西风发自凹非寺
量子位公众号 QbitAI
OpenAI 研究如何破解 GPT-4 思维,公开超级对齐团队工作,Ilya Sutskever也在作者名单之列。
该研究提出了改进大规模训练稀疏自编码器的方法,并成功将 GPT-4 的内部表征解构为 1600 万个可理解的特征。
由此,复杂语言模型的内部工作变得更加可理解。

其实,早在 6 个月前,研究就已经开始进行了:
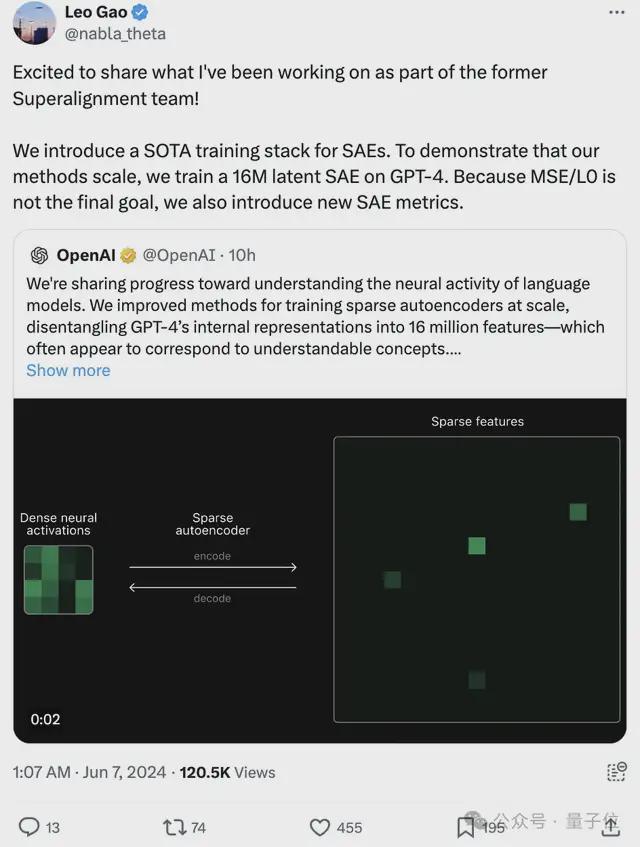
OpenAI 将其公开后,前超级对齐团队成员、论文一作前来转发分享:
我们引入了一种基于 TopK 激活函数的新稀疏自编码器训练技术栈,消除了特征缩减问题,并允许直接设置 L0。
我们发现这种方法在均方误差/L0 边界上表现良好。即使在 1600 万的规模下,也几乎没有失活的潜在单元(latent)。
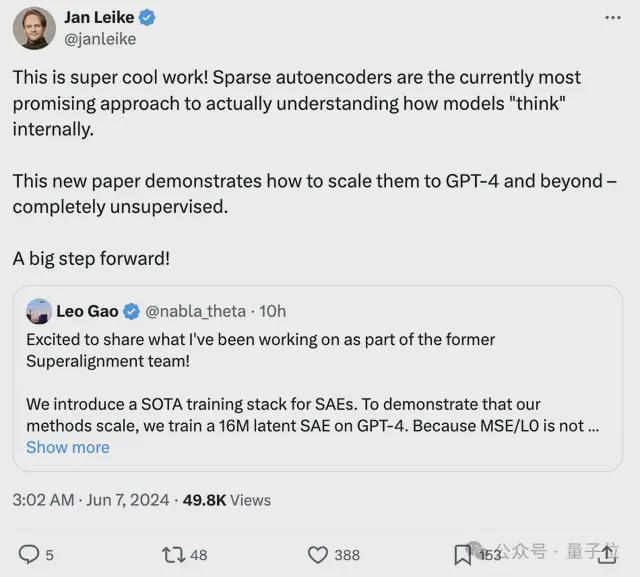
同样在坐着名单里的、此前在 OpenAI 超级对齐团队的 Ilya 同盟Jan Leike(就是从 OpenAI 愤而离职刚刚加入 Anthropic 的 RLHF 发明者之一)也表示:
这是一项重大的进步!稀疏自编码器是目前用来真正理解模型内部思维的最好的方法。
更有意思的是,不久前 Anthropic 发了一项类似的工作。
成功从 Claude 3.0 Sonnet 的中间层提取了数百万个特征,为其计算过程中的内部状态提供了一个大致的概念性图。

于是有网友就开麦了,工作牛是牛,但 OpenAI 是不是有点太着急了,论文链接没有指向 Arxiv,分析似乎也没有那么深入。
是不是为了回应 Anthropic 的研究以及 Jan Leike 出走的事儿,谁知道呢?(doge)

回归正题,OpenAI 超级对齐团队是如何想法子破解 GPT-4 思维的?
在 OpenAI 新公布研究中再见 Ilya 的名字
目前,语言模型神经网络的内部工作原理仍是个“黑盒”,无法被完全理解。
为了理解和解释神经网络,首先需要找到对神经计算有用的基本构件。
然鹅,神经网络中的激活通常表现出不可预测和复杂的模式,且每次输入几乎总会引发很密集的激活。而现实世界中其实很稀疏,在任何给定的情境中,人脑只有一小部分相关神经元会被激活。

由此,研究人员开始研究稀疏自编码器,这是一种能在神经网络中识别出对生成特定输出至关重要的少数“特征”的技术,类似于人在分析问题时脑海中的那些关键概念。
它们的特征展示出稀疏的激活模式,这些模式自然地与人类易于理解的概念对齐,即使没有直接的可解释性激励。
不过,现有的稀疏自编码器训练方法在大规模扩展时会面临重建与稀疏性权衡、latent 失活等问题。
在 OpenAI 超级对齐团队的这项研究中,他们推出了一种基于 TopK 激活函数的新稀疏自编码器(SAE)训练技术栈,消除了特征缩小问题,能够直接设定 L0(直接控制网络中非零激活的数量)。
该方法在均方误差(MSE)与 L0 评估指标上表现优异,即使在 1600 万规模的训练中,几乎不产生失活的潜在单元(latent)。
具体来看,他们使用GPT-2 small和GPT-4系列模型的残差流作为自编码器的输入,选取网络深层(接近输出层)的残差流,如 GPT-4 的5/6 层、GPT-2 small 的第 8 层。
并使用之前工作中提出的基线ReLU 自编码器架构,编码器通过 ReLU 激活获得稀疏 latent z,解码器从z中重建残差流。损失函数包括重建 MSE 损失和 L1 正则项,用于促进 latent 稀疏性。
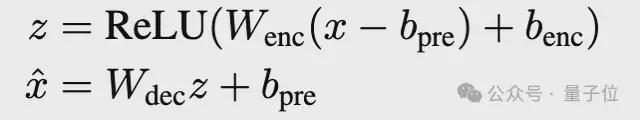
然后,团队提出使用 TopK 激活函数代替传统 L1 正则项。TopK 在编码器预激活上只保留最大的k个值,其余清零,从而直接控制 latent 稀疏度k。
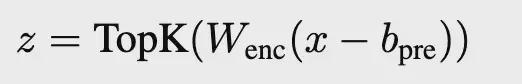
不需要 L1 正则项,避免了 L1 导致的激活收缩问题。实验证明,TopK 相比 ReLU 等激活函数,在重建质量和稀疏性之间有更优的权衡。
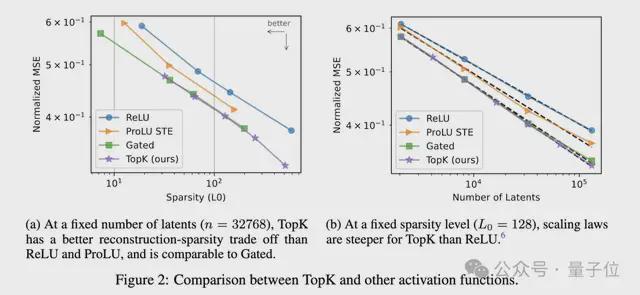
此外,自编码器训练时容易出现大量 latent 永远不被激活(失活)的情况,导致计算资源浪费。
团队的解决方案包括两个关键技术:
- 将编码器权重初始化为解码器权重的转置,使 latent 在初始化时可激活。
- 添加辅助重建损失项,模拟用 top-kaux 个失活 latent 进行重建的损失。
如此一来,即使是 1600 万 latent 的大规模自编码器,失活率也只有7%。
团队还提出了多重 TopK 损失函数的改进方案,提高了高稀疏情况下的泛化能力,并且探讨了两种不同的训练策略对 latent 数量的影响,这里就不过多展开了。
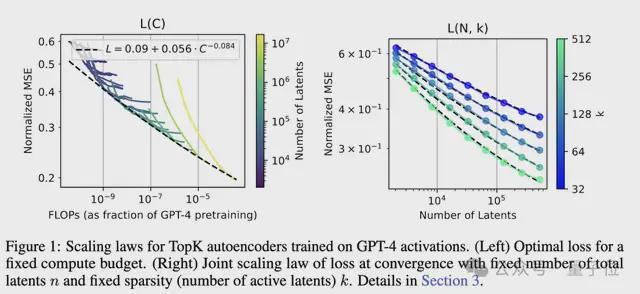
为了证明该方法的可扩展性,团队训练了上述提到的一个具有 1600 万个 latent 的稀疏自编码器,并在 GPT-4 模型的激活上处理了 40 亿个 token。
在 GPT-4 激活上处理 40 亿 token
接下来,评估自编码器质量的关键在于提取出的特征是否对下游应用任务有用,而不仅仅是优化重建损失和稀疏性。
因此,团队提出了几种评估自编码器质量的新方法,包括:
- 下游损失(Downstream Loss):评估自编码器重建的 latent 对语言模型性能的影响。
- 探测损失(Probe Loss):检查自编码器是否能够恢复我们认为可能发现的特征。
- 可解释性(Explainability):评估自编码器 latent 的激活是否能够通过简单且精确的解释来理解。
- 剔除稀疏性(Ablation sparsity):评估移除个别 latent 对下游预测的影响。
实验发现,TopK 自编码器在下游损失上的改进幅度超过了重建 MSE 的改进。
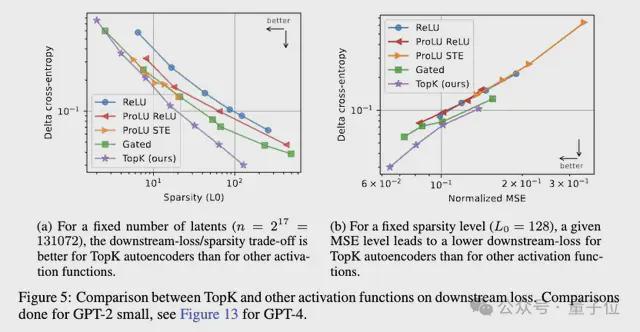
探测损失随 latent 数量增加而改善,但在某些区间会先升后降。

此外,研究人员发现精确度和召回率在 latent 数量较大、稀疏度适中时最优。
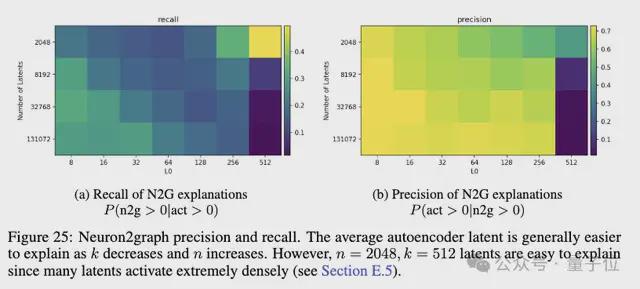
TopK 模型相比 ReLU 模型有更高的召回率,能更好地压制虚假激活。
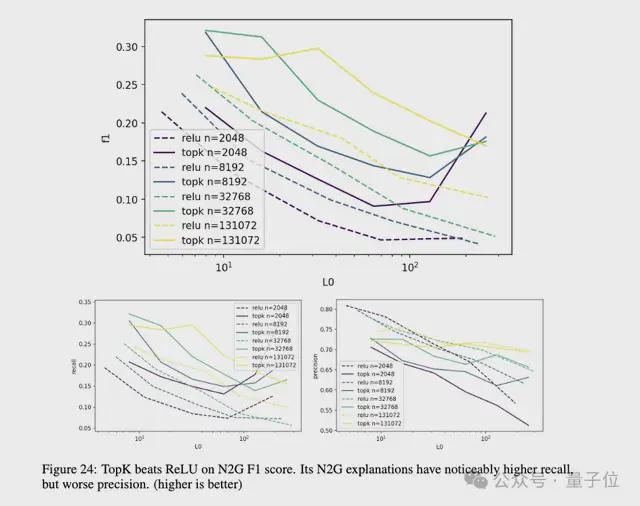
剔除稀疏性方面(见上图 6 b),团队发现自编码器 latent 的影响较为稀疏,远小于直接 ablating 残差流通道。但当稀疏度k过高时,影响的稀疏性会下降。
最后,论文一作表示稀疏自编码器的问题仍然远未解决,这项研究中的 SAE 只捕获了 GPT-4 行为的一小部分,即使看起来单义的 latent 也可能难以精确解释。而且,从表现优异的 SAE 到更好地理解模型的行为,还需要大量的工作。
关于这项研究的更多细节,感兴趣的家人可以查看原论文。
OpenAI 还公开发布了完整源代码和针对 GPT-2 的多个小规模自编码器模型权重。还发布了一个在线可视化工具,用于查看包括这个 1600 万 latent GPT-4 自编码器在内的多个模型的激活特征。
OpenAI 的:https://cdn.openai.com/papers/sparse-autoencoders.pdf
Anthropic 的:https://transformer-circuits.pub/2024/scaling-monosemanticity/index.html
参考链接:
[1]https://x.com/OpenAI/status/1798762092528586945
[2]https://openai.com/index/extracting-concepts-from-gpt-4/
[3]https://news.ycombinator.com/item?id=40599749
[4]https://x.com/janleike/status/1798792652042744158
[5]https://openaipublic.blob.core.windows.net/sparse-autoencoder/sae-viewer/index.html






