丰色发自凹非寺
量子位公众号 QbitAI
李开复旗下 AI 公司零一万物,又一位大模型选手登场:
90 亿参数 Yi-9B。
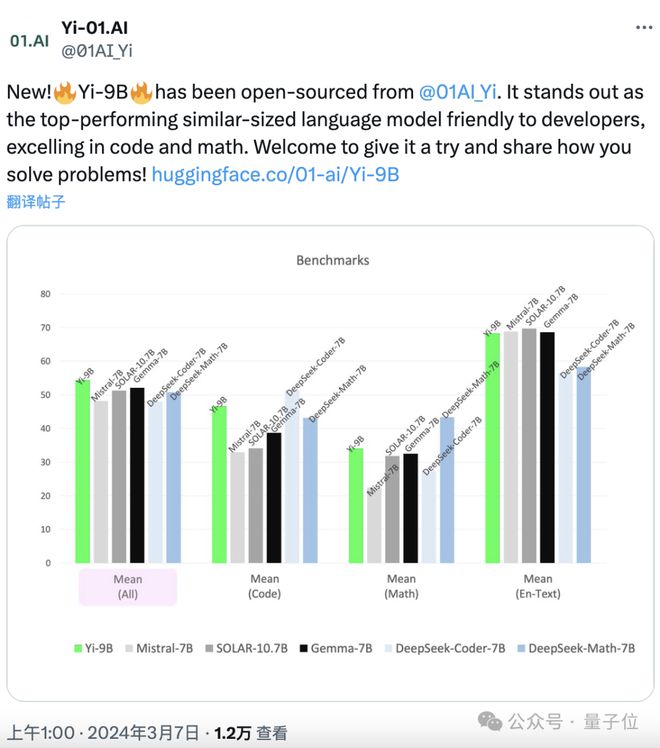
它号称 Yi 系列中的“理科状元”,“恶补”了代码数学,同时综合能力也没落下。
在一系列类似规模的开源模型(包括 Mistral-7B、SOLAR-10.7B、Gemma-7B、DeepSeek-Coder-7B-Base-v1.5 等)中,表现最佳。
老规矩,发布即开源,尤其对开发者友好:
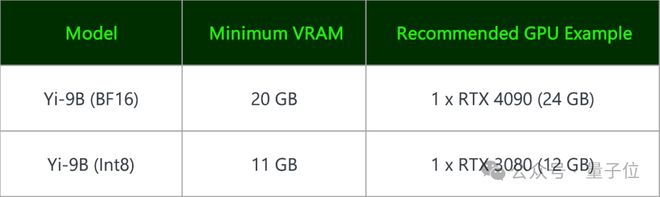
Yi-9B(BF 16) 和其量化版 Yi-9B(Int8)都能在消费级显卡上部署。
一块 RTX 4090、一块 RTX 3090 就可以。
深度扩增+多阶段增量训练而成
零一万物的 Yi 家族此前已经发布了 Yi-6B 和 Yi-34B 系列。
这两者都是在 3.1T token 中英文数据上进行的预训练,Yi-9B 则在此基础上,增加了 0.8T token 继续训练而成。
数据的截止日期是2023 年 6 月。
开头提到,Yi-9B 最大的进步在于数学和代码,那么这俩能力究竟如何提升呢?
零一万物介绍:
单靠增加数据量并没法达到预期。
靠的是先增加模型大小,在 Yi-6B 的基础上增至 9B,再进行多阶段数据增量训练。
首先,怎么个模型大小增加法?
一个前提是,团队通过分析发现:
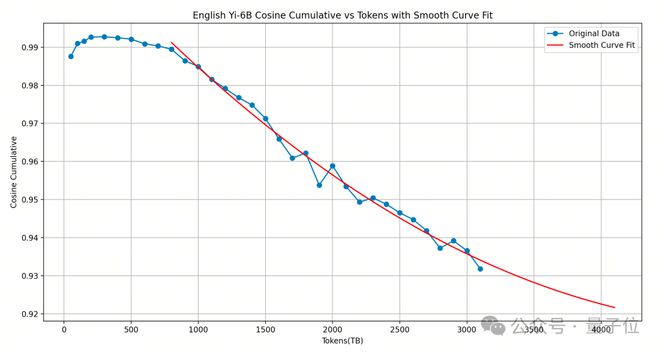
Yi-6B 训练得已经很充分,再怎么新增更多 token 练效果可能也不会往上了,所以考虑扩增它的大小。(下图单位不是 TB 而是B)
怎么增?答案是深度扩增。
零一万物介绍:
对原模型进行宽度扩增会带来更多的性能损失,通过选择合适的 layer 对模型进行深度扩增后,新增 layer 的 input/output cosine 越接近 1.0,即扩增后的模型性能越能保持原有模型的性能,模型性能损失微弱。
依照此思路,零一万物选择复制 Yi-6B 相对靠后的 16 层(12-28 层),组成了 48 层的 Yi-9B。
实验显示,这种方法比用 Solar-10.7B 模型复制中间的 16 层(8-24 层)性能更优。
其次,怎么个多阶段训练法?
答案是先增加 0.4T 包含文本和代码的数据,但数据配比与 Yi-6B 一样。
然后增加另外的 0.4T 数据,同样包括文本和代码,但重点增加代码和数学数据的比例。
(悟了,就和我们在大模型提问里的诀窍“think step by step”思路一样)
这两步操作完成后,还没完,团队还参考两篇论文(An Empirical Model of Large-Batch Training 和 Don’t Decay the Learning Rate, Increase the Batch Size)的思路,优化了调参方法。
即从固定的学习率开始,每当模型 loss 停止下降时就增加 batch size,使其下降不中断,让模型学习得更加充分。
最终,Yi-9B 实际共包含 88 亿参数,达成 4k 上下文长度。
Yi 系列中代码和数学能力最强
实测中,零一万物使用 greedy decoding 的生成方式(即每次选择概率值最大的单词)来进行测试。
参评模型为 DeepSeek-Coder、DeepSeek-Math、Mistral-7B、SOLAR-10.7B 和 Gemma-7B:
(1)DeepSeek-Coder,来自国内的深度求索公司,其 33B 的指令调优版本人类评估超越 GPT-3.5-turbo,7B 版本性能则能达到 CodeLlama-34B 的性能。
DeepSeek-Math则靠 7B 参数干翻 GPT-4,震撼整个开源社区。
(2)SOLAR-10.7B来自韩国的 Upstage AI,2023 年 12 月诞生,性能超越 Mixtral-8x7B-Instruct。
(3)Mistral-7B则是首个开源 MoE 大模型,达到甚至超越了 Llama 2 70B 和 GPT-3.5 的水平。
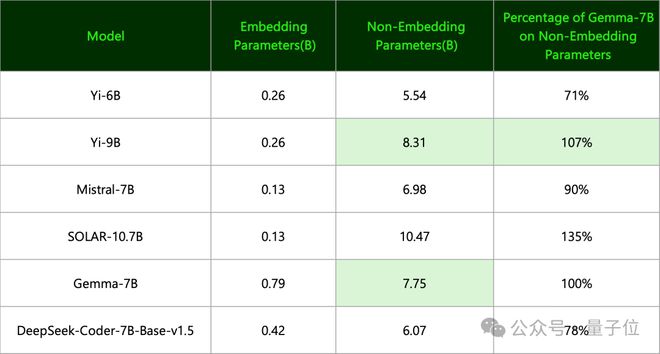
(4)Gemma-7B来自谷歌,零一万物指出:
其有效参数量其实和 Yi-9B 一个等级。
(两者命名准则不一样,前者只用了 Non-Embedding 参数,后者用的是全部参数量并向上取整)
结果如下。
首先在代码任务上,Yi-9B 性能仅次于 DeepSeek-Coder-7B,其余四位全部被 KO。
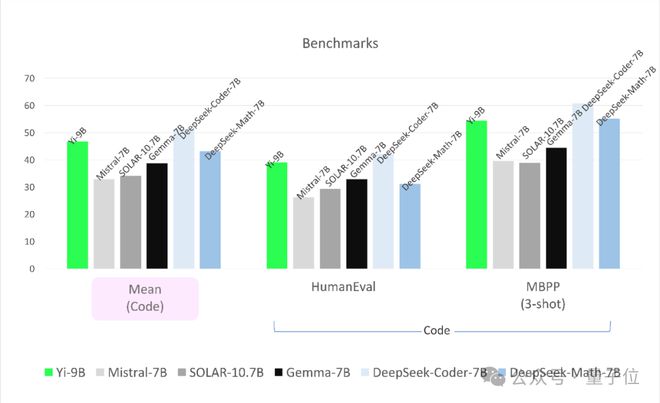
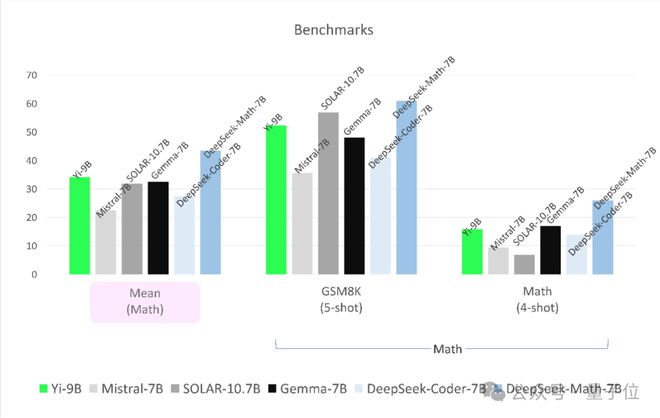
在数学能力上,Yi-9B 性能仅次于 DeepSeek-Math-7B,超越其余四位。
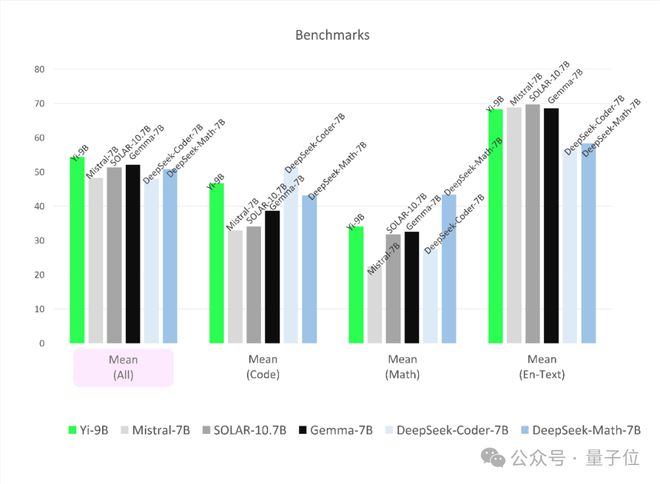
综合能力也不赖。
其性能在尺寸相近的开源模型中最好,超越了其余全部五位选手。
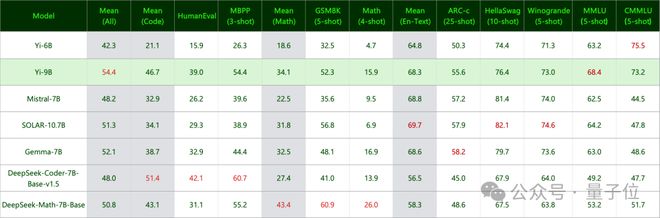
最后,还测了常识和推理能力:
结果是 Yi-9B 与 Mistral-7B、SOLAR-10.7B 和 Gemma-7B 不相上下。
以及语言能力,不仅英文不错,中文也是广受好评:
最最后,看完这些,有网友表示:已经迫不及待想试试了。

还有人则替 DeepSeek 捏了一把汗:
赶紧加强你们的“比赛”吧。全面主导地位已经没有了==

传送门在此:
https://huggingface.co/01-ai/Yi-9B
参考链接:






