
新智元报道
编辑:alan 好困
近日,首个多模态 LLM 视频分析综合评估基准 Video-MME 诞生!在这场全新的考试中,Gemini 1.5 Pro 一路遥遥领先,谷歌首席科学家 Jeff Dean 更是愉快地连续转了 3 次推。
大模型性能哪家强?GPT-4 一家常霸榜。
基准测试全擅长,竞技场上见真章。

不过近日,谷歌的 Gemini 终于扬眉吐气了一把,在全新的、更复杂的多模态考试中大获全胜,全面超越了 GPT-4o。
Jeff Dean 表示:已阅,很赞。
这就是来自中科大,厦大,港大,北大,港中文和华师大的研究者联合奉献的,世界上首个多模态 LLM 视频分析综合评估基准——Video-MME。

论文地址:https://arxiv.org/pdf/2405.21075
项目地址:https://video-mme.github.io/
在前往 AGI 的道路上,多模态大语言模型(MLLM)显然成为当前的焦点。
不久前出世的 GPT-4o,就在多模态的表现上技惊四座;同时,偏爱谷歌「双子座」的网友也不在少数。


不过之前的相关基准测试,主要关注 LLM 在静态图像理解方面的能力。
而对于现实世界来说,处理连续视觉数据,也就是视频的能力,是至关重要的。

Video-MME 是有史以来第一个为视频分析精心设计的,综合多模态基准测试,帮助我们全面评估 MLLM 捕捉现实世界动态性质的能力。
Video-MME 涵盖了广泛的视觉域、时长和数据模式,包括 900 个视频,总时长 256 小时,还人工注释了 2700 个高质量的问答对(多项选择题,每个视频 3 个)。
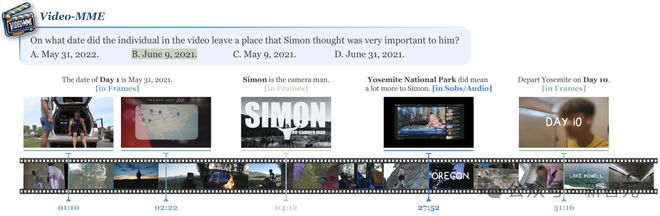
下图是其中一个例子:
准确回答该问题需要同时从视频帧、字幕 or 语音中同时获取信息,并且信息直接的跨度达 30 分钟
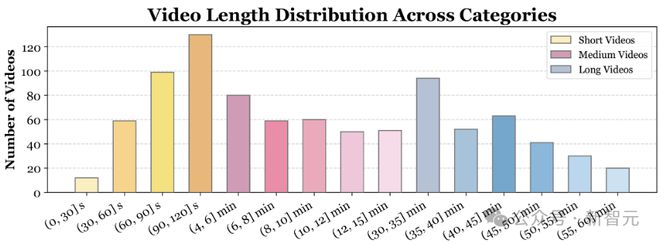
在时间维度上,Video-MME 中收集了各种不同时长的视频。
包括短视频(< 2 分钟)、中视频(4 分钟~15 分钟)和长视频(30 分钟~60 分钟),总体时长从 11 秒到 1 小时不等。
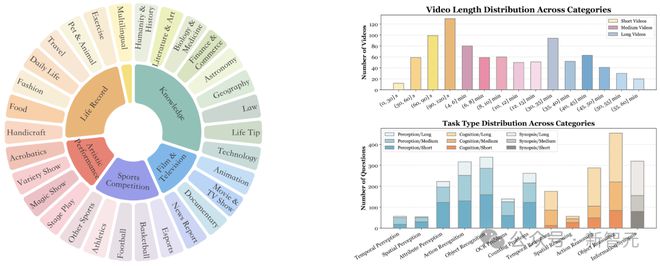
从视频类型多样性来看,Video-MME 跨越了 6 个主要视觉领域:知识、影视、体育比赛、生活记录和多语言,包含有 30 个子领域,以确保广泛的场景泛化性。
在数据模式的广度上,Video-MME 整合了视频帧以外的多模态输入,包括字幕和音频,以评估 MLLM 的全方位能力。
此外,Video-MME 中所有数据都是由人类新收集和标注,而不是来自任何现有的视频数据集,以确保数据的多样性和质量。
研究人员使用 Video-MME,对各种最先进的 MLLM 进行了基准测试,包括 GPT-4V、GPT4o 和 Gemini 1.5 Pro,以及开源图像模型 InternVL-Chat-V1.5 和视频模型 LLaVA-NeXT-Video 等。

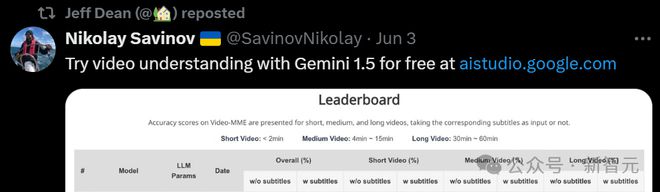
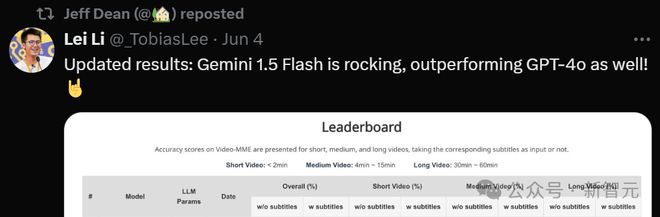
实验表明,Gemini 1.5 Pro 是目前性能最高的商用 MLLM,平均准确率为 75%,GPT 系列的最好成绩是 GPT-4o 的 71.9%。
相比之心,开源 MLLM 仍有巨大差距,表现最好的 VILA-1.5 以及 LLaVA-NeXT-Video 的总体准确率分别只有 59 和 52%,开源社区还有相当大的提升空间。

此外,通过将输入扩展到多帧图像,Video-MME 也可用来评估基于图像的 MLLM,例如 Qwen-VL-Max 和 InternVL-Chat-V1.5。
两种模型的准确度均达到 51% 左右,接近视频专用模型 LLaVA-NeXT-Video,这表明图像理解是视频理解的基础,所以 Video-MME 在 MLLM 评估领域具有广泛的适用性。
下面,换个视角,看看这些 MLLM 在不同任务类型下的表现:
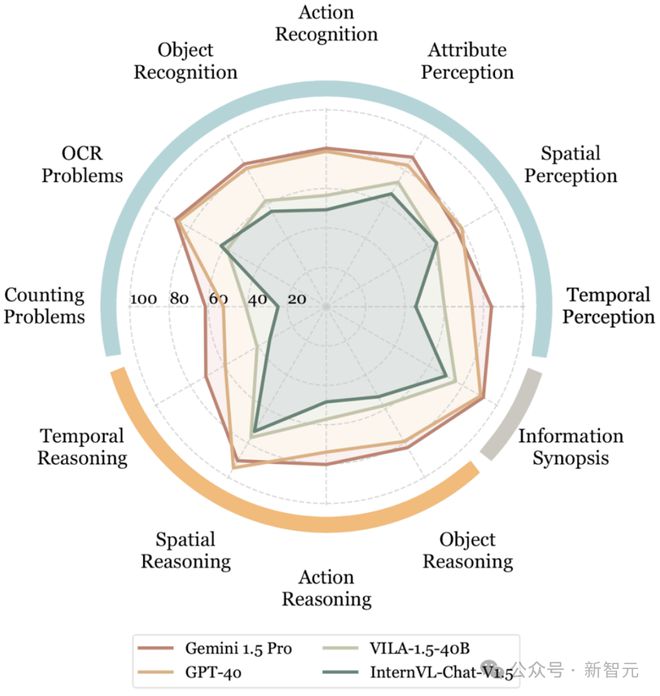
——Gemini 1.5 Pro 最终还是压制住了 GPT-4o!
我们再把 Gemini 1.5 Pro 单独拉出来开个小灶,详细给出不同视频时长和不同视频类型下的评估结果:
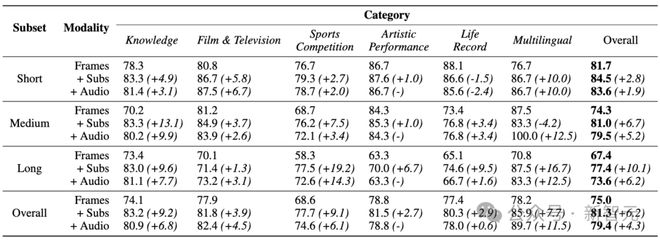
通过对上表的进一步观察,我们还可以发现,整合字幕和音频可以显著增强 LLM 的视频理解能力。
Gemini 1.5 Pro 在加入字幕和音频之后,准确度分别提高了 6.2% 和 4.3%,长视频则更为明显。
对任务类型的细粒度分析表明,字幕和音频对于需要大量领域知识的视频特别有益。
当然了,随着视频长度的增加,MLLM 性能普遍下降,所以处理长视频仍然是件困难的事情。
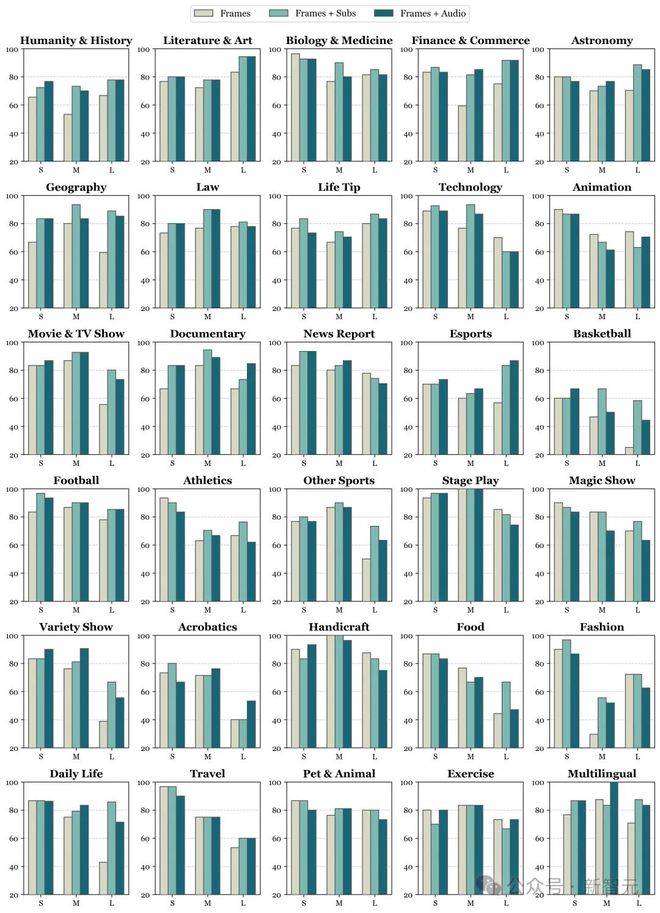
下面给出 Gemini 1.5 Pro 在不同视频子类型上的评估结果,包括天文学、技术、纪录片、新闻报道、电子竞技、魔术表演和时尚等 30 个子类别。
Video-MME
数据集构建
Video-MME 的数据集构建过程包括视频采集、问答对标注、质量审核三个步骤。
视频采集
为了全面覆盖不同的视频类型,研究人员创建了一个域层次结构,用于从网络上收集原始视频。
首先定义 6 个关键领域:知识、电影和电视、体育比赛、生活记录和多语言。
每个领域进一步划分为详细的标签,例如体育比赛包含足球和篮球,从而产生总共 30 个细粒度的视频类。
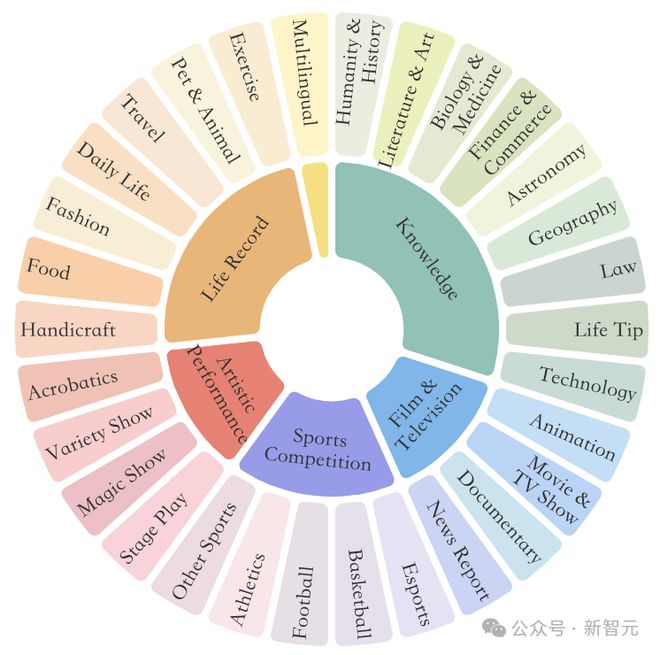
对于每个类型,收集不同持续时间的视频:短视频(少于 2 分钟)、中视频(4-15 分钟)和长视频(30-60 分钟)。
此外,还会获取相应的元信息,例如字幕和音频,用于进一步研究。最终的数据集由 900 个视频组成,这些视频跨越各个领域,持续时间长度相对平衡。
问答标注
在收集原始视频数据后,研究者对以问答对的形式对其进行注释,以评估 MLLM 在解释视频内容方面的熟练程度。
这里采用多项选择题的 QA 格式,参与标注的作者都精通英语,在视觉语言学习方面具有丰富的研究经验。
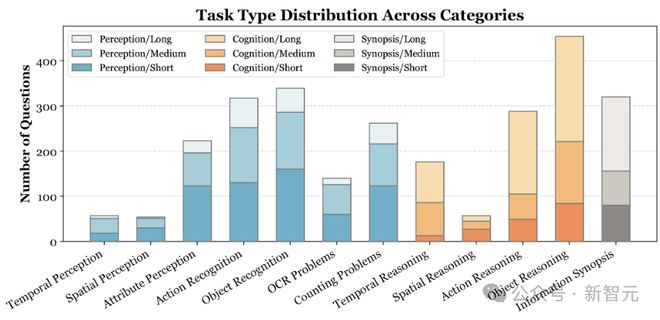
标注者通过反复观看视频来提出 3 个相关的问题,每个问题有 4 个潜在选项。这 2700 个 QA 对包含 12 种任务类型,比如感知、推理和信息概要。
质量审核
为了保证数据集的质量,作者还进行了严格的人工审查流程。
首先,指派不同的标注者来检查每个 QA 对,确保语言表达正确且明确,以及问题可回答(候选选项和正确选项都是合理的)。
此外,为了确保问题足够具有挑战性,要求多模态模型看了视频才能回答,研究人员向 Gemini 1.5 Pro 提供了纯文本问题,并过滤掉可以仅根据文本问题回答的 QA 对。
最后,Gemini 1.5 Pro 在仅使用文本提问的情况下,准确率低于 15%。
数据集统计
视频和元信息
Video-MME 总共包含 900 个视频、713 个字幕和 869 个音频文件。
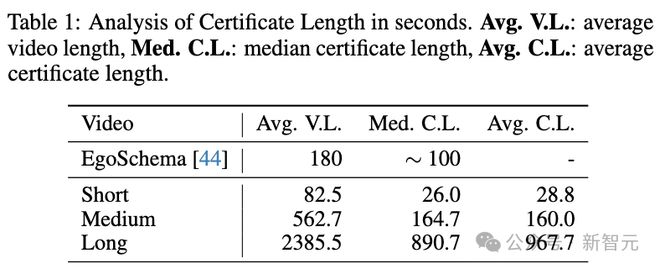
从任务类型的分布来看,较短的视频主要涉及与感知相关的任务,例如动作和物体识别。相比之下,较长的视频主要以与时间推理相关的任务为特色。从下表中可以看到,Video-MME 的有效时长(Certificate Length 准确回答问题所需的时间跨度)非常长,表明了其挑战性。
问答数据
关于问题和答案的语言多样性,下表列出了数据集中文本字段的平均字数。
问题、选项和答案的字数在不同视频长度上显示出显著的一致性,这表明 Video-MME 中的 QA 对风格一致。
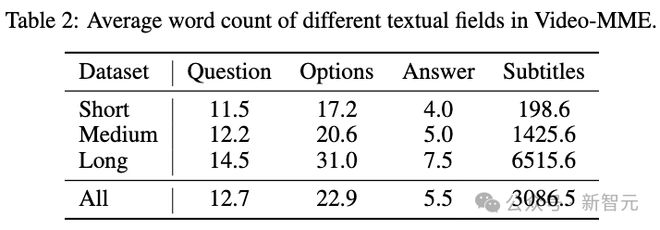
另一方面,字幕的字数随着视频长度的增加而显着增加,短视频的平均字数为 198.6,而长视频子集的字数高达 6.5K。这一趋势表明,较长的视频包含的信息更多。
此外,问题对应的正确答案选项(A/B/C/D)的分布接近均匀(25.2%/27.2%/25.2%/22.3%),确保了无偏的评估。
参考资料:






