
新智元报道
编辑:LRS
【新智元导读】Aya23 在模型性能和语言种类覆盖度上达到了平衡,其中最大的 35B 参数量模型在所有评估任务和涵盖的语言中取得了最好成绩。
虽然 LLM 在过去几年中蓬勃发展,但该领域的大部分工作都是以英语为中心的,也就是说,虽然模型的能力很强,但也仅限于英语、汉语等使用人数多的语言,在处理资源匮乏的语言时往往性能不佳。
想要破局多语言,两个关键在于强大的多语言预训练模型以及足量的、涵盖多种语言的指令训练数据。
为了解决上述问题,最近,加拿大的独角兽 AI 公司 Cohere 开源了两种尺寸(8B 和 35B)的多语言模型 Aya23,其中 Aya-23-35B 在所有评估任务和涵盖的语言中取得了最好成绩。

论文链接:
https://cohere.com/research/papers/aya-command-23-8b-and-35b-technical-report-2024-05-23
Aya-23-8B: https://huggingface.co/CohereForAI/aya-23-8B
Aya-23-35B: https://huggingface.co/CohereForAI/aya-23-35B
覆盖的 23 种语言分别为阿拉伯语、中文(简体和繁体)、捷克语、荷兰语、英语、法语、德语、希腊语、希伯来语、印地语、印尼语、意大利语、日语、韩语、波斯语、波兰语、葡萄牙语、罗马尼亚语、俄语、西班牙语、土耳其语、乌克兰语和越南语。
作为 Aya 计划的一部分,Cohere 最初与来自 119 个国家的 3,000 多名独立研究人员一起创建了一个庞大的多语言指令数据集 Aya Collection,包含 5.13 亿个提示和补全样本,并用该数据训练了一个覆盖 101 种语言的语言模型 Aya 101,并于 2024 年 2 月开源。
但 Aya 101 模型的基础是 mT5,在知识和性能方面都已经过时了,并且 Aya 101 主要侧重于覆盖度,在某些特定语言的性能表现上不佳。
此次开源的 Aya-23 模型,其设计目标是在语言广度和深度上实现平衡,从本质上来讲,所有 Aya 系列的模型都基于 Cohere 的 Command 系列模型和 Aya Collection,但本次的重点是将更多容量分配给主要的 23 种语言,以改善目标语言的生成效果。
多语言模型 Aya 23
预训练模型架构
Aya 23 模型家族是一系列基于 Cohere Command 系列的预训练模型,模型在训练时使用了 23 种不同语言的文本数据;Aya-23-35B 是 Cohere Command R 模型的一个改进版本,经过了进一步的微调以提高性能。
模型采用了标准的 decoder-only Transformer 架构:
1. 并行注意力和前馈网络(FFN)层:类似于 PALM-2,使用并行块架构,在不损害模型质量的情况下,显著提高了训练效率,特别是在张量并行(TP)设置中,即在多个处理器或设备上同时训练模型的不同部分。
2. SwiGLU 激活函数:SwiGLU 比其他激活函数具有更高的下游性能,研究人员调整了前馈网络(FFN)层的维度,以保持与非 SwiGLU 激活函数相比大致相同数量的可训练参数。
3. 无偏置:从稠密层中移除了所有偏置项(bias),以提高训练稳定性。
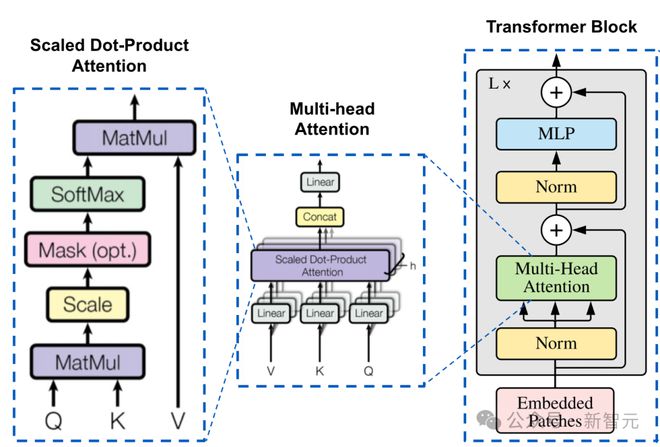
4. RoPE(旋转位置嵌入):可以帮助模型更好地理解和推断长文本中的上下文信息。RoPE 在处理短文本时也能提供比 ALiBi 等其他相对位置编码方法更好的性能。
5. 分词器:模型使用了一个大小为 256k 的字节对编码(Byte Pair Encoding, BPE)分词器。在分词过程中,执行了 NFC(Normalization Form C)规范化,即文本在分词前会被标准化,以确保一致性。数字被拆分成单独的 token,以便于模型更好地理解和处理数字信息。分词器是在预训练数据集的一个平衡子集上训练的,以确保不同语言的文本都能得到高效的表征。
6. 分组查询注意力(GQA):每个键值(KV)头与多个查询(Q)头共享,可以降低模型推理时内存的使用,提高效率。
指令微调
由于多语言指令数据相对稀缺,研究人员采用了多种策略来增强数据的可用性:
1. 多语言模板:利用结构化文本,将特定的自然语言处理(NLP)数据集转换成指令和回复对。用到数据集包括 xP3x 数据集和 Aya 数据集的样本,最终形成了一个包含 5570 万个样本的大型数据集合,覆盖了 23 种语言和 161 个不同的数据集。
2. 人工标注:Aya 数据集包含了由 65 种语言的母语者编写的 204,000 对人工策划的提示-响应对。我们从中筛选出我们训练模型所使用的 23 种语言的数据,得到了 55,000 个样本。
3. 翻译数据:使用了从广泛使用的英语指令数据集进行翻译的样本,从不同数据集、不同语言中随机抽取以保持多样性,最终数据包含了 110 万个样本。
4. 合成数据:使用了 ShareGPT5 和 Dolly-15k 的人工标注提示,不同的是,Aya 使用了 Cohere 的 Command R+ 为所有 23 种语言生成翻译后的 ShareGPT 和 Dolly 提示的多语言响应,最终得到了 163 万个样本。
实验评估
判别式任务
研究人员使用了不同模型在 14 种语言上的多语言机器学习理解(MMLU)基准上进行测试,选用的语言是 Aya 23 系列模型所支持的多语言 MMLU 测试语言的一个子集。
是根据英语 MMLU 的测试标准,采用了5-shot 评估方法,与 zero-shot 未见任务相似的情况下,Aya-23-8B 模型在所有比较的较小模型中表现最佳,在所有测试的语言上平均准确率达到了 48.2%,并且在 14 种语言中的 11 种语言上取得了其类别中的最高分数。
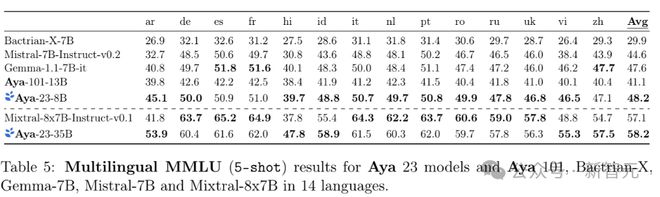
当对比更大尺寸的模型时,Aya-23-35B 模型在平均得分上超过了 Mixtral-8x7B-Inst 模型(分别为 58.2% 和 57.1%)。
尽管 Mixtral 在资源丰富的语言上表现略好,但 Aya-23-35B 在非欧洲语言上的表现尤为突出,例如在阿拉伯语、印地语和越南语上,Aya-23-35B 的准确率分别提高了 12.1%、10.0% 和 6.5%。这表明 Aya-23-35B 在处理资源较少或非欧洲语言时,具有更强的性能。
多语言数学推理
在数学问题解决能力测试(MGSM)中,Aya 23 系列的模型在所有同类基线模型中表现最为出色,表明模型具备了在不同语言中进行强大数学推理的能力。
具体来说,Aya-23-8B 模型在 7 种语言上的平均得分高达 36.6 分,而同类中排名第二的 Gemma-1.1-7b 模型得分为 34.0 分。
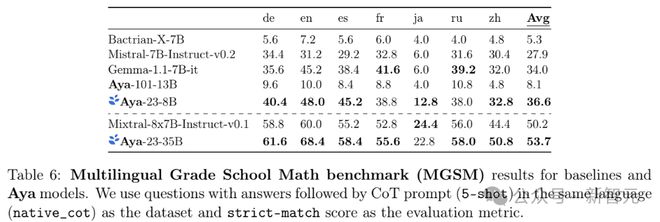
特别引人注目的是,Aya-23-8B 模型的性能是 Aya-101-13B 模型(得分 8.1 分)的 4.5 倍,这再次强调了高质量预训练模型的重要性。
对于规模更大的模型,Aya-23-35B 模型以 53.7 分的成绩超过了 Mixtral-8x7B-Instruct-v0.1 模型的 50.2 分。
在个别语言的得分方面,除了 Aya-23-8B 模型在法语和俄语上的得分,以及 Aya-23-35B 模型在日语上的得分之外,Aya 23 系列模型在每种语言上都超越了同类中最强的模型,表明 Aya 23 系列模型在解决数学问题的能力上普遍优于同类模型,尽管在某些特定语言上可能仍需进一步的优化。
生成式任务
研究人员还测试了 Aya 23 系列模型在 23 种语言与英语配对的翻译任务(FLORES),以及 15 种语言的摘要任务(XLSum)。
在评估基准中,Aya 23 系列模型的表现明显优于其他相似规模的模型。
具体来说,Aya-23-8B 模型在翻译任务中的平均 spBleu 得分为 37.2,比排名第二的 Aya-101-13B 模型高出 4 分;在摘要任务中,Aya-23-8B 和 Aya-101-13B 模型的平均 RougeL 得分为 27.5,比下一个最佳模型 Gemma-1.1 高出 14.5 分。
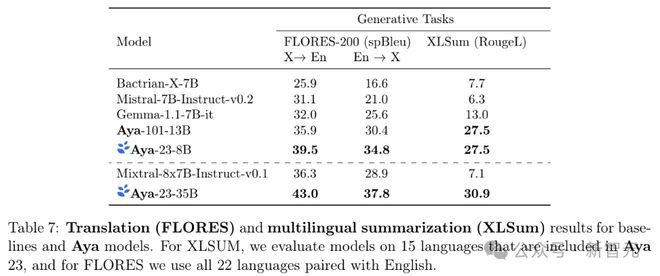
在大型模型的对比中,Aya-23-35B 在翻译任务中以 7.8 分(40.4 vs 32.6)的 spBleu 得分优势超越了 Mixtral-8x7B,在摘要任务中则以 23.8 分(30.9 vs 7.1)的优势超越。
还可以注意到,Mistral-7B 和 Mixtral-8x7B 模型倾向于在提示中生成英语回复,也导致了模型在多语言摘要任务中的性能不佳。
参考资料:






