
新智元报道
编辑:桃子
等了半年,微软视觉基础模型 Florence-2 终于开源了。它能够根据提示,完成字幕、对象检测、分割等各种计算机视觉和语言的任务。网友们实测后,堪称「游戏规则改变者」。
一统视觉界的基础模型终于开源了!
最近,微软团队悄悄放出了 Florence-2 权重和代码,而且任何人皆可试玩。

去年 11 月,Florence-2 首次发布之初,凭借惊艳的能力在全网掀起轩然大波。
只需要一个提示,就可以指示模型完成诸如字幕、对象检测、分割等各种各样的 CV 和 CV 语言任务。
Figure 的首席执行官将其称之为,「计算机视觉领域的重大突破」。


在大多数基准中,Florence-2 甚至打败了多数数十亿美元的模型,就像 Phi-3 一样,表明了数据质量非常重要。

现在,模型的所有权重代码,已经放在开源平台 Hugging Face 上了,还有 MIT 许可证,随取随用。
体验后的网友称,它就是许多视觉任务的游戏规则改变者,不仅有极高精度,还有炸裂的速度。

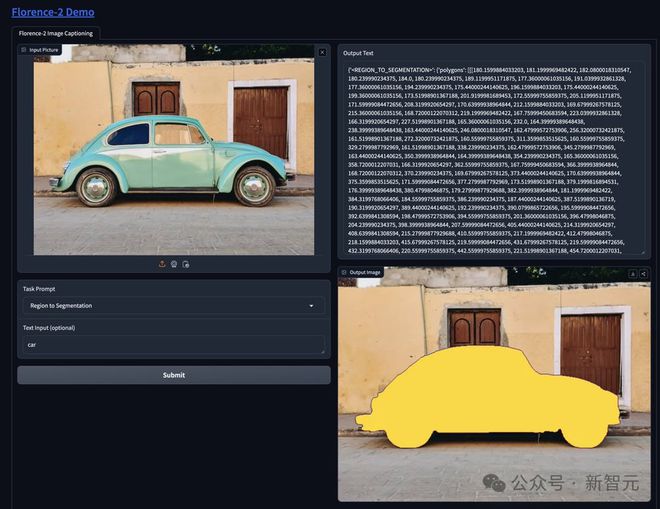
就看这铺屏的标注能力,简直强大到令人发指!

它竟然还可以识别出镜子。


更多精彩演示
Florence-2 更多案例如下,高密度的区域标注,能够将复杂区域的精细内容完成识别。

能够根据提示,找到对应的内容。

OCR 识别也是非常精准。

对电影海报的内容识别。

区域分割,可以精准将图像内容分割出来。

与 GPT-4V 等先进的多模态模型,在字幕任务上的比较。

Florence-2 还能看图写小作文。

统一视觉基础模型
微软团队的这篇论文已经被 CVPR 2024 接收为 Oral 论文。
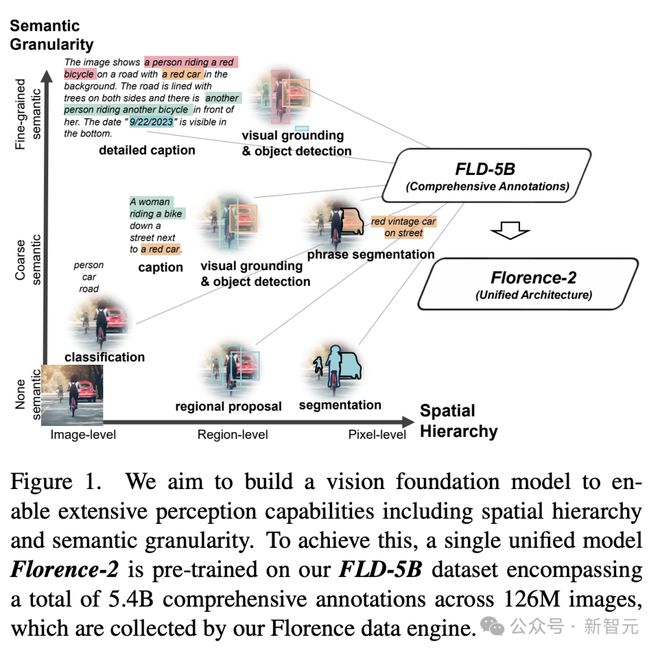
Florence-2 最初的设计目的是,创建一个视觉基础模型,实现广泛的感知能力。
将文本提示作为任务指令,并以文本形式生成理想的结果,无论是字幕、物体检测、还是分割等等。
论文地址:https://arxiv.org/pdf/2311.06242
为了实现这一目标,研究人员在 FLD-5B 数据集上(1.26 亿张图像上 54 亿个全面的视觉标注)对单个统一模型完成了训练。
接下来,一起看看 Florence-2 的设计架构和性能表现吧。
Florence-2 架构
为了开发多功能视觉基础模型,研究人员制定了一系列多任务学习目标,每个目标都是为了解决视觉理解的特定方面而定制的。
多任务学习方法包含三个不同的学习目标,每个目标都解决不同级别的粒度和语义理解:
- 图像级别的理解
- 区域/像素级别的识别
- 细粒度的视觉语义对齐任务
通过将这三个学习目标结合在多任务学习框架中,基础模型才可以学习处理不同级别的细节和语义理解。
这种战略调整使模型能够处理各种空间细节,区分理解中的细节层次,并超越表面层次的识别,最终学习视觉理解的通用表示。
如下图 2 所示,Florence-2 采用了序列到序列的学习范式,将以上的描述的所有任务整合到一个通用语言目标之下。

模型接受图像与任务提示,作为指令输入,并以文本形式生成期望的结果。
Florence-2 使用视觉编码器,将图像转换为视觉 token 嵌入,然后将其与文本嵌入凭借,并由基于 Transformer 的多模态编码器-解码器处理生成的响应。
数据引擎
为了训练 Florence-2 模型,研究人员需要一个全面、大规模、高质量的多任务数据集,覆盖了各种图像数据。
鉴于这种数据的稀缺性,他们由此创建了全新的多任务图像数据集——FLD-5B。
这一数据集中包含了 1.26 亿张图像、5 亿个文本标注、13 亿个文本-图像区域标注,以及 36 亿个文本短语-图像区域标注,跨横跨了不同的任务。

Florence-2 数据引擎一共包含三个重要环节:
1) 使用专业模型进行初始标注
2) 数据过滤,纠正错误并移除无关标注
3) 迭代式的数据优化过程
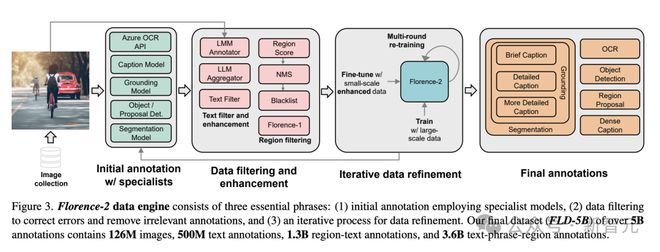
这是 FLD-5B 数据集中一张图像及其相应标注的示例图。
FLD-5B 中的每一张图像都由 Florence 数据引擎标注了文本、图像区域-文本对以及文本短语-图像区域三元组,涵盖了多个空间层次、从概括到详细的渐进粒度,以及多语义,让模型从不同角度实现了更全面的视觉理解能力。

这一个文本短语-图像区域标注的示例。

研究人员在表 1 中,提供了数据集与现有训练基础模型数据集之间的对比。
与之前的数据集相比,FLD-5B 的数据集优势在于,在总标注数量和每张图像标注数量非常大。
更重要的是,FLD-5B 数据集中标注涵盖了多个空间和语义细粒度,有利于训出模型实现更广泛和深入的视觉理解能力。
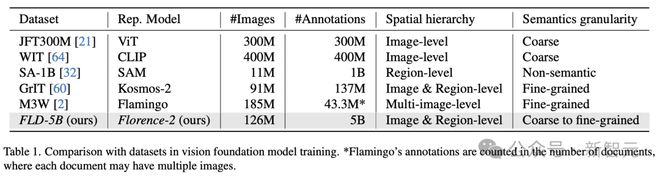
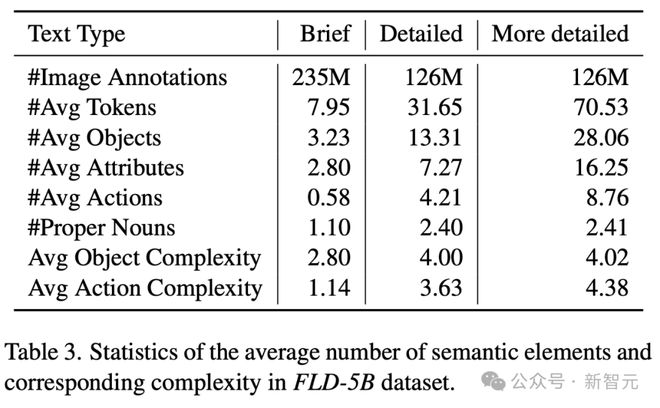
表 3 是 FLD-5B 数据集中,关于语义元素平均数量及相应复杂度的统计信息。
性能刷新 SOTA,赶超前沿模型
在如此庞大的数据集之上完成训练后,Florence-2 的性能表现又如何?
接下来,研究人员开展的实验主要分为三个部分:
- 评估模型在各种任务上的零样本表现,以展示通用模型处理多任务的内在能力,而无需在任务特定数据上进行额外的微调。
- 通过额外监督数据进一步微调,展示 Florence-2 的适应性和最佳性能
- 作为下游任务骨干网络时的卓越表现,证明了 Florence-2 预训练方法的有效性。
在零样本多任务评估中,对于图像级任务,Florence-2-L 在 COCO 字幕基准测试中获得了 135.6 CIDEr 分数,而且参数量仅为 Flamingo 模型(800 亿参数)的1% 左右。
对于区域级的 groundng 和指代表达理解任务,Florence-2-L 刷新了 SOTA。
在 Flickr30k Recall@1 上,它比 16 亿参数的 Kosmos-2 模型提高了 5.7,在 Refcoco、Refcoco+ 和 Refcocog 上分别比其提高了约4%、8% 和8% 的绝对值。

简单的设计带来了强大的性能。
Florence-2 采用了标准的多模态 Transformer 编码器-解码器架构,无需特殊设计,尤其在区域级和像素级任务上,性能飙升。
比如,在 RefCOCO 指代表达理解任务和指代表达分割任务上,Florence-2-L 相比 PolyFormer 模型,分别提高了 3.0 Accuracy@0.5 和 3.54 的 mIOU。
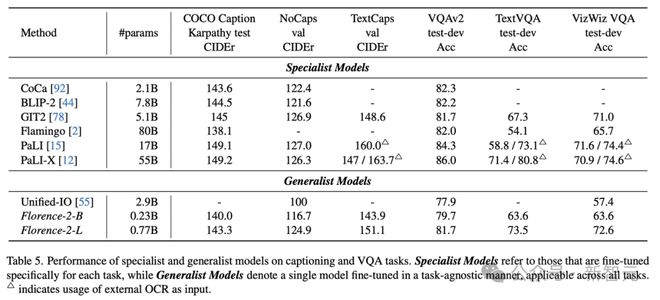
此外,Florence-2-L 在无需使用 LLM 的情况下,就能取得有竞争力的性能表现,展现了在处理多样化任务时兼具效率和紧凑高效模型的优势。
例如,在 COCO 字幕 Karpathy 测试集上,Florence-2-L 获得了 140.0 的 CIDEr 分数,超过了参数量明显更多的模型,如 80 亿参数的 Flamingo(CIDEr 分数为 138.1)。
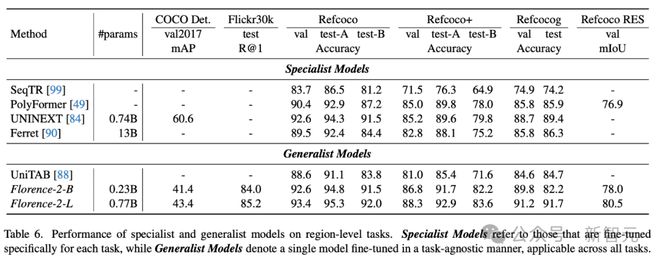
表 6 展示了,专家模型和通才模型在区域级任务上,Florence-2-L 和 Florence-2-B 的表现。
专家模型是指专门针对每个任务进行微调的模型,而通才模型表示以与任务无关的方式进行微调的单个模型,适用于所有任务。
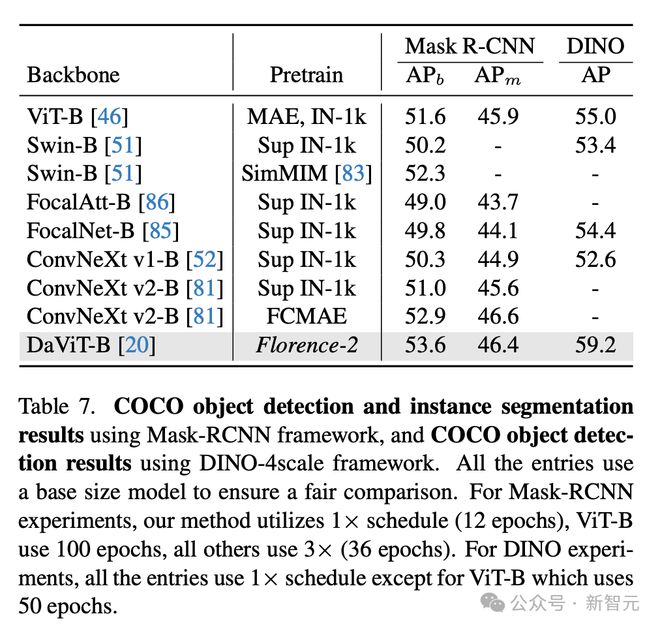
在 COCO 对象检测和分割,以及 ADE20K 语义分割任务的模型训练效率如下。

表 7 呈现了,使用 Mask-RCNN 框架的 COCO 目标检测和实例分割结果,以及使用 DINO-4scale 框架的 COCO 目标检测结果。
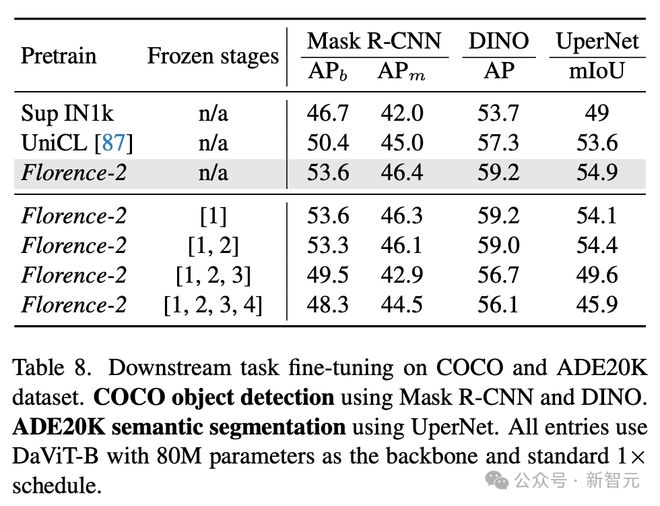
微调模型在 COCO 和 ADE20K 数据集上的下游任务表现。
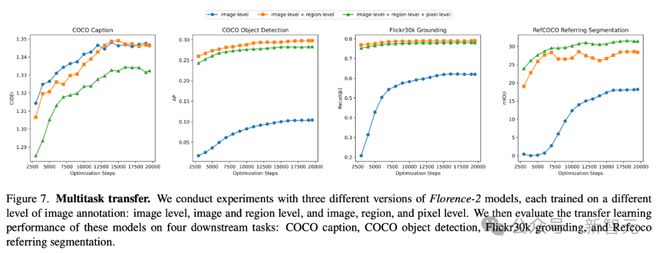
研究人员使用三个不同版本的 Florence-2 模型进行了实验,每个版本都在不同级别的图像标注数据上训练:图像级、图像和区域级、图像、区域和像素级。
然后,他们评估了这些模型在四个下游任务上的迁移学习性能:COCO 字幕、COCO 目标检测、Flickr30k grounding 和 Refcoco 指代分割。
具体表现,如下所示。
总的来说,Florence-2 是一种具备多种感知能力的基础视觉模型,通过构建大规模多标注数据集 FLD-5B,并进行多任务预训练,赋予了模型强大的零样本和任务迁移能力。
Florence-2 在诸多视觉任务上表现出色,推进了视觉基础模型的发展。
参考资料:
https://x.com/victormustar/status/1803449899121336639
https://x.com/adcock_brett/status/1733910508326023169
https://arxiv.org/pdf/2311.06242
https://huggingface.co/collections/microsoft/florence-6669f44df0d87d9c3bfb76de






