近日,在比利时举办的 ITF World 2024 大会上,AMD 董事长兼 CEO 苏姿丰获得了 IMEC 创新大奖,以此表彰其在行业创新与领导方面的成就,大家熟悉的戈登·摩尔(提出著名的摩尔定律)和比尔·盖茨都曾经获得该大奖。

图源:tomshardware
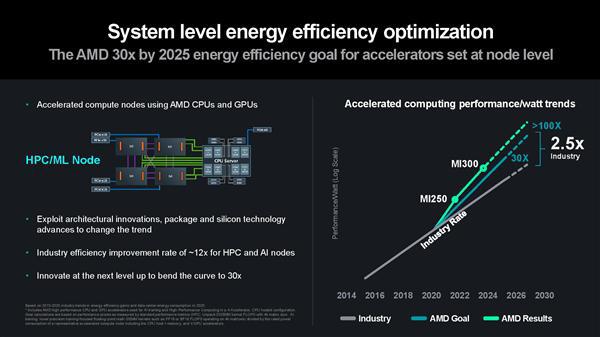
而在获奖后的演讲中,苏姿丰透露了 AMD 未来三年的计划,一个充满野心的计划:AMD 正在努力实现 2025 年将计算能效提高到 2020 年的 30 倍的计划,而在这个计划之后,还有在 2027 年将能效提高到 100 倍(相对于 2020 年)的目标。
图源:AMD
计算能效,简单来说就是指计算机在执行计算任务时,利用能源的有效程度,虽然在各种算力、核心数等性能参数面前,计算能效看起来不太起眼,实质上却是核心性能、功耗管理、制程工艺等技术的体现。
更高的计算能效,能够让计算机系统在运行时有着更高的效率,早在 2014 年,AMD 就曾经设定过一个名为“25x20”的计划,希望用 6 年时间将 AMD 的处理器、显卡等产品的能效提高 25 倍。
这个计划的结果,就是我们现在所熟知的 Zen 架构和 RDNA 架构,凭借两个架构的出色表现,AMD 在 2020 年不仅完成了既定的目标,还超额做到了 31.77 倍的能效提升。
AMD 为何一直将计算能效提升作为核心目标之一?首先,我们从目前的 AI 运算需求出发,看看计算能效提升会带来什么?
狂奔的超级计算中心
众所周知,AI 已经成为当前半导体业界最核心、最庞大的需求,这个需求正在驱动着半导体战车的车轮滚滚向前。前段时间,作为 AI 时代的领航者,半导体公司英伟达的市值就一度达到 2.62 万亿美元,甚至超过了德国所有上市公司的市值总和。
让英伟达市值暴涨的唯一原因,就是其在 AI 计算硬件领域的统治级实力,目前全球最顶尖的专业计算卡均出自英伟达,除了主流的 H100、H200 等芯片外,英伟达前段时间又发布了 GB100 和 GB200,仅单个芯片的算力就相当于以前的一台超级计算机。

图源:英伟达
当然,强大的算力背后并不是没有代价的,H100 的 TDP 高达 700W,而最新的 GB200 的 TDP 更是高达 2700W。而英伟达提供的官方方案中,单个 GB200 NVL72 服务器就可以搭载最高 36 个 GB200 芯片,仅芯片本身的功耗就最高可达 97200W,并且不包括配套的其他硬件功耗。
这还仅仅是开始,一个超级计算中心往往由多个服务器单元组合而成,亚马逊此前就公布了一项计划,预计采购 2 万个 GB200 用来组建一个全新的服务器集群。而走在 AI 研究最前沿的微软和 OpenAI,前段时间更是公布了一个雄心勃勃的计划——星际之门。
据悉,该计划共分为五个阶段,目的是建造一个人类历史上最大的超级计算中心,预计整个计划的投资将达到 1150 亿美元,建成后将需要数十亿瓦的电力支持。这座‘星际之门’建成后,仅以耗电量算就足以在全球各大城市中排名前 20,更何况它还只是众多计算中心的一员而已。

实际上,早在去年开始,就有多份报告指出计算中心的耗电量正在猛增,并且一度导致美国部分城市出现电力供应不足的问题。从能源角度来说,一座发电厂从选址到建成运行,往往需要数年的时间,如果遇到环保组织的抗议,还有可能拖延更久。
在能源问题短时间内无法解决的情况下,提高计算能效就是唯一的方法,通过更高效地利用每瓦时电力来维持更大规模的 AI 模型训练。实际上,有人认为 OpenAI 的 ChatGPT-5 进展缓慢,很大程度上就是受限于算力规模无法大幅度提升。
苏姿丰在演讲中也提到,提高计算能效可以更好地解决能源与算力之间的矛盾,并且让超级计算中心可以被部署到更多的地方。在一些 AI 企业的构想中,未来每一座城市都应该拥有自己的超级 AI 中心,负责处理智能驾驶、城市安全等各方面的 AI 需求。
想要达成这个目标,同时不显著增加城市的能源负担,更高计算能效的显卡就是唯一的解决方案。而且,计算能效也直接关系到 AI 计算的成本,只有将 AI 计算的成本降到更低,大面积普及 AI 才可能成为现实。
AMD 的疯狂计划
在英伟达的刺激下,作为在 GPU 领域唯一能够与英伟达抗衡的企业,AMD 一直在加速推进旗下 AI 芯片的研发与上市进度,并先后发布了 MI300、V80 等多款专业运算卡。
据报道,为了能够加速 AI 芯片的进度,苏姿丰对 GPU 团队进行重组,抽调大量人员支持 AI 芯片的研发,以至于下一代的 AMD 消费级显卡发布计划受到严重影响,比如取消原定的旗舰产品发布计划,仅保留中端显卡的发布计划等。
在集中科研力量后,AMD 目前的进展速度飞快,最新的 MI300X 在性能上已经超过英伟达的 H100,大多 42 petaFLOPs,并且拥有高达 192GB 的显存,功耗却与 H100 相当,仅为 750W。

图源:AMD
凭借优异的计算能效,MI300X 成功引起了市场的关注,微软、OpenAI、亚马逊等科技巨头都提交了采购需求,让 AMD 在计算领域的芯片出货量暴增。根据相关机构预测,2024 年 AMD 的 AI 芯片出货量可能达到英伟达出货量的 10%,并在明年增长至 30%。
据苏姿丰介绍,为了能够提高芯片的计算能效,AMD 研发了多项新的技术,比如 2.5D/3D 混合封装技术。利用这项技术,AMD 可以在封装面积不变的前提下给芯片塞入更多的晶体管和内存,降低芯片与内存交换数据的消耗,有效提升每瓦时的计算性能。

图源:AMD
此外,AMD 还将改进芯片架构,推出能效更高的新一代架构,预计最快将于 2025 年发布,并实现 25x30(2025 年计算能效提升 30 倍)的目标。不过,想要实现 27x100(2027 年计算能效提升 100 倍)的目标,还需要在诸多领域做出提升,仅靠制程工艺升级和架构升级恐怕还不太够。
不得不说,AMD 的这个计划非常疯狂,一旦成功,那么 AMD 将有望再次与英伟达并肩而行。
那么英伟达的反应是什么?其实英伟达很早就给出了回应,早前发布的 GB200 就是答案,这颗史无前例的算力怪物在计算能效方面的提升同样瞩目。据英伟达的介绍,GB200 的推理性能是 H100 的 30 倍,计算能效是 H100 的 25 倍(综合考虑算力、功耗等参数后的结果)。
显然,英伟达的脚步也并不慢,在接下来的 3 年时间里,不管 AMD 能否完成疯狂的百倍计划,AI 芯片市场都会迎来一场革新。






