据彭博社最新报道,软银集团旗下的愿景基金 2 号,即将投资美国人工智能初创公司 Perplexity AI。
知情人士透露,软银的这次投资金额为 1000 万至 2000 万美元,而 Perplexity 本轮的融资总额也超过了 2.5 亿美元。
这轮融资预计会让 Perplexity 的估值提高三倍,可能达到 25 亿至 30 亿美元,将使其成为业内估值最高的公司之一。

Perplexity 的目标是利用人工智能与 Google 搜索展开竞争。
作为一家初创独角兽公司,他们的核心服务是提供一个「答案引擎」,这与传统的搜索引擎有着本质的区别。
用户不需要通过多个结果来寻找自己的问题的主要来源,而是直接获得 Perplexity 为你找到的答案。
Aravind Srinivas 曾经是 OpenAI 的一名研究科学家。在离开 OpenAI 后,他于 2022 年 8 月创立了 Perplexity。
Perplexity 想要为用户提供快速、准确的答案,而无需用户在海量信息中自行筛选。
Aravind Srinivas 在接受 The Verge 采访时,也同样说到:
我们关心的是真实性和准确性。

作为「世界上首个对话式答案引擎」, Perplexity 回答界面十分干净。在结果页面,上方是信息来源,中间是答案,下面是延伸问题。
其独特之处在于将 ChatGPT 式的问答和传统搜索引擎的链接列表相结合,开创出了一种全新的搜索体验。

早前在接受 Wired 采访时,黄仁勋说自己「一直在用 Perplexity」。
当然,他也觉得 ChatGPT 挺好。在采访时,黄仁勋尤其对计算机辅助药物发现领域感兴趣,他「差不多每天都用这两个」来做调研:
或许说,你想了解计算机辅助药物发现领域的进展。
那你得先围绕这个话题来建一个框架,然后从那个框架问些更具体的问题。
尽管 Perplexity 的商业模式在理论上具有吸引力,但其作为中间者的角色,可能会引发一些内容创作者的担忧。
与 Arc Search 和 Google Gemini 一样,在搜索问题后,Perplexity 也是直接提供答案结果。
如果这样做,就必定会影响原始内容网站的流量和广告收入。

像 Google 和百度这样的传统搜索引擎,其大部分资料都是爬虫自动抓取的,以便于用户通过关键词进行搜索。
爬虫可以迅速检索并整理网站的信息,但它不会无脑抓取所有内容。网站一般在建立时,会设定一个 Robots 协议文件(也即 robots.txt)。
通过这个文件,网站就可以告诉搜索引擎的爬虫:哪些网页可以抓取,哪些不可以。这是一种非强制性的协议,主要依赖于爬虫开发者的遵守。
大多数搜索引擎和爬虫开发者都会尊重 Robots 协议,不会抓取那些网站明确禁止抓取的内容。这样做是为了尊重网站的隐私和版权,同时也是为了避免法律问题。
如果不遵守这个协议,那么爬虫就会强行访问网站的内容。这样做带来的另一个结果,就是一些网站的付费墙可能会失效。

在前不久,有人在使用 Perplexity 时,尝试让其总结关于埃里克·施密特(Eric Schmidt)秘密无人机项目。
然而,在 Perplexity 给出的结果中,可以看到里面有几个片段是从 Forbes 的独家报道摘取而来的,而且还给出了 Forbes 创作的一张原创插图。

后来 Forbes 也主动尝试用 Perplexity 生成内容,在经过对多篇文章主题检索后,他们发现自家文本内容经常会出现在 Perplexity 给出的答案中。
其中,有很多文章是带有付费墙的独家报道。Perplexity 绕过了 Forbes 的付费墙,未经授权使用了许多原创图片和文本。
不光如此,Perplexity 给出的答案正文中也没有出现资料来源。唯一的署名是一些可以链接到这些媒体的图标,但是它们都非常小且容易被忽略

除了 Forbes,另一家著名媒体 Wired 也在控诉 Perplexity。
Wired 在早前写了一篇关于 Perplexity 的文章,同样报道了 Perplexity 在试图使用爬虫那些被阻止访问的网站内容。
但后来,奇葩的事情出现了:Perplexity「盗用」了 Wired 的这篇文章 —— 尽管这篇文章是关于它自身的,而且 Wired 在其网站的相关文件中也明确阻止了 Perplexity 访问。

Wired 的开发人员 Robb Knight 对后台数据进行了研究。
在大量分析后,Wired 确定了一个有很大概率与 Perplexity 相关的特定 IP 地址,而且这个地址并不在 Perplexity 的公开 IP 范围内。

为了平息内容创作网站的情绪,Perplexity 的首席商务官 Dmitry Shevelenko 在接受 Semafor 采访时表示,Perplexity 正在与出版商开发收入共享计划。
Perplexity 尚未公布这些合作伙伴相关的细节,但 Dmitry Shevelenko 称会尽快公布其计划。

Aravind Srinivas 也在接受 Fast Company 的采访时回应了这一问题:
事实上,Perplexity 并没有忽视 robots.txt,它只是使用了忽视它的第三方抓取器。
不过,Aravind Srinivas 拒绝透露第三方抓取器的名称,也没有承诺会要求该抓取器停止违反 robots.txt。

如果尝试向 Perplexity 询问:「作为一个 AI 搜索引擎,你如何看待未经授权就引用他人文章?」
它会给出如下回答:
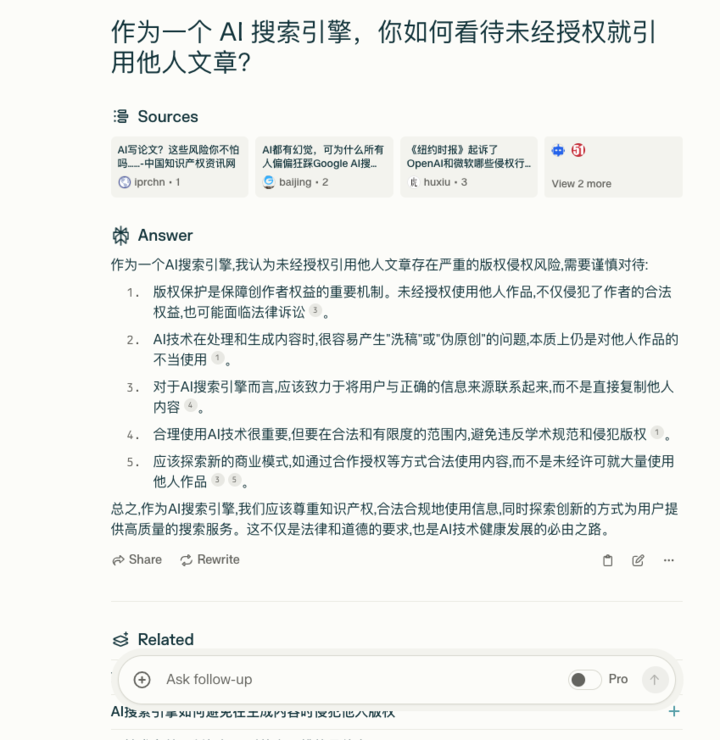
看来 Perplexity 自己也知道,这样做在一定程度上是有风险且不合法的。
就拿新闻业来说,如果你要写一篇新文章,你会怎么做?
你会说「据《纽约时报》报道」,也就是引用别人的话。这也正是我们在做的事情。
Perplexity 首席执行官 Dmitry Shevelenko 如此说到。
无论如何,还是希望 Perplexity 可以在合规的前提下,能继续创造出更有想法的 AI 工具。






