
出品|网易科技《态度》栏目
作者|薛世轩
编辑|丁广胜
所有的创新都有其现实驱动力。
在互联网巨头的世界,这一驱动力就是成本。
“降本增效”的逻辑贯穿着技术演进的始终,大模型架构也不例外。
目前,大模型的发展已经到了一个瓶颈期,包括被业内诟病的逻辑理解问题、数学推理能力等,想要解决这些问题就不得不继续增加模型的复杂度。
如何平衡大模型的训练难度和推理成本成为摆在各位玩家面前的难题。
而 MoE 模型的日渐成熟为开发者们重新指引了前进的方向——通过改变模型底层架构,换一种耗能低且训练和推理效果好的模型架构进行大模型开发。
一、MoE 的前世今生:老树又冒新芽
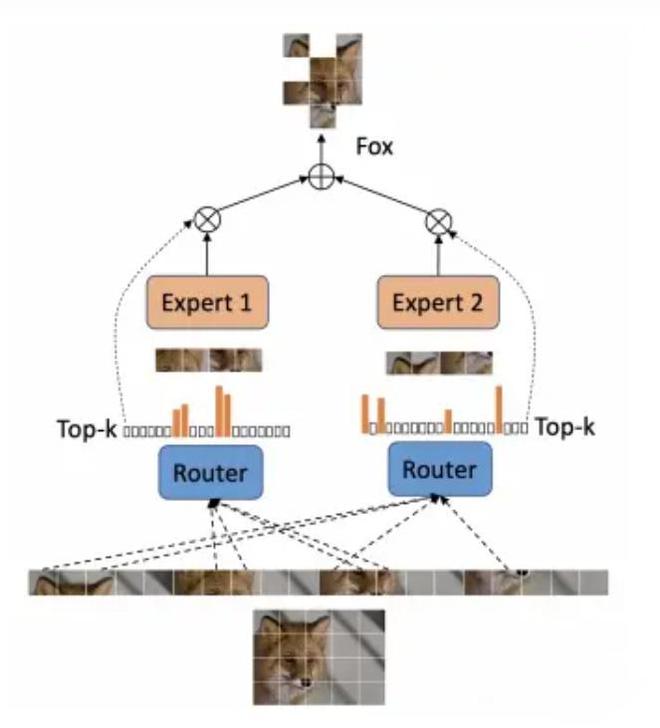
MoE(Mixture-of-Experts,专家混合),首次出现于 1991 年的论文Adaptive Mixture of Local Experts中,其前身是“集成学习”(Ensemble Learning),作为一种由专家模型和门控模型组成稀疏门控制的深度学习技术,MoE 由多个子模型(即专家)组成,每个子模型都是一个局部模型,专门处理输入空间的一个子集。
在“分而治之”的核心思想指导下,MoE 使用门控网络来决定每个数据应该被哪个模型去训练,从而减轻不同类型样本之间的干扰。
通俗来讲,MoE 就像复仇者联盟,每个子模型(专家)都是一个超级英雄,门控网络则是尼克·弗瑞,负责协调各个超级英雄,决定在什么情况下召唤哪位英雄。门控网络会根据任务的特点,选择最合适的专家进行处理,然后将各位专家的输出汇总起来,给出最终的答案。
门控功能“稀疏性”的引入让 MoE 在处理输入数据时只激活使用少数专家模型,大部分专家模型处于未激活状态。换言之,只有擅长某一特定领域的超级英雄会被派遣,为用户提供最专业的服务,而其他超级英雄则原地待命,静待自己擅长的领域到来。这种“稀疏状态”作为混合专家模型的重要优势,进一步提升了模型训练和推理过程的效率。
MoE 发展至今,离不开两个研究领域对其所做的巨大贡献:专家作为关键组件与条件计算。
前者让 MoEs 成为更深层次网络的组成部分,让 MoEs 可以灵活的作为多层网络中的某个层级存在,实现模型的大规模化与高效率并存;后者通过动态激活或关闭输入每一层级的数据从而实现数据的高效处理。
MoE 的加入让整个神经网络系统就像一个大型图书馆,每层都有不同类型的书籍和专业的图书管理员,门控系统(图书馆的智能导引系统)会根据读者的不同需求,将他们引导至最合适的楼层(多层网络中的某一层级),而这一过程也不断根据数据特点进行实时动态处理。
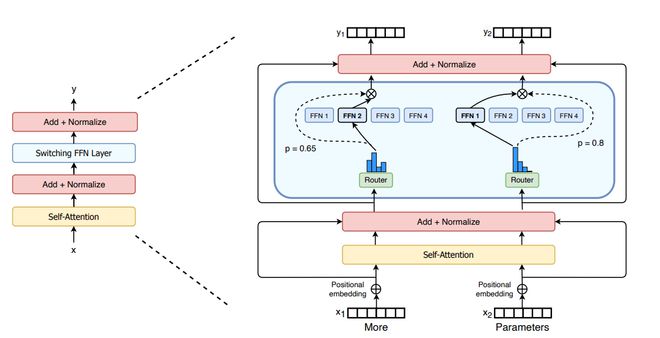
MoE 虽然能够高效地进行预训练并且在推理速度上超越密集型模型,但同时也面临一些挑战。
稀疏专家模型领域的权威研究人员 Barret Zoph、Irwan Bello 等人指出,每个 encoder(光栅)的专家虽然学习到了一部分 token 或简单的理论,但 decoder(译码器)专家并没有展现出专业化的特征;专家虽训练了一个多语言模型,但是并没有发现某一个专家精通某种单一语言。
简言之,这也道出了目前 MoE 在微调过程中面临的泛化的困难以及可能出现的过拟合困境。
不过综合来看,大模型结合混合专家模型的方法属于老树发新芽,随着应用场景的复杂化和细分化,大模型越来越大,垂直领域应用更加碎片化,想要一个模型既能回答通识问题,又能解决专业领域问题,MoE 无疑是一种性价比更高的选择。
二、拓展?颠覆?MoE 与 Transformer 的“夺嫡之争”
Google 于 2017 年在其论文 Attention Is All You Need 中首次提出了当下大火的大语言模型——Transformer:主要用于处理序列到序列(Seq2Seq)的任务。虽然它在长距离依赖捕捉与并行化处理等方面具有显著优势,但由于缺乏循环结构,使得要想通过 Transformer 训练 AI 大模型需要花费大量算力资源且耗时更长。
以 GPT 为例,其所使用的 Transformer 的解码器部分在训练过程中每天约消耗超 50 万度电力,训练成本更是以万亿美元为单位计数。如此巨额的开销自然不是追求“降本增效”的互联网公司所希冀的。
大模型底层架构的更新已势在必行。
搭载 MoE 架构的可持续新模型逐渐成为大模型开发者的新宠。
2023 年 12 月,Mistral AI 开源了基于 MoE 架构的模型 Mixtral 8x7B,其性超越包括 GPT-3.5 在内的众多参数更多的模型,显示了 MoE 架构在大模型研究中的潜力。
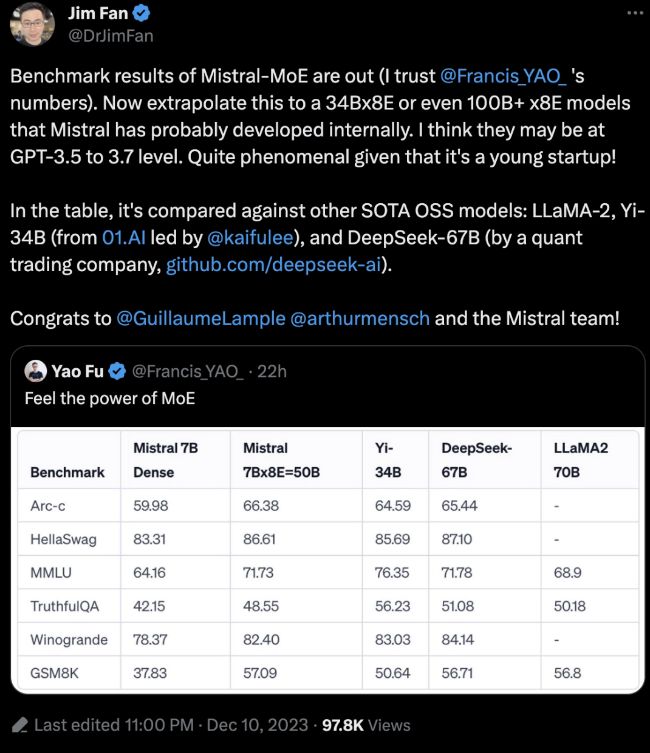
据 NVIDIA 高级研究科学家 Jim Fan 预测,经过训练的 MoE 大模型性能很有可能无限接近 GPT-4。
不止于此,谷歌基于 MoE 架构成功开发了 GLaM 的语言模型;Snowflake 采用 MoE 架构发布了大型语言模型 Snowflake Arctic;昆仑万维发布的基于 MoE 架构的大语言模型“天工 2.0/3.0”等等。
实践证明,MoE 已经成为高性能 AI 大模型的必选项。
三、大模型的技术性创新:巨头发难下的无奈之举
AI 大模型的迭代离不开高效的算力芯片,而英伟达的市场行为通常能够左右 AI 领域大模型开发者的策略。
奔走在大模型研发前线的开发者们深谙这一法则。所有鸡蛋不能放在同一个篮子里,既要提防英伟达“坐地起价”,又要着手开发能够进一步“降本增效”的大模型,将主动权重新掌握在自己手中。
这种策略是正确的。
2022 年底,受禁售传闻等多因素叠加影响,英伟达中国特供版 A100 一周内涨价超 30%,间接导致定制版 A800 价格飙升至 10000 美元以上。而随后发布的 H100 芯片更是在 eBay 上被炒到超 4 万美元一枚,且价格仍一路攀升。
高昂的芯片价格压的大模型公司喘不过来气,是继续承担激增的成本还是从大模型底层架构入手另寻他法成为他们必须进行的抉择。
毋庸置疑的是,他们善用技术,当资本与之抗衡时,技术就成为他们最有力的武器。
要想摆脱大模型训练与研发过程中可能存在的断档问题,开发者能做的只有通过大模型技术层面的持续破壁以对冲成本激增所带来的不稳定因素。
四、MoE:前路坦荡但也风雨交加
2017 年,谷歌首次将 MoE 引入自然语言处理领域,通过在 LSTM 层之间增加 MoE 实现了机器翻译方面的性能提升。
2020 年,Gshard 首次将 MoE 技术引入 Transformer 架构中,并提供了高效的分布式并行计算架构。
2021 年 1 月,谷歌的 Swtich Transformer 和 GLaM 则进一步挖掘 MoE 技术在自然语言处理领域中的应用潜力,实现了优秀的性能表现。
2021 年 6 月,V-MoE 将 MoE 架构应用在计算机视觉领域的 Transformer 架构模型中,同时通过路由算法的改进在相关任务中实现了更高的训练效率和更优秀的性能表现;
2022 年,LIMoE 作为首个应用了稀疏混合专家模型技术的多模态模型,模型性能相较于 CLIP 也有所提升。
2023 年,Mistral AI 发布的 Mistral 8x7B 模型由 70 亿参数的小模型组合起来的 MoE 模型,直接在多个跑分上超过了多达 700 亿参数的 Llama 2。
2024 年 2 月,昆仑万维正式发布了搭载新版 MoE 架构的大语言模型“天工 2.0”,并面向全体C端用户免费开放。同年 4 月,“天工 3.0”正式开启公测。
2024 年 4 月,MiniMax 发布的基于万亿 MoE 模型的 abab 6.5 可以 1 秒内处理近 3 万字的文本,并在各类核心能力测试中接近 GPT-4、Claude-3、 Gemini-1.5 等世界上领先的大语言模型
……
MoE 的征途仍在继续。
它自诞生以来便一路高歌,为大模型开发公司进一步“降本增效”的同时实现了大模型训练成本与训练效率之间的动态平衡。
但任何技术的普及与在地化应用从来并非坦途。
根植于 MoE 架构底层框架之上的训练复杂性、专家模型设计合理性、稀疏性失真、对数据噪声相对敏感等技术难关也都在制约着 MoE 架构在大数据模型中的发挥。
尽管 AI 领域的大模型开发者已经利用 MoE 架构成功研发了多款高效的大模型工具。但,任何技术都不可避免地掣肘于时代背景与现有知识框架,当新技术的发展触碰到了其自身所能达到的边界,这将会倒逼大模型开发者着眼于更开阔的路径,在创新与突破中实现大模型的技术革新与产品升级。
利用 MoE,但不止于 MoE。






