
新智元报道
编辑:Mindy
从大规模网络爬取、精细过滤到去重技术,通过 FineWeb 的技术报告探索如何打造高质量数据集,为大型语言模型(LLM)预训练提供更优质的性能。
大型语言模型(LLMs)的性能在很大程度上取决于它的预训练数据集的质量和大小。
然而,像 Llama 3 和 Mixtral 这样最先进的 LLMs 的预训练数据集并不公开;关于它们是如何创建的,我们知之甚少。
近日,Hugging Face 上的一个团队发布了 FineWeb 数据集,这是一个用于 LLM 预训练的新型大规模(15 万亿个 tokens,44TB 磁盘空间)数据集。
同时,他们还通过技术报告详细介绍了该数据集的加工决策过程:FineWeb 源自 96 个 CommonCrawl 快照,它是如何通过缜密的去重和过滤策略,比其他开放预训练数据集产生了表现更好的 LLM 的。
创建数据集的准备工作
开始创建数据集的第一步,需要考虑的问题是如何获取到大规模的数据。
Common Crawl 这个非营利组织自 2007 年以来一直在爬取网络数据,并且每 1 到 2 个月发布一次新的爬取,包含 200 到 400 TiB 的文本内容。
于是,Common Crawl 就作为了 FineWeb 数据集的起点。
其次,由于涉及的数据量巨大,需要一个模块化且可扩展的代码库来快速迭代处理决策并适当地并行化工作负载,同时提供对数据的清晰洞察。
为此,该团队开发了 datatrove,这是一个开源数据处理库,能够将过滤和去重设置无缝扩展到数千个 CPU 核心。
在创建数据集时,需要考虑的主要问题是什么是“高质量”的数据。
一种常用的方法是在数据集的一个代表性子集上训练小型模型,并在一组评估任务上评估它们。
研究者在两个版本的数据集上训练了两个结构相同的模型,一个经过额外处理步骤,另一个没有,以此来比较数据处理步骤对模型性能的影响。
他们选用了 Commonsense QA、HellaSwag、OpenBook QA 等基准测试来评估模型,并限制较长基准测试的样本量以避免过度拟合,确保模型评估结果的可靠性和泛化能力。
数据集是怎么去重和过滤的
下图概括了 FineWeb 数据集生成的主要步骤:
URL 过滤→文本提取→语言过滤→Gopher 过滤→MinHash 去重→C4 过滤器→自定义过滤器→PII(个人身份信息)移除
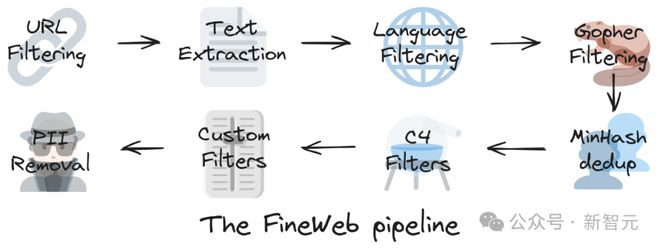
本文主要介绍去重和过滤的部分,因为对于创建高质量数据集来说,这两个步骤对于提高模型性能、增加数据多样性和清洁度方面至关重要。
数据去重
网络中存在许多聚合器、镜像站点或模板化页面,这些都可能导致内容在不同域名和网页上重复出现。
去除这些重复内容(去重)已被证明可以提高模型性能,并减少对预训练数据的记忆,这有助于模型更好地泛化。
研究者采用了 MinHash 这种基于模糊哈希的去重技术,因为它可以有效地扩展到许多 CPU 节点,并可以调整相似性阈值(通过控制 bucket 的数量和大小)以及考虑的子序列长度(通过控制n-gram 大小)。
研究者拆分每个文档为5-gram,使用 112 个哈希函数计算 minhashes。
112 个哈希函数被分成 14 个 bucket,每个 bucket 有 8 个哈希,目的是定位至少 75% 相似的文档。
在任何 bucket 中具有相同 8 个 minhashes 的文档被认为是彼此的重复。
需要注意的是,研究者发现一个奇怪的现象:虽然去重后数据量少了很多(比如最旧的数据包,去重后只剩下了原来 10% 的内容),但用这些去重后的数据去训练模型的时候,模型的表现并没有变好,甚至比之前用没有去重的数据训练的模型还要差。
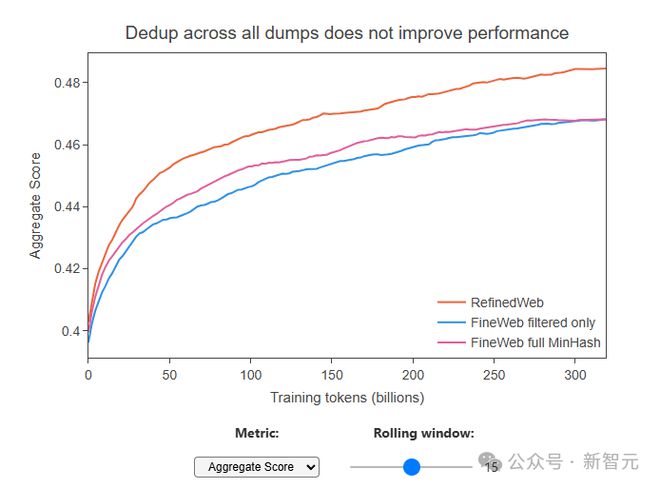
在所有数据包上进行去重并没有提高性能
这说明,有时候去重去得太狠了,可能把一些有用的内容也给去除了,留下的那些内容反而质量不高。
这也提醒我们,需要找到一个平衡点,既要去除重复、低质量的数据,也要保留足够的、有价值的信息。
为了改进去重方法,研究者尝试了一种新策略:对每个单独的数据包使用 MinHash 技术进行独立的去重,而不是将所有数据包合并在一起去重。
通过这种方式,平衡了每个重复次数较多的集群和重复次数较少的集群之间的分布差异,让去重更加的「温和」。
数据过滤
首先介绍一下 C4 数据集,这是一个大型语言模型(LLM)训练的常用数据子集,它在 Hellaswag 基准测试中表现十分出色。
FineWeb 的研究者首先参照 C4 的过滤策略,先是匹配它的性能,然后是超越。
通过应用所有过滤规则(去除不以标点符号结尾的行、提及 JavaScript 和 cookie 通知,以及去除不在长度阈值内的文档,包含“lorem ipsum”或花括号{}),他们能够匹配 C4 在 Hellaswag 上的表现。
然后,通过多次的消融研究,研究者确定了三个自定义过滤器在综合分数上显示出最显著的改进:
-
移除以标点符号结尾的行的比例≤0.12 的文档(移除了 10.14% 的 token)
-
移除在重复行中字符的比例≥0.1 的文档(移除了 12.47% 的 token)
-
移除短于 30 个字符的行的比例≥0.67 的文档(移除了 3.73% 的 token)
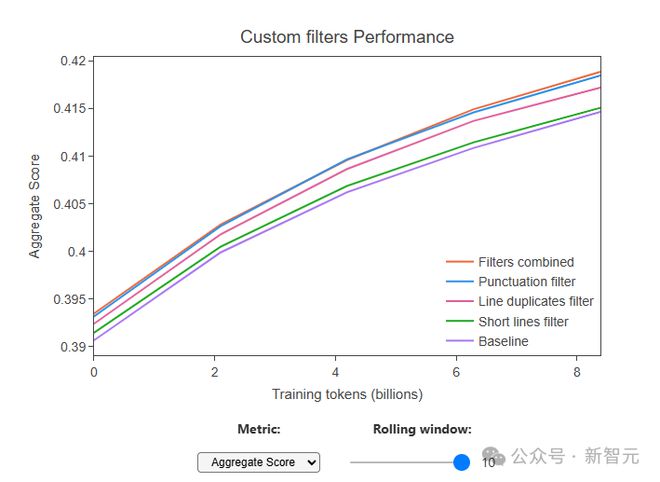
当这三个过滤器一起应用时,大约 22% 的标记被移除。
这些过滤器使他们能够进一步提高性能,并显著地超过了 C4 数据集的性能,同时提供了一个更大的数据集。
FineWeb 数据集的表现
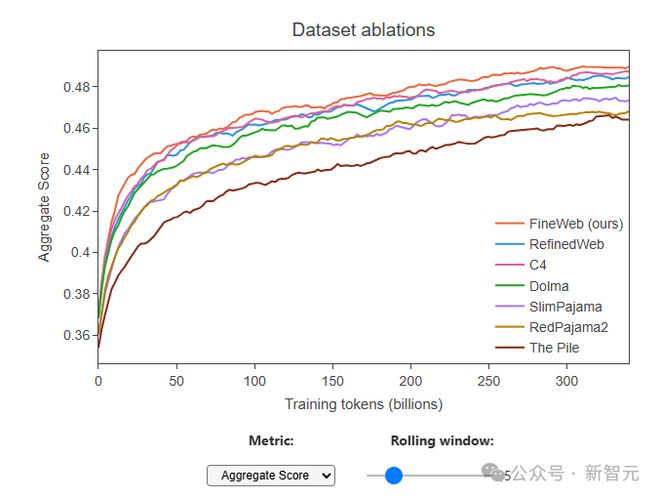
通过与其他通常被认为是最高质量的公开可访问的网络规模数据集进行了消融比较,包括 RefinedWeb(5000 亿个标记)、C4(1720 亿个标记)、Dolma v1.6(3 万亿个标记)等, FineWeb(15 万亿个标记)在允许训练数万亿个标记的同时,带来了目前最高的模型性能。
除此之外,该团队还发布了 FineWeb-Edu,FineWeb-Edu 的开发采用了一种新方法,即利用合成数据来开发用于识别教育内容的分类器。
针对教育领域,通过增加教育质量评分的注释和增加了单独的评分系统,研究者创建了一个有效的分类器,可以在大规模数据集上识别和过滤出具有教育价值的内容。
FineWeb-Edu 在教育基准测试如 MMLU、ARC 和 OpenBookQA 上取得了显著改进,超过了 FineWeb 和其他所有开放的网络数据集。
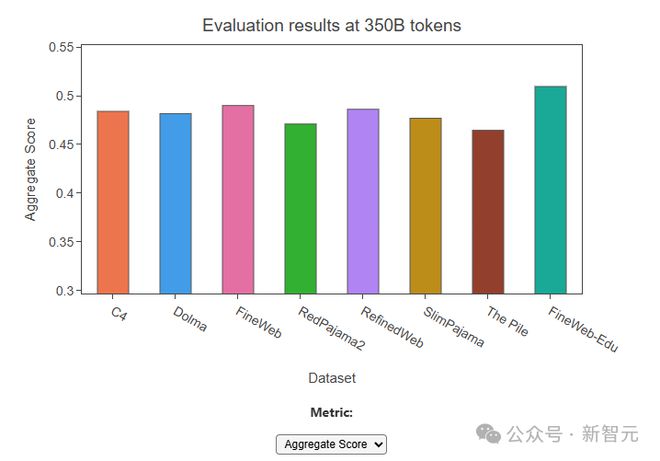
同时,FineWeb-Edu 的生成也证明了使用 LLM 注释训练的分类器在大规模数据过滤中的有效性。
在技术报告的最后,研究者表示,希望持续揭示高性能大型语言模型训练的黑箱,并让每个模型训练者都能创建最先进的 LLM。
他们也期待将 FineWeb 的经验和学习应用到其他的非英文语言,使多语言的高质量网络数据也能够更容易地被获取到。
参考资料:
https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1






