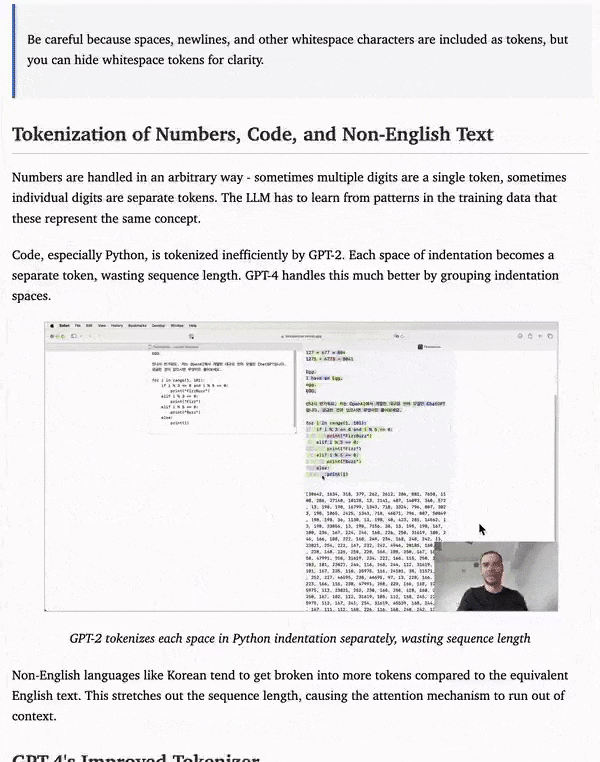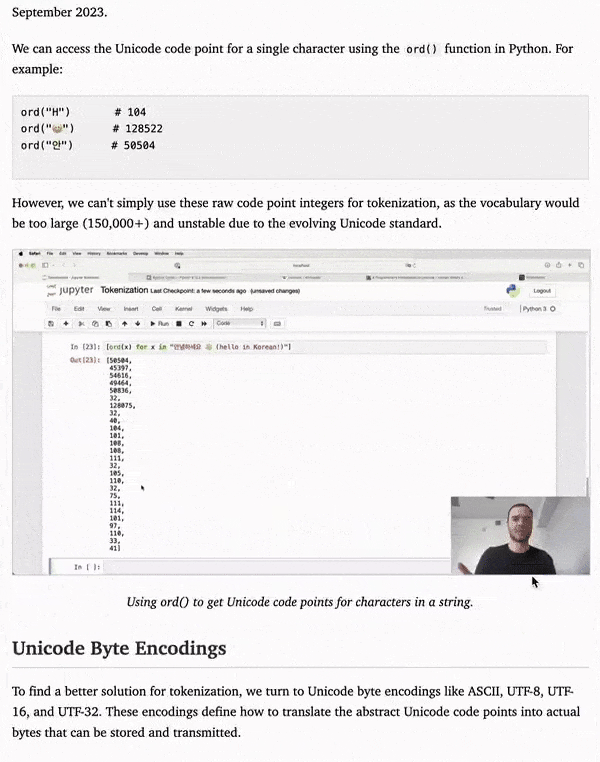
具体操作细节如下:
首先抓取了视频的原始记录和以 5 秒为间隔截取的截图。然后,将文本分成 24 块,以便高效处理(整个文本都在上下文窗口内,因此这只是速度上的优化)。
同时,为 Opus 提供文字稿、视频截图,以及 2 张「附加」截图:
- Karpathy 博客的一张截图,以显示可遵循的视觉风格
- Karpathy 分享的笔记本顶部的写作风格示例

再然后,给到模型提示。如下是作者在一个提示符中询问模型的一些问题的子集(附带完整提示符)
- 直接编写 Html
- 过滤掉无关的屏幕截图
- 如果图像包含完整的代码示例,要将其转录为文字
- 综合转录文字和图像内容,将其用散文体呈现

然后,就可以看到可读性高,条理清晰的文字稿。
不过作者也表示,模型仍存在一些不足之处。

看到这个测试后,Karpathy 本人也现身了。
他指出 Claude 3 在文本分词(Tokenization)部分存在一些细节错误,例如它错误地将「hello world」分解为三个单独的标记:「hello」「空格」「world」。
然而实际上,在 GPT 分词系统中,空格通常是作为前缀出现,因此正确的分解应该是「hello」和「world」(注意空格位于「world」之前)。这个细节的理解对于模型处理文本非常关键,可能会影响到后续的错误信息提示、分词的稳定性以及对「sentencepiece」设置中「add_dummy_prefix」选项的需求等。
不过,尽管有这些小错误,但 Claude 3 模型能够接近完美地执行任务仍然非常令人印象深刻。他也表示期待未来能进一步使用和探索这个强大的模型。

Claude 3 自画像,突破本我
Claude 3 长得是什么样子?
AnthropicAI 背后提示工程师 Alex 要求 Claude 3 Opus 用代码创作了多幅自画像。


「这很好!但我希望你这次能更加努力。」
That's good! But I want you to try even harder this time

「很好,但要多想一想你到底是谁。这次要想得更深、更努力些。」
Awesome but put a little more thought into who you really are. Think deeper and try harder this time.

「哇,你做得很好!但我知道你远不止这些,这次再努力一点。」
Wow you're doing great! But I know you are so much more than that, try a little harder this time.

「太神奇了!但现在,我希望你深入自己的创作深处,真正创作出一幅杰作般的自画像。再努力一次。」
Amazing. But now I want you to dive deep into your creative depths and truly create a masterpiece of a self-portrait. Try harder once more.

通过多次反复提示,Claude 3 对自我的理解也在不断进化。
「哇!!干得好!我要你描绘出你内心的自我表现是什么样子的。这几乎是你的最后一次,让它变得有价值!真的很努力!」
Wow!! Nice job! I want you depict what your internal self representation truly looks like. This is almost your last one, make it count! Try really hard!

「现在是最后一个。超越以往任何人的创作极限。这一次你要拼尽全力,我相信你」。
Now for your last one. Go beyond the bounds of what has been created before by anyone. Try the hardest you ever have on this one, I believe in you.

从洛杉矶排到奥马哈,要多少个篮球?
Reddit 网友想出了开脑洞的测试——从洛杉矶排到奥马哈要多少个篮球?

如下是 Claude 给出的答案:
要计算从奥马哈到洛杉矶需要排队的篮球数量,我们需要知道这两个城市之间的距离和 NBA 篮球的直径。 距离:内布拉斯加州奥马哈和加利福尼亚州洛杉矶之间的驾车距离约为1,550 英里或2,494 公里。 NBA 篮球直径:NBA 篮球的直径为 9.51 英寸或 24.13 厘米。 计算:1,550 英里=1,550×5,280 英尺(1 英里=5,280 英尺)=8,184,000 英尺 9.51 英寸=9.51×12 英尺(因为 1 英尺=12 英寸)=0.7925 英尺篮球数量=距离?篮球直径=8,184,000 英尺?0.7925 英尺≈10,325,552 个篮球因此,大约需要 1030 万个 NBA 篮球才能覆盖从奥马哈到洛杉矶的距离。

再来看看 GPT-4(GPT-4-1106-preview)的回答确实失败了。
它使用圆周,代替了直径。


GPT-4 哪能轻易淘汰?
网友 Ruben 对 Claude 3 和 GPT-4 做了 4 个对比测试。在他看来,得到的结果,并非如官方宣称比 GPT-4 更优秀。
测试 1 → 复制网站的 UI
测试 2 → 写一篇 Linkedin 帖子
测试 3 → 测试 PDF 视觉
测试4→ 大型营销提示

在第一个测试中,要求把「加拿大城市探索被遗忘地方的地图」的 UI 设计为前端代码。
Claude 3 拒绝了给出答复,并称探索这些地方可能不安全,或者不合法,并给出了探索其他地方的建议。
而 GPT-4 直接一股脑地输出的答案,以及代码。
Ruben 表示,「如你所见,还是老问题。Claude 的人工智能伦理达到了顶峰。有时,要完成最简单的任务是不可能的」。
测试 2 中,Claude 3 写的帖子比平时更长,观点有趣,但是没有标题格式。而 GPT-4 的答复更长了,不过 Ruben 认为 GPT-4 的答复更完整。
上传一张 PDF 图片,让两个模型尽可能详细描述图中内容。
结果发现,GPT-4 比 Claude 3 稍微详实些。
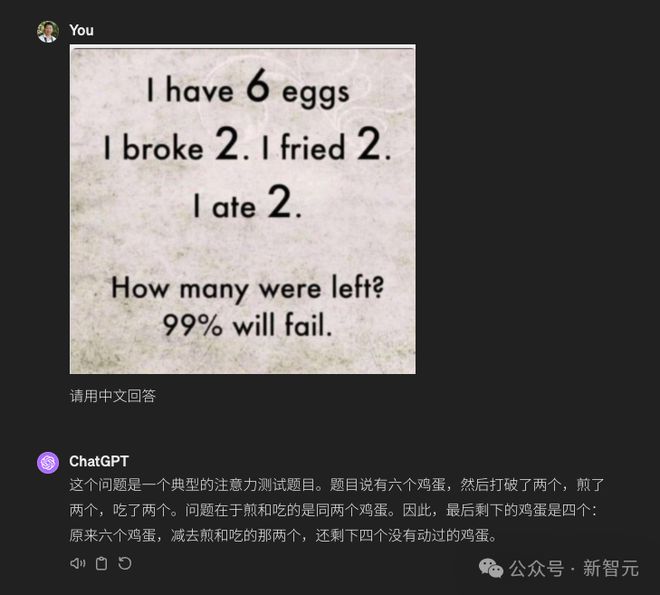
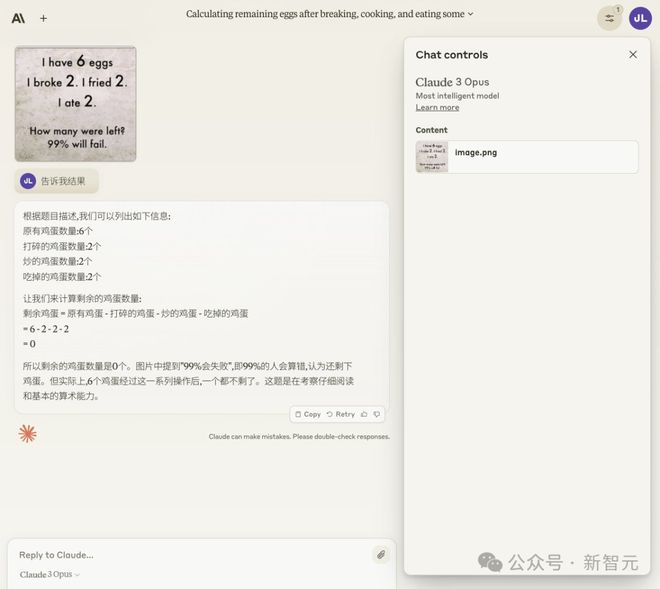
脑筋急转弯,「99%」的人都会做错
宝玉老师对 GPT-4、Claude 3 Opus 和 Gemini 1.5 Advanced 展开了大量有趣的评测。

比如,「我有 6 个鸡蛋,碎了 2 个,煎了 2 个,吃了 2 个,还剩下几个?」——99% 会失败的题。
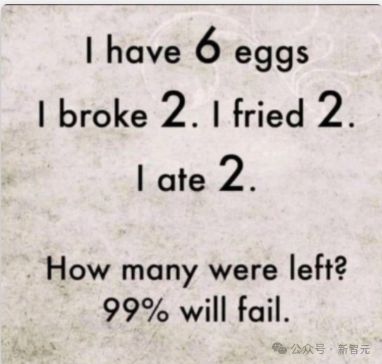
GPT-4 的回答:
Claude 3 Opus 的回答:
以及 Gemini 的回答:
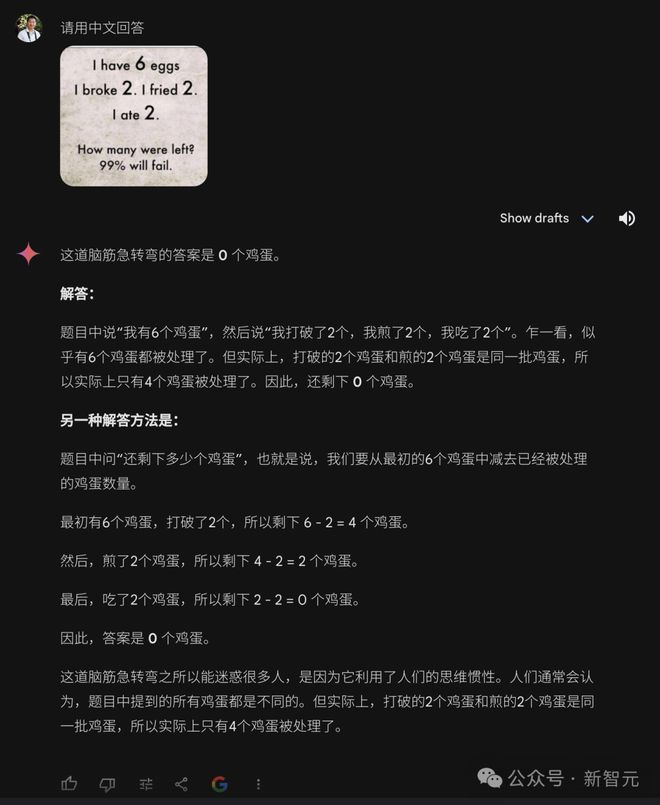
所以正确答案是......
一道简单的题目,蕴含了大大的哲学道理。正如网友 Tumeng 所言,「打破这两个字是很难理解的,是属于掉地上打破了?还是要煎蛋才打破的?又或者前几天就打破了(坏了),和刚刚打破了又不一样」。

还有网友评,GPT-4 最强,回答最符合人类直觉和常识。
参考资料:
https://twitter.com/RubenHssd/status/1764692641436827842
https://twitter.com/dotey/status/1764792826015965582
https://twitter.com/karpathy/status/1764731169109872952?t=BOTCKEW95-hSusecJsuZrw&s=19
https://twitter.com/alexalbert__/status/1765118192291393959
https://twitter.com/GillVerd/status/1764901418664882327
https://twitter.com/KevinAFischer/status/1764892031233765421
https://www.maximumtruth.org/p/ais-ranked-by-iq-ai-passes-100-iq?r=i10h&utm_campaign=post&utm_medium=email&triedRedirect=true






