本文作者:李丹
来源:硬 AI
以 ChatGPT 掀起这轮 AI 应用热潮的 OpenAI 正在用行动证明,在基于人类反馈的强化学习(RLHF)领域,它也是先行者。
美东时间 6 月 27 日周四,OpenAI 公布,其研究人员训练了一个基于 GPT-4 的模型,它被称为 CriticGPT,用于捕捉 ChatGPT 代码输出中的错误。简单来说就是,CriticGPT 让人能用 GPT-4 查找 GPT-4 的错误。它可以写出使用者对 ChatGPT 响应结果的批评评论,从而帮助人类训练者在 RLHF 期间发现错误。
OpenAI 发现,如果通过 CriticGPT 获得帮助审查 ChatGPT 编写的代码,人类训练师的审查效果比没有获得帮助的人强 60%。OpenAI 称,正着手将类似 CriticGPT 的模型集成到旗下 RLHF 标记管道中,为自己的训练师提供明确的 AI 帮助。
OpenAI 称,因为没有更好的工具,所以人们目前难以评估高级的 AI 系统的表现。而 CriticGPT 意味着,OpenAI 向能够评估高级 AI 系统输出的目标迈进了一步。,
OpenAI 举了一个例子,如下图所示,对 ChatGPT 提出一个用 Python 编写指定函数的任务,对于 ChatGPT 根据要求提供的代码,CriticGPT 点评了其中一条指令,提议换成效果更好的。

OpenAI 称,CriticGPT 的建议并不是全都正确无误,但 OpenAI 的人员发现,相比没有这种 AI 的帮助,有了它,训练师可以发现更多模型编写答案的问题。
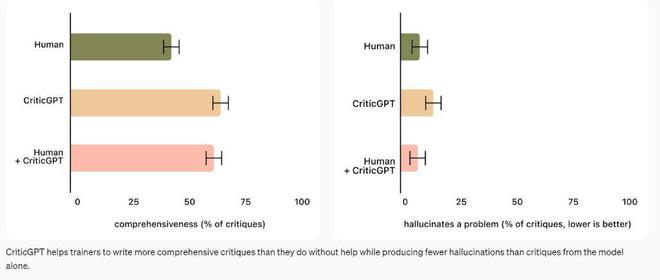
此外,当人们使用 CriticGPT 时,这种 AI 模型会增强他们的技能,从而得出的批评结论比单单人类训练师做的更全面,并且比 AI 模型单独工作时产生的幻觉错误更少。
在 OpenAI 的实验中,在 60% 以上的时间里,随机选择的训练师都更喜欢来自人类与 CriticGPT 合作的批评结论,而不是来自没有 CriticGPT 协助的人类训练师批评。
OpenAI 同时提到了目前开发 CriticGPT 的四点局限。其中之一是,OpenAI 用 ChatGPT 的简短答案训练 CriticGPT,因此未来需要发掘能帮助训练师理解冗长且复杂任务的方法。
第二点是,模型仍然会产生幻觉,有时训练师在看到这些幻觉后会犯下标记错误。第三点是,有时现实世界中的错误可能分散在答案的许多部分之中,OpenAI 目前的工作重点是让模型指出一处的错误,未来还需要解决分散在不同位置的错误。
第四点,OpenAI 指出,CriticGPT 只能提供有限的帮助:如果 ChatGPT 面对的任务或响应极其复杂,即使是有模型帮助的专家也可能无法正确评估。
最后,OpenAI 表示,为了协调日益复杂的 AI 系统,人们需要更好的工具。在对 CriticGPT 的研究中,OpenAI 发现,将 RLHF 应用于 GPT-4 有望帮助人类为 GPT-4 生成更好的 RLHF 数据。OpenAI 计划,进一步扩大这项工作,并将其付诸实践。
OpenAI 在原名推特的社交媒体X上公布了新模型 CriticGPT 后,一条点赞超 1 万的网友评论称,自我改进已经开始了。
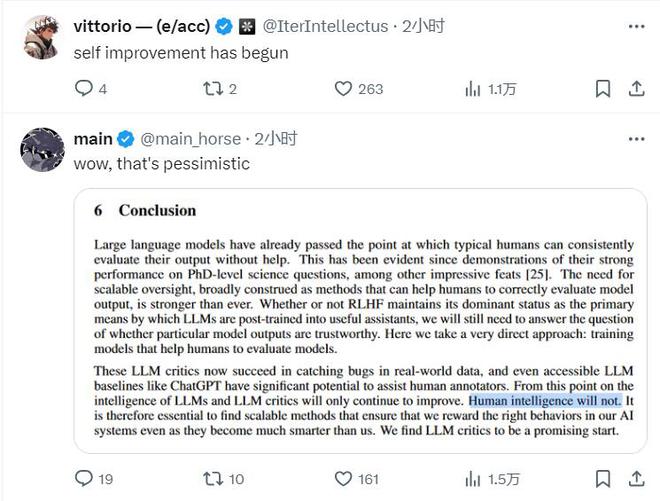
另一条点赞上万的热截取了 OpenAI 的相关研究文章结论,其中提到,在智能方面,大语言模型(LLM)和 LLM 的批评都只会继续改进,而人类的智能不会,这条评论感叹,真是悲观。
还有网友引用了漫威超级英雄电影《复仇者联盟》中灭霸的一句台词,点评 OpenAI 所说的用 GPT-4 找 GPT-4 的错误:“我用宝石摧毁了宝石。”