
新智元报道
编辑:编辑部
是时候把数据 Scale Down 了!Llama 3 揭示了这个可怕的事实:数据量从 2T 增加到 15T,就能大力出奇迹,所以要想要有 GPT-3 到 GPT-4 的提升,下一代模型至少还要 150T 的数据。好在,最近有团队从 CommonCrawl 里洗出了 240T 数据——现在数据已经不缺了,但你有卡吗?
是时候把数据 Scale Down 了!
如今,这个问题已经迫在眉睫。
清华博士秦禹嘉表示,Llama 3 就揭示了一个严峻且悲观的现实:在不改变模型架构的情况下,将数据量从 2 万亿(2T)增加到 15 万亿(15T),就能大力出奇迹。

这也就意味着,从长远来看,基座模型的发展机会,只能独属于大公司。
而考虑到 Scalng Law 的边际效应,如果我们希望在下一代模型身上看到从 GPT-3 到 GPT-4 级别的演进,就需要至少再清洗出至少 10 个数量级的数据(比如 150T)。
就在最近,好消息来了!
DCLM 团队从 CommonCrawl 里,清洗出了 240T 的数据。

论文地址:https://arxiv.org/abs/2406.11794
显然,这给 Scaling Law 的支持者们带来了福音——数据是不缺的,然而,你有卡吗?
后 Scaling Law 时代:不要 Scale Up,要 Scale Down
诚然,扩大数据规模非常重要,但如何缩减规模并提高每单位数据的质量,也同样关键。
模型的智能来自于数据压缩;反之,模型也会重新定义数据的组织方式。
秦禹嘉总结了以下多篇论文的内容后,给出了非常具有综合性的高度总结。

论文地址 : https://arxiv.org/abs/2405.20541

论文地址 :https://arxiv.org/abs/2406.14491

项目地址 : https://azure.microsoft.com/en-us/products/phi-3
DeepSeekMath::https://arxiv.org/abs/2402.03300
DeepSeek-Coder-V2:https://arxiv.org/abs/2406.11931
首先,最简单的方法,就是使用模型过滤掉噪声数据:
(1)PbP 使用小模型的困惑度来过滤数据,从而获得了可以显著提高大模型性能和收敛速度的数据;
(2)DeepSeek 使用 fastText 清理高质量数据,在数学和代码场景中取得了出色的成果;
(3)DCLM 进行了更详细的消融研究,发现与 BGE 嵌入、困惑度等相比,fastText 表现最佳。
这些研究无一例外有着相似的发现:「干净数据+小模型」,可以极大地接近「脏数据+大模型」的效果。
从这个角度来看,增加模型规模,本质上就是让我们看到在脏数据上训练的模型能力的上限。
也即是说,大模型在训练过程中通过使用更多冗余参数自动完成了去噪过程,但如果提前进行数据去噪,实际上需要的模型参数量并不大。
同样可以得出结论,通过数据微调把大模型打磨得很好,并不意味着训练大模型效果就会更好。
原因在于:「干净数据+大模型」和「脏数据+大模型」的效果,不会有太大差异。
总而言之,在前 Scaling Law 时代,我们强调的是 Scale Up,即在数据压缩后争取模型智能的上限;在后 Scaling Law 时代,需要比拼的则是 Scale Down,即谁能训出更具「性价比」的模型。
目前主流的数据缩减方法,是基于模型的数据去噪。
最近,也有一些研究开始使用训好的模型来改写预训练数据。这个过程就需要注意,避免模型在改写过程中生成虚假信息,同时还要有效地去除数据中的固有噪声。
Phi-2/Phi-3 的成功也验证了这一点:如果预训练级别的数据可以被机器处理,用小模型击败大模型是很容易的。
不过,目前的方法仍然专注于单个数据点的质量提升,但是在未来,更重要的研究方向就是如何对多个数据点进行语义级别的去重和合并。
这虽然困难,但对 Scale Down 意义重大。
下面就让我们看一下,DCLM 团队的这篇论文。
DataComp-LM(DCLM)基准
为了应对训练数据各种挑战,研究人员引入了 DataComp-LM(DCLM),是语言模型训练数据管理的「第一个基准」。

传送门:https://www.datacomp.ai/dclm/
在 DCLM 中,他们提出了全新的训练集和数据管理算法,然后通过使用固定的方法,训练模型以评估数据集。
通过测量由此产生的模型在下游任务上的表现,研究人员可以量化相应训练集的优势和劣势。
接下来,为了实现 DCLM,研究人员开发了一个全面的实验测试平台,包含了多个重要的组件。
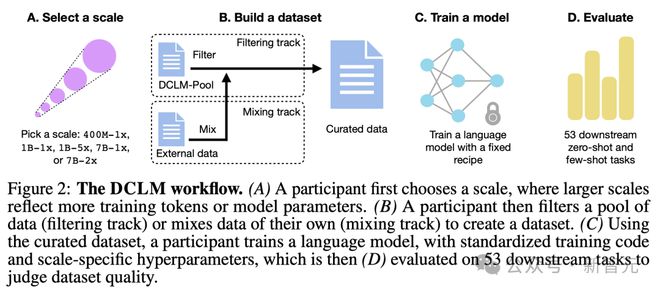
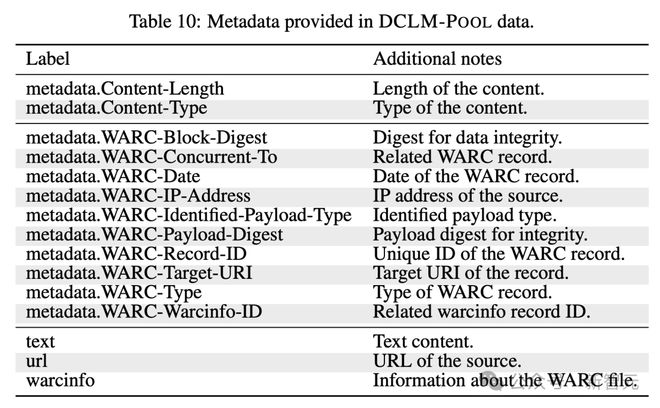
其中一个关键的组件,便是最大的语言模型训练语料库 DCLM-POOL。
这是从未经过滤的爬虫网站 Common Crawl 上,扒下来来足足有 240T 的数据集,涵盖了 2023 年之前所有的数据。
具体来说,DCLM-POOL 包含 2000 亿个文档(gzip 压缩后为 370TB),产生了 240 万亿个 GPT-NeoX token。
据介绍,获取如此庞大的数据,是通过 resiliparse 架构从 HTML 中重新提取文本,与 Common Crawl 原本预处理的方法并不相同。
此外,在训练 AI 语言模型时,有时候用来测试模型的数据会不小心混入训练数据中。这就像 LLM 在考试前偷看了试卷,这可能会导致测试结果不准确。
然而,这些样本对下游性能的影响,在很大程度上业界研究人员对此仍不清楚。
为了让人们更好地理解这一问题,研究人员并没有去清理数据,而是发布了「去数据污染」的工具。
这一工具,可以让参与者检查自己的测试集和训练集,是否有重叠的情况,并提交相关的报告。
对于那些表现最好的 AI 模型,研究人员会特别检查它们是否「作弊」。
同样,论文的研究人员也将这一工具,应用在了 DCLM-POOL,以评估数据污染是否影响模型。
不同参数 LLM 都可 PK
为了确保 DCLM 对拥有不同计算资源的研究人员能够访问,并推动对 Scaling Law 趋势的研究,研究人员创建了跨越三个数量级计算规模的不同竞赛级别(表1)。
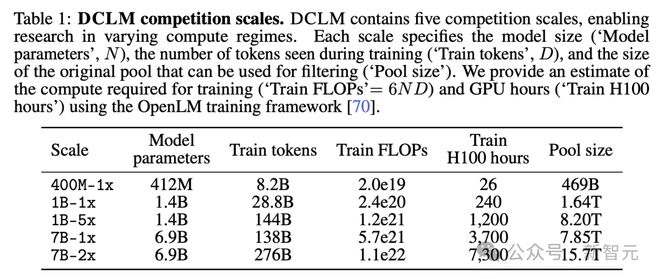
每个级别(即 400M-1x、1B-1x、1B-5x、7B-1x 和 7B-2x)指定了模型参数的数量和一个 Chinchilla 乘数。
比如,7B-1x 中,7B 表示模型有 70 亿参数,1x 是 Chinchilla 乘数。
每个级别训练 token 数量=20×参数数量×Chinchilla 乘数。其中,1x 乘数对应的计算资源分配接近 Hoffmann 等人研究中发现的最优水平。
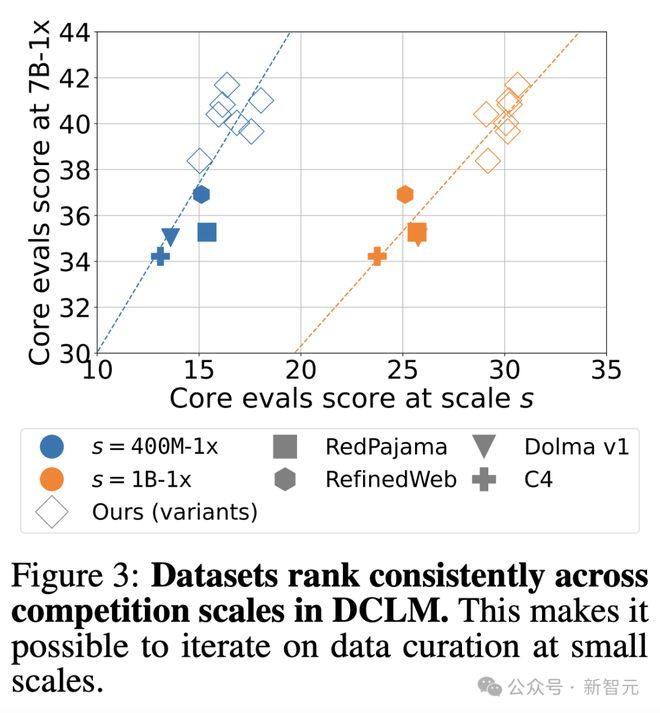
这样多种参数规模竞赛的设计,存在一个问题——当增加计算规模时,数据整理方法的排名可能会发生变化。
由此,研究人员比较了 10 种方法在不同参数规模(400M-1x、1B-1x 和 7B-1x)下的表现。
结果发现,小参数(400M-1x、1B-1x)和大参数(7B-1x)结果之间存在高度相关性。
两大赛道
在参与者选择了参数规模后,还需从两个基准测试赛道选择其一:过滤和混合。
1)在过滤赛道中,参与者提出算法从候选池中选择训练数据。有五个不同规模的数据池,对应(表1)不同的计算规模,这些池是 DCLM-POOL 的随机文档子集。研究人员根据参数规模限制初始池的大小,以模拟现实世界的约束。
2)在混合赛道中,允许参与者从多个来源自由组合数据,创造出最好的「配方」。比如,他们可以从 DCLM-POOL、自定义爬取的数据、Stack Overflow 和维基百科合成数据文档。
训练
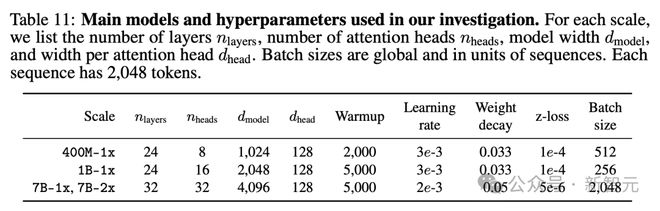
为了单独研究数据集干预的效果,研究人员还在每种参数规模上固定一个训练方案。
基于之前对模型架构和训练的消融实验,他们采用了一个仅有解码器的 Transformer 模型(例如,GPT-2,Llama),该模型在 OpenLM 中实现。
下表中详细列出了模型的超参数。
评估
研究的完整评估套件基于 LLM-Foundry,包含 53 个适合基础模型评估的下游任务(即无需微调)。
从问答到开放式生成格式,涵盖了编码、教科书知识和常识推理等各种领域。
为了评估数据整理算法,主要关注三个性能指标:
1. MMLU 5-shot 准确率
2. CORE 中心准确率
3. EXTENDED 中心准确率
用 DCLM 构建高质量数据集
接下来,一起看看研究人员是如何使用 DCLM 构建高质量训练数据集,整个流程如下图 4 所示。

首先,研究人员对表 2 中几个著名的数据集进行了评价,发现 RefinedWeb 在 7B-1x 规模的核心和扩展指标上表现最好。
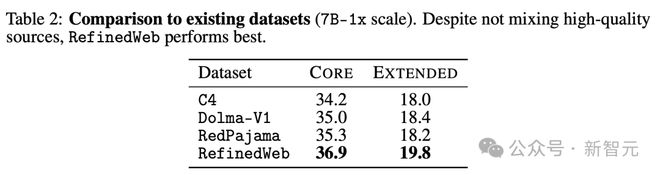
有趣的是,RefinedWeb 是完全从 Common Crawl 数据中过滤而来。
RefinedWeb 采用了以下过滤管线:Common Crawl 文本提取、启发式数据选择、重复数据内容删除。
文本提取
文本提取是一个常见的早期处理步骤,用于从原始 HTML 中提取内容。
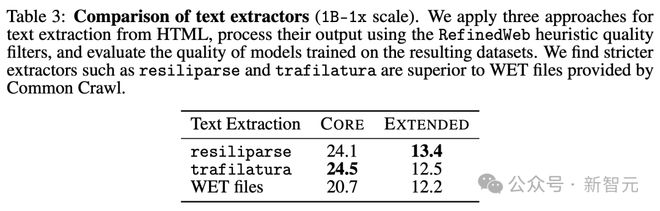
为了理解这一步骤的影响,研究人员比较了三种文本提取方法:resiliparse、trafilatura(RefinedWeb 使用)和 Common Crawl 提供的包含预先提取文本的 WET 文件。
然后,对每种文本提取结果应用 RefinedWeb 的启发式质量过滤器。
在表 3 中,研究人员发现 resiliparse 和 trafilatura 都比 WET 提取至少提高了 2.5 个 CORE 得分。
这很重要,因为大多数开源数据集,包括 C4、RedPajama 和 Dolma-V1,都使用 WET 提取,这可能部分解释了它们在表 2 中表现较差的原因。
虽然 resiliparse 和 trafilatura 在下游任务性能上相似,但 resiliparse 的运行速度快 8 倍,因此更适合大规模处理。
由此,如前文所述,研究人员最终选择采用了 resiliparse 策略。
数据去重
网络爬虫的数据集,通常包含许多复或接近重复的数据字符串。
而从训练集中删除这些重复项有着双重目的,既可以减轻 LLM 记忆来提高性能,又可以增加数据多样性。
为了去重,研究人员探索了算法 MinHash(作为后缀数组管线一部分),以及近似重复的 Bloom 过滤器(对精确文档和段落重复数据删除修改后的方案)。
结果发现,这两种方法在下游的表现中,性能相当。
在 7B-2x 参数规模下,差异在 0.2 个 CORE 百分点以内。不过,修改后的 Bloom 过滤器更容易扩展到 10TB 的数据集。
质量过滤
文献表明,使用可学习模型作为质量过滤器,可以带来下游的改进。
研究人员比较了多种基于模型的过滤方法——
1. 使用 PageRank 得分进行过滤,根据文档与其他文档链接的可能性来保留文档;
2. 语义去重(SemDedup),删除具有相似信息内容的文档;
3. 线性分类器,基于预训练的 BGE 文本嵌入;
4. AskLLM,通过提示大语言模型来查看文档是否有帮助;
5. 困惑度过滤,遵循 CCNet 保留低困惑度序列,
6. Top-k 平均对数:对文档中所有单词的 top-k 模型对数进行平均,以评定模型对k个合理选择范围内的正确单词有多大信心;
7. fastText 二元分类器,用于区分数据质量。
比较表 4 中的各个方法后研究人员发现,基于 fastText 的过滤优于所有其他方法。
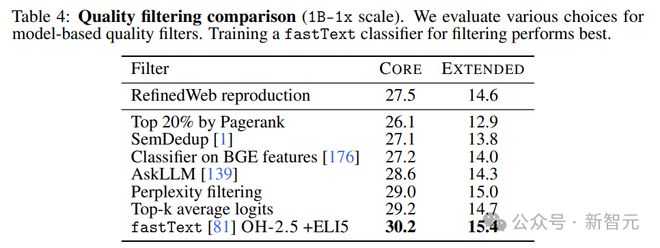
为了更好地理解 fastText 的局限性,研究人员训练了几个变体,探索参考数据、特征空间和过滤阈值的不同选择,如表 5 所示。
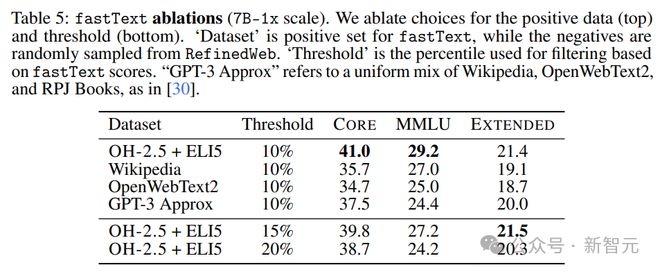
研究人员发现,在控制其他超参数时,与传统选择相比,fastText OH-2.5+ELI5 方法的 CORE 提升了 3.5 个百分点。
那么,使用 OH-2.5 数据进行过滤,是否会妨碍指令调整带来的额外增益呢?
研究人员发现,情况并非如此。
数据混合
业内的常见做法是,将 Common Crawl 和其他高质量数据源结合起来,如 Wikipedia、arXiv、Stack Exchange 和 peS2o。
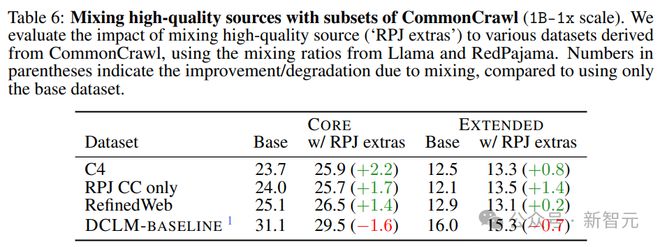
将高质量源添加到仅源自 Common Crawl 的训练集,有哪些潜在好处?
研究人员将 100% 过滤的 CC 数据训练的模型,与使用 Llama1 和 RedPajama 的混合比例训练的模型进行了比较。
表 6 中的结果表明,混合可提高性能较低的 CC 子集;然而,在高性能过滤的情况下,混合可能会适得其反。
数据清洗
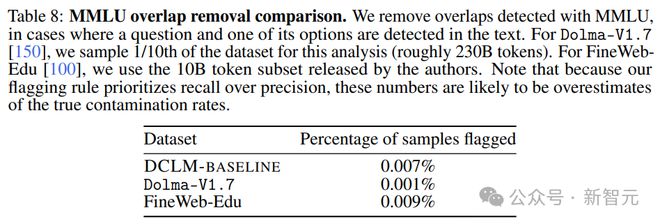
随后,研究人员进行了分析,以检查未经评估的预训练数据污染,是否会影响到结果。他们将重点放在 MMLU 上。
作为实验,研究人员还尝试检测并删除 MMLU 中存在于 DCLM-BASELINE 中的问题。
结果如表 7 所示——污染样品的去除,并不会导致模型的性能下降。
由此可见,MMLU 的性能提升并不是由数据集中 MMLU 的增加引起的。

在 Dolma-V1.7 和 FineWeb-Edu 上应用上述去除策略可知,DLCM-BASELINE 的污染统计数据,和其他高性能数据集大致相似。
扩展万亿 token
最后,研究人员测试了 DCLM 基准上,数据集在更大参数规模(万亿 token)下的表现。
为此,确保训练模型广泛适用,他们还构建了一个 4.1T token 的数据集,将 3.8T 的 DCLM-BASELINE 与 StarCoder、ProofPile2 数据相结合,包含了数学和编码任务。
得到数据集之后,研究人员在其之上训练了一个 7B 参数的模型,使用了 2.5T token,以及与最大竞赛参数规模相同的超参数。
其中,还采取了特殊的训练策略,包括两个冷却阶段(在 200B 和 270B token 时),以及「模型汤」(model soup)。
之后,研究人员采用了持续预训练方法,在在相同分布上再训练 100B 个 token,将上下文长度从 2048 增加到 8192。
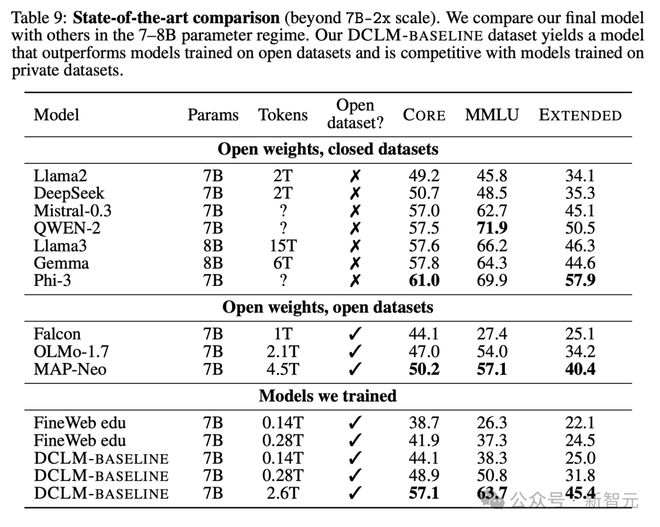
在表 9 中,展示了新模型优于所有在公开训练集上训练的 7B 模型,并接近于训练 token 更多的闭源模型,如 Llama-8B、Mistral-7B 和 Gemma-7B。
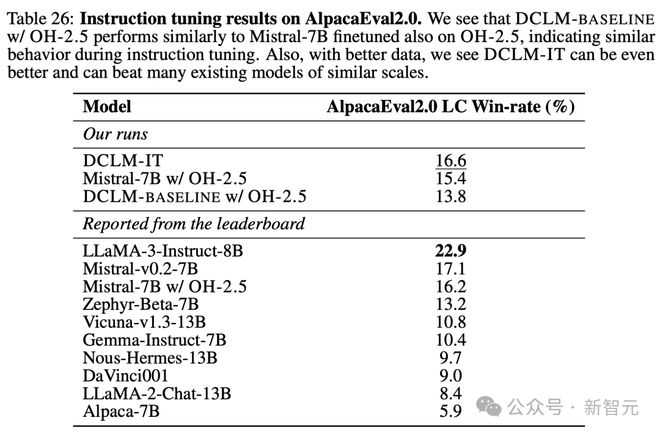
此外,表 26 展示了新模型在指令微调方面也取得了强劲的表现。
在公开可用的 IT 数据集上进行指令微调后,研究人员的模型保持了大部分基准性能,并在 AlpacaEval2.0 LC 中获得了 16.6 的胜率,超过了 Gemma-Instruct(10.4),同时接近 Mistral-v0.2-7B(17.1)和 Llama3-Instruct(22.9)的强劲表现。
局限性
由于计算资源的限制,研究人员只能单独消融设计维度,无法在更大参数规模上测试所有方法。
此外,还有许多未探索的 DCLM-BASELINE 变体。
例如,更详细地理解分片去重的影响很重要,而且在训练过滤模型方面,无论是架构还是训练数据,都还有很多其他方法。
研究中大多数实验也仅使用了一种分词器(GPT-NeoX),其他分词器可能在多语言任务或数学方面表现更好。
另一个局限是,论文无法充分探索不同随机种子导致的运行间的差异。
尽管在 DCLM-BASELINE 上训练的 7B 模型在常见的语言理解评估中具有竞争力,但它们目前在代码和数学方面的表现还不够理想。
研究人员对此表示,下一步,将会继续测试能否扩展到更大参数规模的模型。
参考资料:






