
允中发自凹非寺
量子位公众号 QbitAI
无需采集 3D 数据,也能训练出高质量的 3D 自动驾驶场景生成模型。
这是来自香港中文大学、香港科技大学和华为诺亚方舟实验室的最新研究成果——针对自动驾驶街景的可控 3D 场景生成方法“MagicDrive3D”。
此前,采用常见的 2D 自动驾驶数据集来生成 3D 街景的方法不是没有,但受采集角度所限,生成结果的可控性和几何一致性无法同时满足。而现在,MagicDrive3D 通过结合可控生成与场景重建解决了这一限制。
不仅支持多条件控制,还突破了原始数据的局限,即使在原始图像不一致的情况下,也能建立出连贯的高质量模型。

即使场景中有很多物体,生成结果依然真实可靠:

而且支持天气情况的文本控制,可以一键从晴天切换到雨天:

道路结构、物体位置都能够精确控制(随机保留 50% 车):

还可以一键实现白天与夜晚的转换(随机保留 25% 车):

总之,这项成果解决了自动驾驶等无边界场景下 3D 场景的高质量模型开发难题,可以有效帮助 BEV 分割等下游感知任务。
常规驾驶数据即可实现可控场景生成
3D 自动驾驶场景生成应用广阔,然而目前 3D 资产的生成方法通常局限于以物体为中心的生成场景,对于自动驾驶中无界限的大场景生成缺乏探索。
但从应用的角度来说,可控的生成方法在下游应用中价值更高,针对这个痛点,MagicDrive3D 提出了一种新颖的框架,在常规的自动驾驶数据集上即可训练出 3D 场景生成模型,而且支持多种条件控制!
MagicDrive3D 继承了前一代 MagicDrive 诸多优点,其多条件控制可以实现场景、背景和前景的多层次街景图像编辑,用来生成更多的自动驾驶 3D 场景。

△MagicDrive3D 的多视角渲染能力
而且生成的场景支持多相机视角的渲染,例如全景图渲染:

在目前应用最广泛的 nuScenes 数据集上,MagicDrive3D 在视频生成和场景生成两方面相比于 baseline,均表现出明显优势。
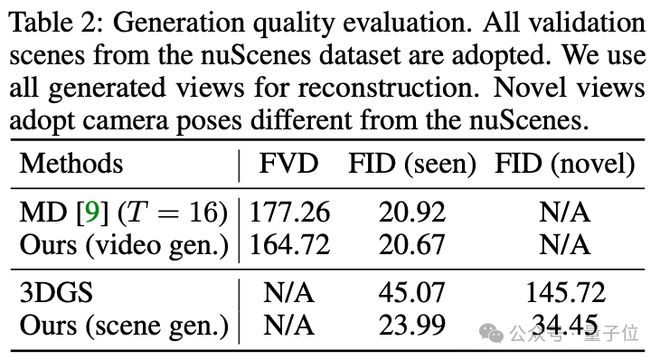
△MagicDrive3D 的生成效果评估
此外,MagicDrive3D 生成的图片还可以直接用于数据增强,可以在 BEV 分割任务中提升相机参数的鲁棒性。
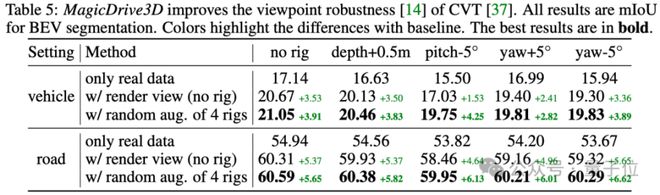
△MagicDrive3D 的生成数据在下游任务的效果
那么,MagicDrive3D 究竟是如何做到的呢?
先合成,再重建
随着扩散模型的发展,图片、视频生成的方法层出不穷,但是受限制于现有的数据采集形式,这些方法只能生成固定的相机视角,对场景几何缺乏建模(geometry-free),因而无法拓展到更多视角。
能够支持多视角的重建方法,虽然能够提供几何一致性的保证(geometry-focused),却又受到了真实采集的数据(静态、多视角数据)的限制,常见的自动驾驶数据集根本无法满足这些要求。
为了填补这部分空白,MagicDrive3D 提出了一个将视角合成方法与场景重建方法相结合的框架。
该框架充分利用前者的可控性以及后者的几何一致性,实现了接受多种控制条件的 3D 街景场景合成。

△MagicDrive3D 的方法框架
具体来说,MagicDrive3D 首先训练了一个细粒度可控的视频生成模型,不仅能够通过语义信息控制,视频中每个视角的相机参数都经过统一坐标系编码,使得生成的多视角视频具备更强的几何一致性。
接着,为了提供更强的几何一致性保证以及多视角渲染,MagicDrive3D 提出可形变的高斯泼溅作为场景的 3D 表征,结合单目深度点云进行重建。
最终得到的驾驶场景能够合理的反应各种控制条件,并且支持任意相机视角的精确渲染。
总的来说,MagicDrive3D 带来了一个全新的、高效的可控 3D 场景生成框架,不仅成功解决了无界限的 3D 场景生成难题,其可控性更为多种下游任务提供了支持。
相比前序工作 MagicDrive,MagicDrive3D 不仅提供了多视角渲染能力,生成的场景几何信息也为更多样的场景编辑提供可能。
随着质量和真实性的提升,生成数据将得到更广泛的应用,为自动驾驶技术的发展注入更多活力。
论文地址:
https://arxiv.org/abs/2405.14475
项目主页:






