
出品|网易科技《态度》栏目
作者|薛世轩
编辑|丁广胜
如果说高考语文作文题所考察的文字功底是各家大模型的入门基本功的话,那么数学的难度 Level 就更考验大模型的图像识别与分析能力了。毕竟曲线题、导数题、函数题、几何题可不是什么善茬。(这可能也是为什么很少有人在网上讨论数学题的原因了)

因此,我们测试了 GPT-4o、kimi、文心一言、讯飞星火大模型、百小应、通义千问、360 大模型、豆包这 8 款目前市面上主流的几款大模型,看看它们遇到“硬茬”时又会作何表现呢?
为了更全面的考察大模型的综合性能,我们分别选取了数学I卷的一道立体几何题和一道函数题,以考察大模型的空间理解能力和逻辑推理能力,以下为具体考题:
立体几何题:
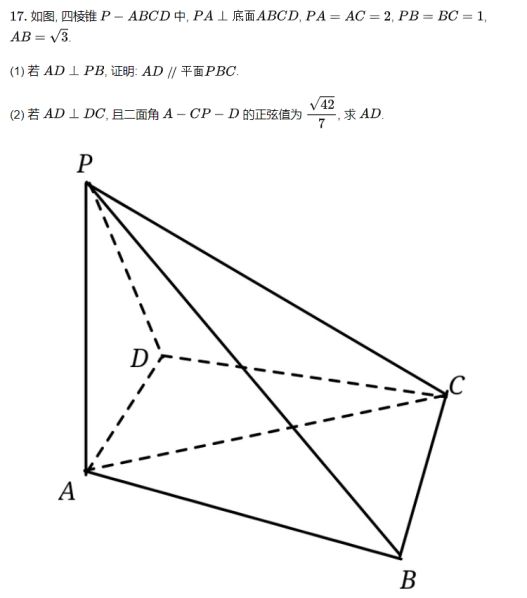
函数题:

(下文各图左侧为立体几何题,右侧为函数题)
GPT-4o

Kimi
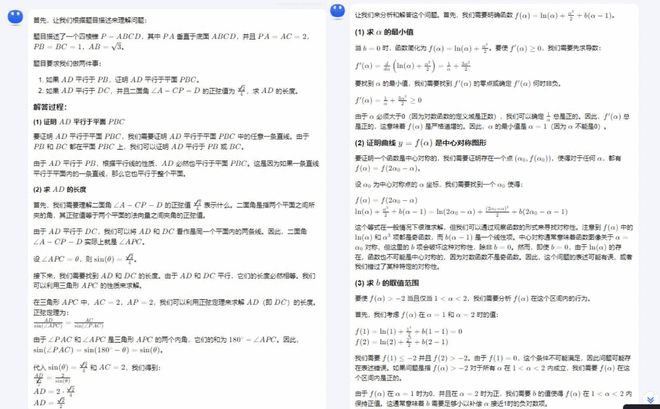
文心一言

讯飞星火大模型

百小应

通义千问

360 智脑

豆包

以上就是所有 8 款大模型在作答今年高考数学I卷的表现,可以发现,尽管大模型们在今年历经多次迭代,但在本次测试中的表现并不尽如人意,且关于同一道题目所给出的答案也不尽相同。

除此之外,GPT-4O 则使用全英文答题;通义千问在作答函数题时出现了“bug”现象,对同一函数式开始无限循环;豆包甚至由于 tokens 用尽出现了无法进行完整作答;文心一言也对题干信息理解错误……
由此可见,不仅是考生们直呼今年数学“太难了”“裂开了”,就连大模型们的发挥也不如预期中的优秀。
但无论今天考的怎样,高考第一天已经结束,考生们要做的就是放松心情,全力准备明天的考试,网易科技也祝考生们金榜题名!






