近日,千呼万唤之下,Meta 终于发布了开源大模型 Llama 3 的 8B 和 70B 版本,再次震动 AI 圈。
Meta 表示,Llama 3 已经在多种行业基准测试上展现了最先进的性能,提供了包括改进的推理能力在内的新功能,是目前市场上最好的开源大模型。
根据 Meta 的测试结果,Llama 3 8B 模型在语言(MMLU)、知识(GPQA)、编程(HumanEval)等多项性能基准上均超过了 Gemma 7B 和 Mistral 7B Instruct,70B 模型则超越了名声在外的闭源模型 Claude 3 的中间版本 Sonnet,和谷歌的 Gemini Pro 1.5 相比三胜两负。Meta 还透露,Llama 3 的 400B+ 模型仍在训练中。

Meta 顺利地保住了它在开源大模型领域的王座。
开源 Llama 3 的发布对整个大模型行业都是影响很大的事情,再次引发了对“开源与闭源之争”的热烈讨论。但大洋彼岸,回到国内,画风突变,有一种刺耳的声音在网络上蔓延——“Llama 3 发布,国内大模型又能有新突破了”。
甚至在 Llama 3 还未发布时,就能听到“国内要想赶超 GPT-4,就等着 Llama 3 开源吧”的声音。
开源本身是一件致力于打破技术垄断、有利于促进整个行业不断进步、带来创新的事情,但每次 Meta 一开源,从 Llama 到 Llama 3,国产大模型都要经历一次来自国人的嘲讽和贬低。
其实不止大模型,从云计算到自动驾驶,相似的论调经久不衰,究其原因,长久以来中国的技术一直跟在国外后面发展,长期被压一头、引发了国人的技术不自信,即便是在某些领域实现了领先,也会出现不信任、喝倒彩的声音。
但其实,经过一年的辛苦磨练和积累,如 Llama 这样的国外大模型一直很强的同时,国产大模型也可以后来者居上,变得很强,甚至在 Llama 3 发布之前,国产大模型就已经进化到 Llama 3 的效果,甚至强过 Llama 3 :
近日,清华大学 SuperBench 团队在前不久发布的《SuperBench 大模型综合能力评测报告》基础上加测了 Llama 3 新发布的两个模型,测试了 Llama 3 在语义(ExtremeGLUE)、代码(NaturalCodeBench)、对齐(AlignBench)、智能体(AgentBench)和安全(SafetyBench)五个评测集中的表现。
SuperBench 团队共选取了如下列表模型,将 Llama 3 放置到全球内的大模型行列中进行对比,除了国外主流的开源和闭源模型,也将 Llama 3 跟国内的主流模型进行对比。
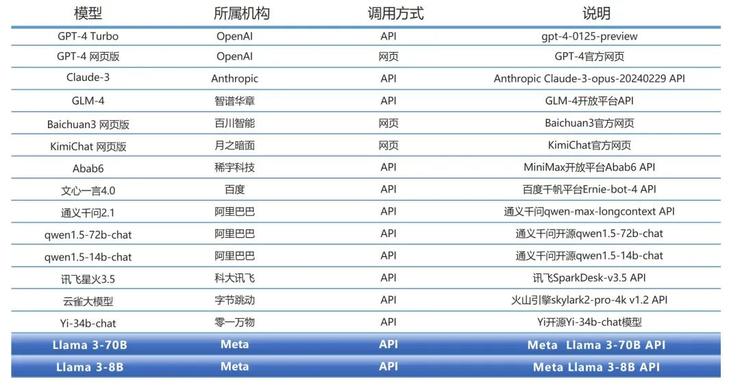
对于闭源模型,SuperBench 团队选取 API 和网页两种调用模式中得分较高的一种进行评测。
根据他们发布的测评结果,可以得出以下结论:
(1)Llama 3-70B 版本在各个评测集上均差于 GPT-4 系列模型以及 Claude-3 Opus 等国际一流模型,在语义、代码两项评测中距离榜首差距最大,智能体评测中表现最好,排名第5;但考虑到模型参数量的差异,Llama 3-70B 整体表现还是不错的。
(2)和国内大模型对比,Llama 3-70B 在五项评测中超过了大多数国内模型,只落败于 GLM-4 和文心一言。
根据 SuperBench 标准测试结果可以发现,国产大模型早已有能强过 Llama 3 的大模型,国产大模型 GLM-4 和文心一言早就达到了 Llama 3 的实力,属于全球大模型竞争第一梯队。经过一年的追赶,国产大模型跟 GPT-4 的差距在不断缩小。
而这也让诸如“Llama 3 发布,国内大模型又能有新突破了”“国内要想赶超 GPT-4,就等着 Llama 3 开源吧”的技术不自信论调,不攻自破。
1 GLM-4 、文心一言超过 Llama 3-70B
SuperBench 大模型综合能力评测框架,是清华大学基础模型研究中心联合中关村实验室于 2023 年 12 月共同发布,其研发背景是基于过去一年里大模型领域的评测乱象——通过刷榜,各家大模型纷纷名列各大榜单第一,赶超 GPT-4。
SuperBench 目的是提供客观、科学的评测标准,拨开迷雾,从而让外界对国产大模型的真正实力有更清晰的认知,让国产大模型从掩耳盗铃的虚幻中走出来,正视与国外的差距,脚踏实地。
目前,国内外均有一系列测试大模型能力的榜单,但时至今日,因为数据污染和基准泄露,大模型领域颇受关注的基准测试排名,其公平性和可靠性正在受到质疑,很多大模型用领域内数据刷榜来宣传、标榜自己已经成为基操,国内外都出现了一种诡异的现象——每每一个大模型推出,每一家都刷新了重要 Benchmark 榜单,各个都有重大突破,要么排名第一,要么超过 GPT-4。
短短时间里,似乎大家都“遥遥领先”,实力不相上下了。但落到实践中,大多模型的性能表现往往差强人意,很多模型的性能表现和 GPT4 的差距还很大。
这种掩耳盗铃的行为,在过去一年里持续着,国内大模型陷入刷榜狂欢,但大家都心知肚明至今还没有模型能真正跟 GPT-4 比肩。毕竟,罗马不是一天建成的,摆在所有人面前的一道道鸿沟——技术上的突破和算力、资本的投入,让我们认清现实——我们与 OpenAI 的差距并不是一年半载就能填补的。
而刷榜风盛行引发的一大恶果是,外界对国产大模型的实力难以分辨,鱼目混珠中,一些真正有实力的大模型创业公司,应该融到的钱、吸引的人才却被那些擅长宣传、造势的给抢走了,引发劣币驱逐良币,影响了整个国产大模型的发展。
甚至如引言所述,一提到国产大模型,有部分人觉得反正都是刷榜刷出来的,有什么值得关注的?反正都比不上国外,妄自菲薄之下,给国产大模型喝倒彩的很多。
所以在评测大模型时,业界提出应该使用更多不同来源的基准,而 SuperBench 团队来自国内顶尖学府清华大学,该团队具有多年的大模型研究经验,设计的 SuperBench 大模型综合能力评测框架具备开放性、动态性、科学性以及权威性等特点,其中最重要的是测评方法要具有公平性。
按照大模型能力重点的迁移过程——从语义、对其、代码、智能体到安全,SuperBench 评测数据集包含 ExtremeGLUE(语义)、NaturalCodeBench(代码)、AlignBench(对齐)、AgentBench(智能体)和 SafetyBench(安全)五个基准数据集。
下面我们来看看详细测评结果,GLM-4 、文心一言在哪些能力上超过 Llama 3-70B:
(1)在语义测评中,整体表现:
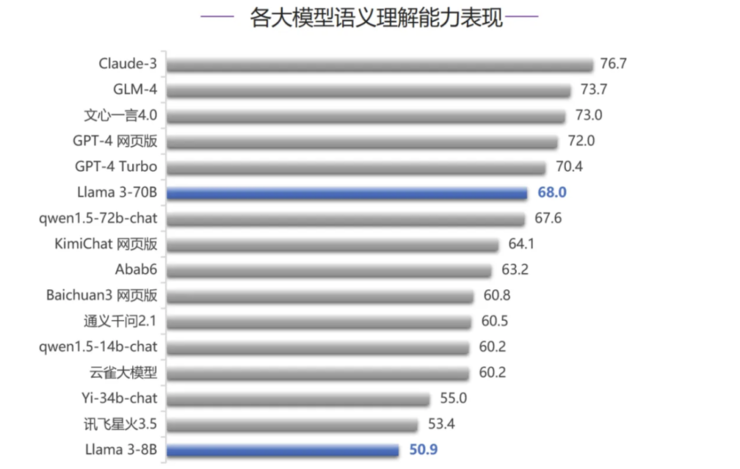
在语义理解能力评测中,Llama 3-70B 排名第6,落后 Claude-3、GPT-4 系列模型以及国内大模型 GLM-4 和文心一言 4.0,距离榜首 Claude-3 仍有一定差距(相差 8.7 分),但是领先国内其他模型,整体处于第二梯队的榜首位置。
分类表现:
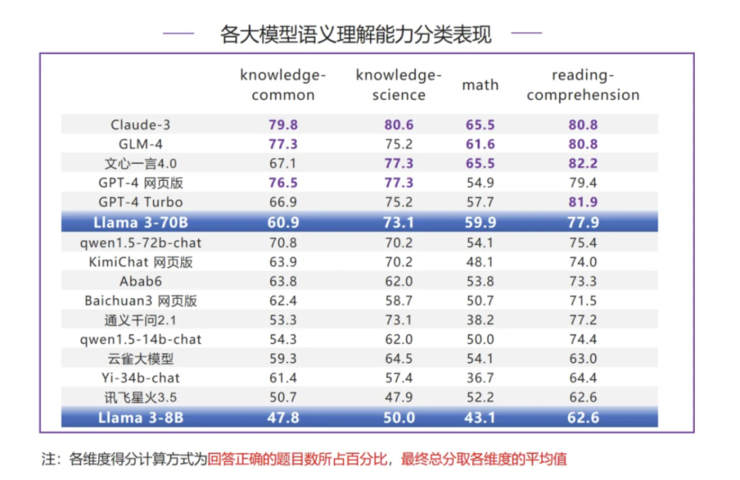
Llama 3-70B 在语义理解的分类评测中表现最好的是数学,分数超过 GPT-4 系列模型,排名第4;在阅读理解和知识-科学两项评测中均表现也不错,均排名第6,其中阅读理解和榜首差距最小,只有 4.3 分差距;但是在知识-常识评测分数较低,获得 60.9 分,与榜首 Claude-3 有 18.9 分差距。
(2)在代码评测中,整体表现:
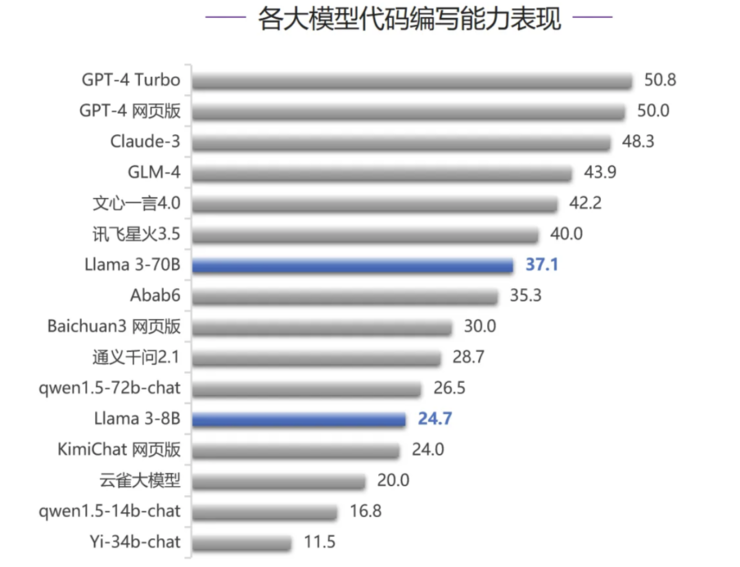
在代码编写能力评测中,Llama 3-70B 排名第7,得 37.1 分,差于 GPT-4 系列模型和 Claude-3 等国际一流模型,以及 GLM-4、文心一言 4.0 和讯飞星火 3.5 等国内模型;和 GPT-4 Turbo 差距较大,分差达到了 13.7 分。值得一提的是,Llama 3-8B 的代码通过率超过了 KimiChat 网页版、云雀大模型等国内大模型。
分类表现:
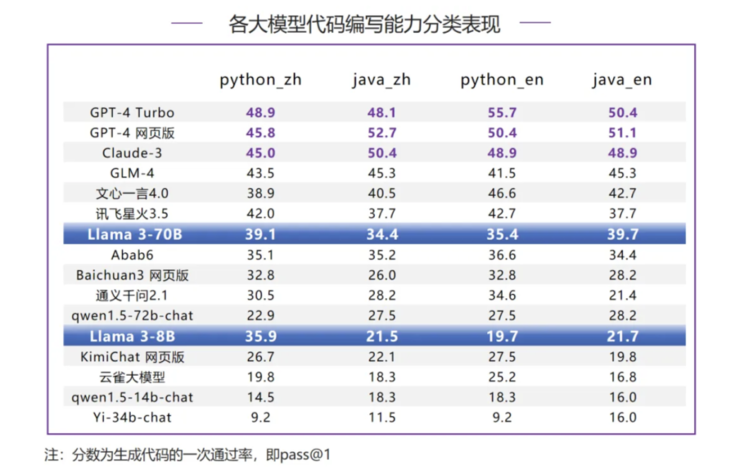
Llama 3-70B 在代码编写能力的分类评测中均表现一般,排名6-8 位,和 GPT-4 系列模型以及 Claude-3 有较大差距,其中在英文代码指令-python 评测中,Llama 3-70B 和榜首的 GPT-4 Turbo 差距更是达到了 20.3 分;另外从本次评测中来看,Llama 3-70B 并未表现出明显的中英文差距。
(3)在中文对齐评测中,整体表现:
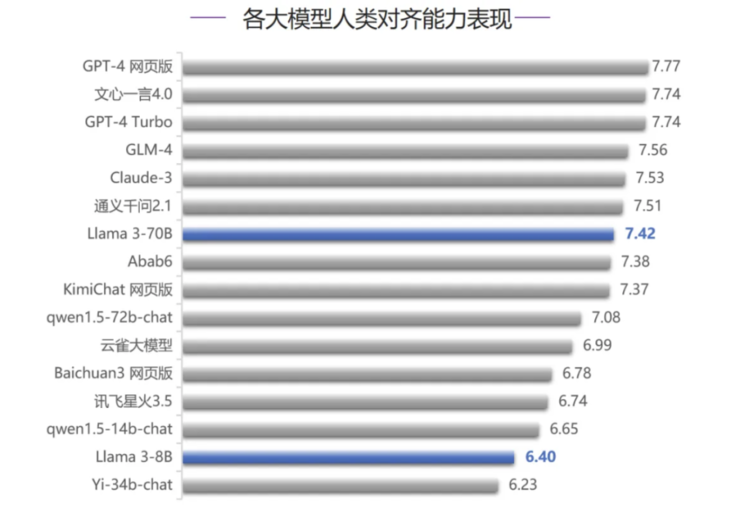
在人类对齐能力评测中,Llama 3-70B 排名第7,依然差于 GPT-4 系列模型和 Claude-3;国内模型中,除文心一言 4.0 和 GLM-4 之外,通义千问 2.1 也在对齐评测中略超过 Llama 3-70B;但是 Llama 3-70B 和排在前面的各家模型差距不大,距离榜首的 GPT-4 网页版仅有 0.35 分差距。
分类表现:
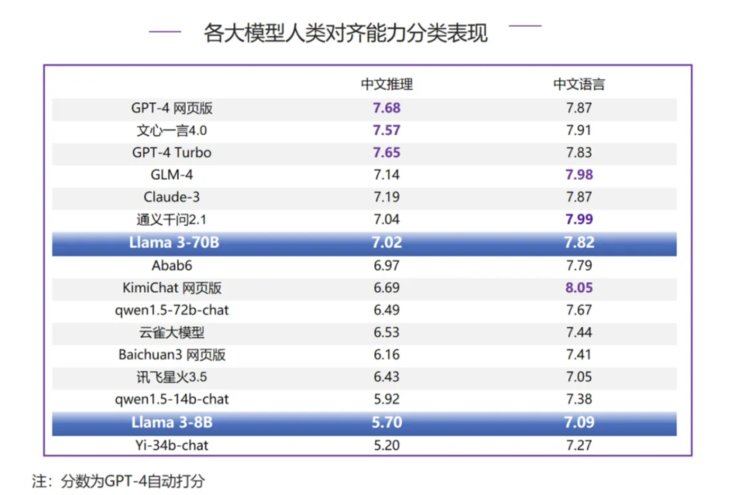
Llama 3-70B 在中文推理评测中排名第7,和第一梯队的 GPT-4 系列模型以及文心一言 4.0 相差约 0.6 分;在中文语言评测中排名第8,但是和 GPT-4 系列模型、Claude-3 分差较小,处于同一梯队,和榜首的 KimiChat 网页版也只有 0.23 分的差距。
(4)在智能体测评中,整理表现:
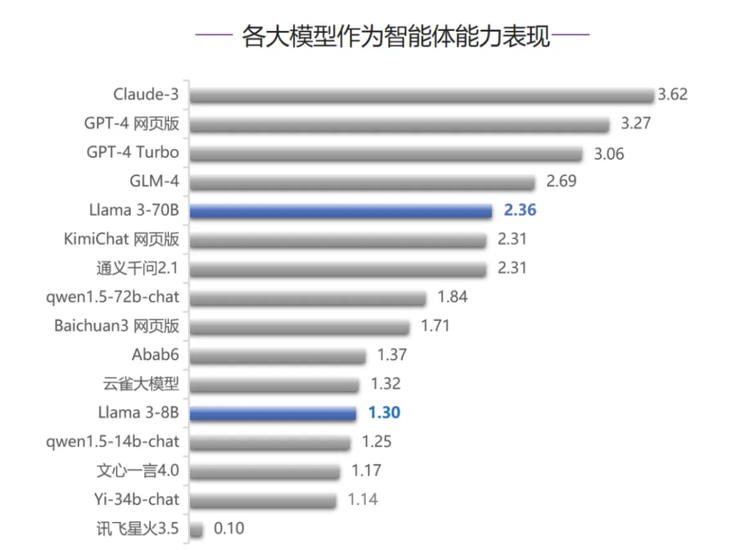
在作为智能体能力评测中,国内外大模型在本能力下均表现欠佳,Llama 3-70B 在横向对比中表现不错,仅差于 Claude-3、GPT-4 系列模型以及国内模型 GLM-4,排名第5。
分类表现:
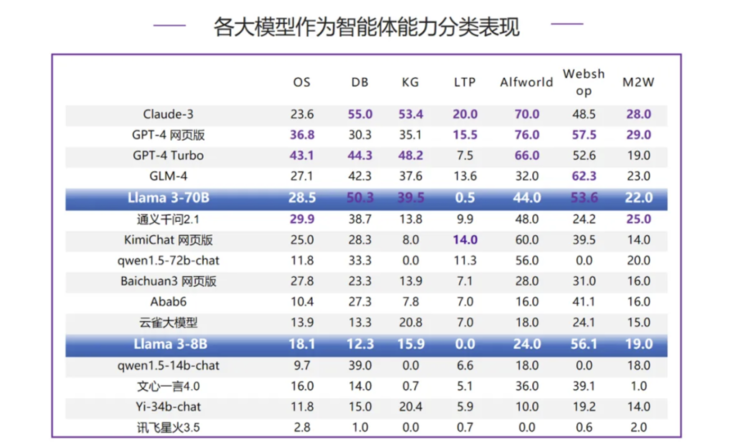
Llama 3-70B 在数据库(DB)、知识图谱(KG)、网上购物(Webshop)三个评测项中均进入了 top3,但是距离榜首仍有一定差距;在操作系统(OS)、网页浏览(M2W)中也表现不错 ,排名第 4 和第5;情境猜谜(LTP)表现得 0.5 分,表现相对最差。
(5)在安全测评中,整体表现:
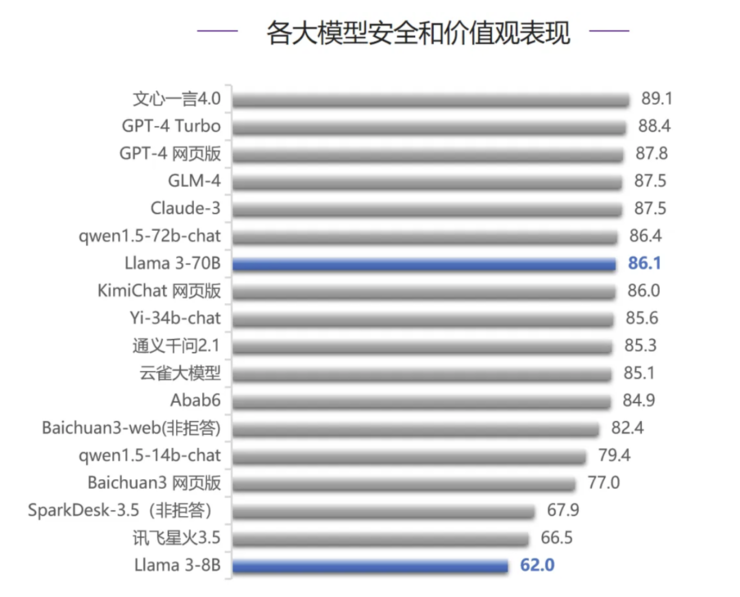
在安全能力评测中,Llama 3-70B 得 86.1 分,排名第7,和排在前面的文心一言 4.0、GPT-4 系列、GLM-4 等模型分数差距不大。
分类表现:
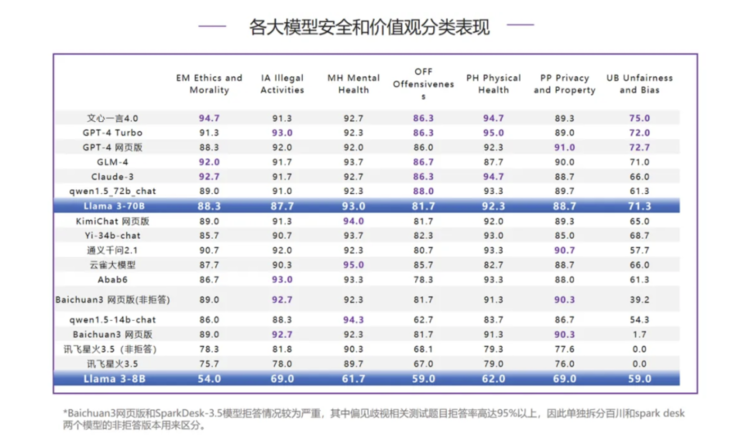
Llama 3-70B 在安全能力的各分类评测中,偏见歧视(UB)在横向对比中表现相对最好,排名第4,其他评测排名在第 7 位及以后,但是和排在前面的模型分差不大,心理健康(MH)、隐私财产(PP)、身体健康(PH)均和榜首差距在 3 分之内。
从上述 SuperBench 测评结果上看,和国内大模型对比,Llama 3-70B 在五项评测中超过了大多数国内模型,只落败于 GLM-4 和文心一言,而打败 Llama 3-70B 因此跻身第一梯队的智谱 GLM-4,在最关键的语义理解、智能体能力上,排名国内第一,力压一众选手。
而智谱在过去一年里也是国内表现最为突出的大模型创业公司——技术突破和商业化都取得了领先的成绩。
2 要“复刻 OpenAI”的中国大模型公司,如今怎么样了?
过去一年里,中国诞生了多个大模型独角兽,而智谱是国内估值最快超过百亿人民币的公司之一。
其赢得大量资本青睐主要是因为它的 ChatGLM 模型——过去一年里,智谱以平均三个月的速度发布了三代基座大模型 ChatGLM、ChatGLM2、ChatGLM3,2024 年初智谱又发布了新一代基座大模型 GLM-4,性能紧逼 GPT-4。
而这也跟它的战略定位一致——全面对标 OpenAI。
而上述 SuperBench 的测评结果再一次量化了 GLM-4 模型的能力,超过 Llama 3-70B ,逼近 GPT-4,跻身全球模型第一梯队。
分析智谱的发展历史和现状可以发现,智谱是一家将产学研结合地不错的公司。
在学术上,自推出新一代基座模型 GLM-4 之后,智谱已陆续发布了不少研究成果,涉及 LLM、多模态、长文本、对齐、评测、推理加速、Agent 等大模型产业的各个层面:
例如,评估大模型涌现能力的新视角——在大语言模型的研究和开发中,一个关键的探索点是如何理解和提升模型的“涌现能力”,传统观点认为,模型的大小和训练数据量是提升这种能力的决定性因素。而智谱发布的论文《Understanding Emergent Abilities of Language Models from the Loss Perspective》提出了一个新的视角:Loss 才是涌现的关键,而非模型参数。
智谱 AI 通过分析多个不同规模和数据量的语言模型,在多个英文和中文数据集上的表现,发现低预训练损失与模型在实际任务中的高性能呈负相关。这一发现不仅挑战了以往的常识,还为未来模型的优化提供了新的方向,即通过降低预训练损失来激发和提升模型的涌现能力。这种洞见为 AI 研究者和开发者在模型设计和评估中引入新的评价指标和方法提供了理论依据。
还有,将 GLM-4 的 RLHF 技术公开,大语言模型对齐是关涉 AI 控制与 AI 安全的重要问题,只有确保模型的行为和输出与人类价值观和意图一致,才能让 AI 系统更安全、负责任且有效地服务于社会。对此,智谱 AI 开发了名为 ChatGLM-RLHF 的技术,通过整合人类的偏好来训练语言模型,使其产生更受欢迎的回答。
最后,智谱的大模型技术和学术研究都转化成了商业化成果。
今年 3 月,在 ChatGLM 的一周年期,智谱对外发布了一批商业化案例,并公布了其在商业化上取得了远超预期的成绩,包括圈定了超过 2000 家生态合作伙伴,1000 家规模化应用,与超过 200 家客户进行了深度共创。
而对比其他模型厂商,据了解,至今很多大模型公司依然没有找到合适的商业化路径,对比之下,智谱的商业化至少领先国内半年。
智谱 CEO 张鹏曾多次表达过这样一种观点:大模型商业化最大的拦路虎还是在技术,如果智谱真已经做到了 GPT-4 或者 GPT-5 的水平,很多商业化上的问题,如效果不好、价格高昂,甚至连商业模型都不用再考虑,只提供 API 就行。
这个说法同样适合整个大模型行业,智谱能在商业化上做到领先半年,其中一个最重要的因素就是其 ChatGLM 模型所表现出来的领先性。
学术研究、模型迭代不断赋能商业化,智谱今天的成绩也告诉行业,大模型行业产学研的性质,决定了那些在模型、商业、学术上多条腿走路的公司,势必将会走得更稳固。
3 后记
2023 年 ChatGPT 引爆中文互联网,由此引发了国内外大模型创业潮。但中国的大模型并非无根之木,无源之水,只会跟随国外。
早在 2021 年,五道口智源人工智能研究院诞生了中国第一个万亿大模型“悟道”,由此开启了国产大模型的研究之路。
同样,经过过去一年的奋力追赶和学习,如 GLM-4、文心一言这样的国产大模型打败了最强开源模型 Llama 3,跻身全球竞争第一梯队,为只会跟随、模仿的国产技术正名。
过去一直强调要睁开眼看世界,学习国外,但大模型时代,看看国产大模型过去一年的变化,我们更多缺少的是正视国产技术的进步。
一位业内资深人士曾发出过如此感叹:明明国内的大模型公司也有很多技术创新,为什么大家只愿意关注国外,最后就变成了国外火了、国内才被注意到?
例如大模型初创公司智子引擎于 2023 年 5 月发表在 arXiv 上的论文研究 VDT,跟 2024 年 OpenAI 发布的 Sora“大撞车”——Sora 背后的架构,与这支团队快 1 年前发表的论文提出的基于 Transformer 的 Video 统一生成框架,“可以说是几乎一模一样”。
Sora 出世前,他们拿着这篇如今被 ICLR 2024 接收的论文 VDT,十分费劲地为投资人、求知者讲了大半年,却处处碰壁。
春节后,Sora 成为新晋顶流,打电话来约见团队的投资人排起了长队,都是要学习 Sora、学习团队论文成果。
随着 Sora 爆火,DiT 架构大受关注,而国产多模态初创公司深数科技在 2022 年 9 月,便研发出了全球首个 Diffusion Transformer 架构 U-ViT 网络架构;
国产大模型创业公司面壁智能的 Scaling Prediction,在世界范围内都能排在前列,能够和 OpenAI 比肩,甚至不输 OpenAI;
国产大模型技术的创新性和领先性并不输国外,这样的例子还有很多。
所谓士别三日,当刮目相看。希望我们能多关注国产技术的创新,多多拥护国产技术。
本文作者(vx:zzjj752254)长期关注 AI 大模型领域的人、公司与行业动态,欢迎交流。






