AI 浪潮之下,中国已经成为 AI 手机的最大潜在市场。
根据 Canalys 发布的关于《AI 手机对中国消费者的吸引力》报告,2024 年一季度,中国大陆市场依靠作为本土厂商的先发主场及市场高端化结构,AI 手机出货量达 1190 万部,占据全球 AI 手机出货的 25%。
值得注意的是,报告还提到,中国大陆是全球前三大智能手机市场中 AI 兴趣倾向最强的市场,中国大陆消费者在调查中展现出了对新技术更开放的态度。

其中,中国大陆有约 43% 的用户对于 AI 手机有着高度兴趣,德国、印度、墨西哥和美国的这一比例则分别为9%、38%、22% 以及 15%。当兴趣转化为购买需求,这意味着中国将成为 AI 手机的最大潜在市场。
Canalys 预测,具备 AI 功能的智能手机市场份额将呈指数级增长,到 2028 年将达到 54%,2023 年至 2028 年的复合年增长率为 63%,这得益于消费者对增强功能(如 AI 代理和设备内处理)的需求。
AI 大模型,涌进手机系统底层
第一波 AI 大模型的布局中,国产手机厂商走在了行业前列。
2023 年,华为率先将大模型接入手机,使得手机可以执行文本生成、知识查找、资料总结、智能编排、模糊/复杂意图理解等复杂任务。之后,其他厂商迅速跟进,比如小米训练出更为轻量级的语言大模型,参数规模为 13 亿和 60 亿两种。小米内部认为,轻量级模型也有其存在的市场空间,这是端侧大模型的特殊要求,也是一家智能设备厂商入局大模型的必经之路。
紧接着,vivo 则推出了蓝心大模型,同样主打轻量化,利于进行手机本地化的数据处理;荣耀则推出了端侧 70 亿参数平台级 AI 大模型,并宣布与百度智能云达成战略合作。
在前期的大模型应用中,手机厂商普遍采用的方案都是基于 AI 的分析和推理能力,对于单个手机功能进行优化。比如利用 AI 算力,提升手机影像质量;利用语言大模型,增加原有手机语音助手的功能,以便于进行文本处理。
而在近期的苹果和华为开发者大会上,将 AI 内嵌进手机系统底层,成为了某种共识。
以苹果为例,该公司的新 AI 系统将被称为 Apple Intelligence,并将出现在新版 iPhone、iPad 和 Mac 操作系统上。iOS 在嵌入 OpenAI 的 AI 大模型之后,Siri 将能够在更多应用程序中理解用户的内容并对其采取行动,还能够调用多个 APP 的功能去完成一个复杂命令。
与苹果的方案类似,华为此次也试图将 AI 大模型的能力植入鸿蒙系统底层,以此来同时调用多个 APP 的功能,让终端设备可以完成复杂度更高的人机交互方式。不同的是,鸿蒙所使用的 AI 大模型为华为自研的盘古大模型。
“得益于盘古大模型 5.0 的加持,小艺的能力也得到全新升级。”华为终端 BG CEO 何刚称,比如,小艺智能体与导航条融为一体,无论在任何应用界面,都可以随时召唤。只需将文字、图片、文档“投喂”小艺,即可便捷高效处理文字、识别图像、分析文档。
显然,在原生的鸿蒙和 iOS 系统内,嵌入 AI 大模型之后,智能手机的厂商将可以实现更多个性化的 AI 功能。这是陷入创新瓶颈之后,智能手机行业为数不多可以带来突破性创新的机会。
供应商竞争与政策壁垒
事实上,AI 手机的战场除了有终端厂商之间的竞争,供应链厂商的技术角逐也是一大重点。
目前,高通正努力确立自己在端侧 AI 领域的领导地位。比如,高通最新一代的处理器——骁龙 8 Gen 3 在设备上运行的 LLM(在优化后的 7B 模型上达到 20 个 tokens/秒)和 LVM(在优化后的 Stable Diffusion 模型上生成每张图像不到 1 秒),这要归功于其独有的量化工具和软件开发工具包(SDK),这些能力可以带来用户体验的差异化。
同时,高通的 AI Hub 赋予开发者在多个产品类别上使用单个模型,部署人工智能框架的能力,提升了对开发者的吸引力。
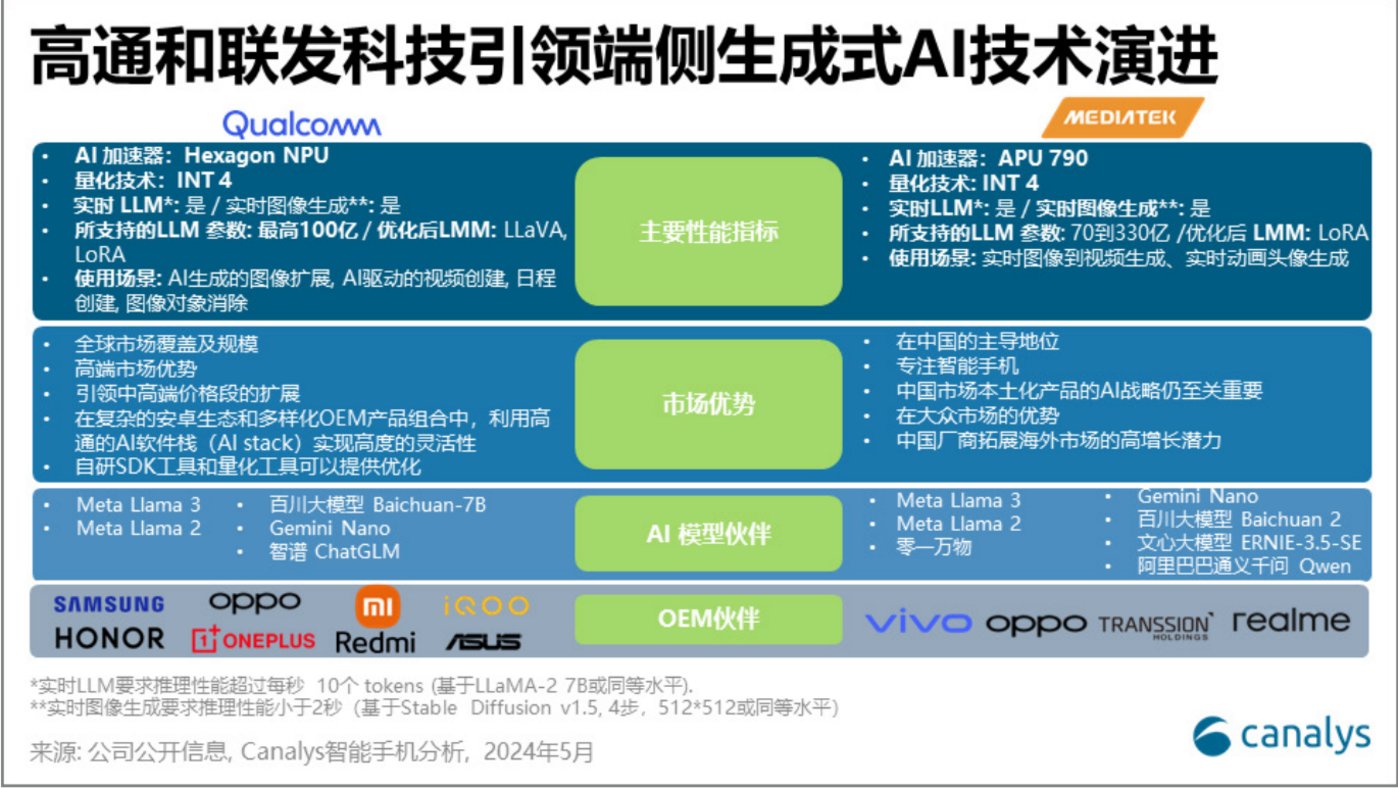
联发科则通过与百川智能、百度文言一心、零一万物和阿里巴巴通义千问等 AI 模型供应商的合作,巩固其在中国的应用程序开发版图。
与高通另外的不同之处在于,联发科的芯片主要被用于中端手机产品。目前,包括小米、荣耀等手机厂商,在中东、拉美和非洲地区的手机出货量都增长迅猛。随着手机厂商将 AI 能力进一步下放到中低端产品,联发科在 AI 手机领域的出货量也会水涨船高。
在全球竞争格局上,不同地区对于 AI 的监管政策,也会影响到手机厂商的战略选择。
比如,在欧洲,欧洲议会以压倒性票数通过了《人工智能法案》(下称"法案”)。根据法案要求,如果通用人工智能(GPAI)用于训练的累积计算量大于 10 的 25 次方每秒浮点运算次数(FLOPs),将被认为具有"系统性风险",并将面临模型评估、系统性风险评估和减轻等额外要求。
斯坦福大学 AI 研究实验室发布的一项研究显示,包括 Open AI 的 GPT-4, Meta 的 LlaMa 在内的 10 个主流大模型,均未满足《法案》草案的要求。
斯坦福研究团队在报告中表示:"主要基础模型提供商目前基本上没有遵守这些草案要求。他们很少披露有关其模型的数据、计算和部署以及模型本身的关键特征的足够信息。尤其是,他们不遵守草案要求来描述受版权保护的训练数据的使用、训练中使用的硬件和产生的排放,以及他们如何评估和测试模型。"
在中国,根据《数据安全法》(DSL)和《网络安全法》等法律规定,AI 技术产生的数据必须在国内存储和处理。目前,ChatGPT 的训练和开发涉及大量数据的运用和获取,同时 OpenAI 的大模型也未在中国相关监管机构完成备案。
这意味着,苹果的 Apple Intelligence 想要进入中国市场,则需要另寻合作伙伴。在这样的情况之下,一个问题也随之而来——中国的消费者是否还会选择苹果?(本文首发于钛媒体 APP,作者饶翔宇编辑钟毅)






