新智元报道
编辑:乔杨
最近,Hacker News 热榜上出现了一篇「声讨」LangChain 的技术文章,得到了评论区网友的一致呼应。去年还火遍 LLM 圈的 LangChain,为什么口碑逆转了?
2023 年是属于 LLM 初创公司的一年,也是属于 LangChain 的一年。
这个发布于 2022 年 10 月的开源框架可以支持开发者构建由 LLM 驱动的应用程序,目前依旧是社区中一种不可忽视的开发范式。

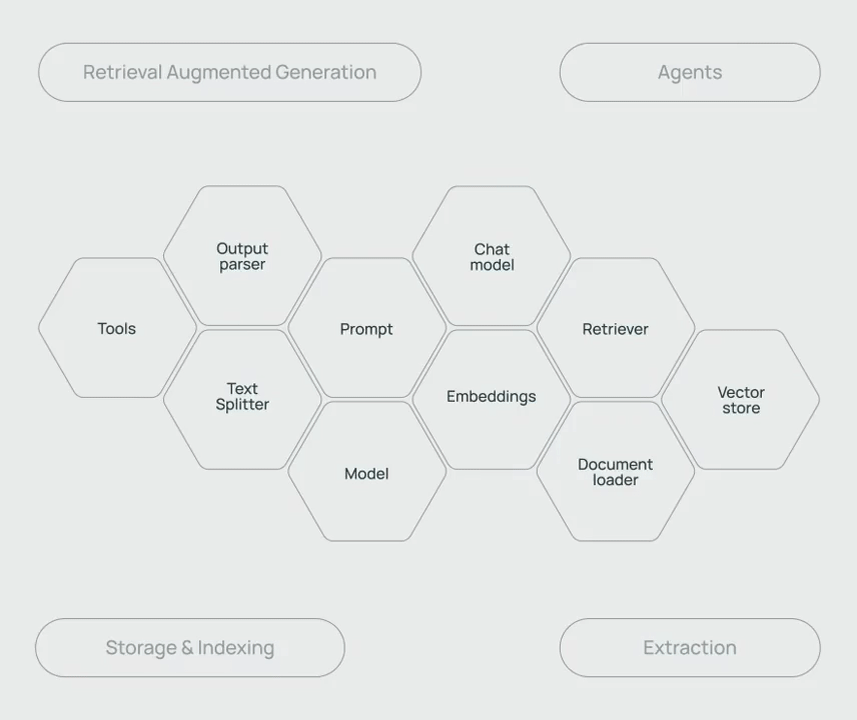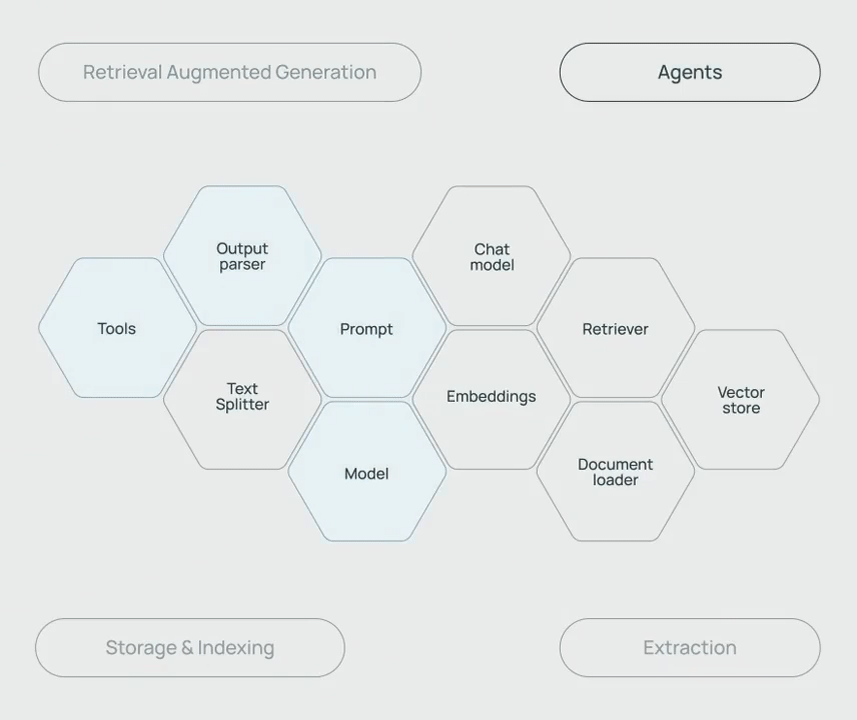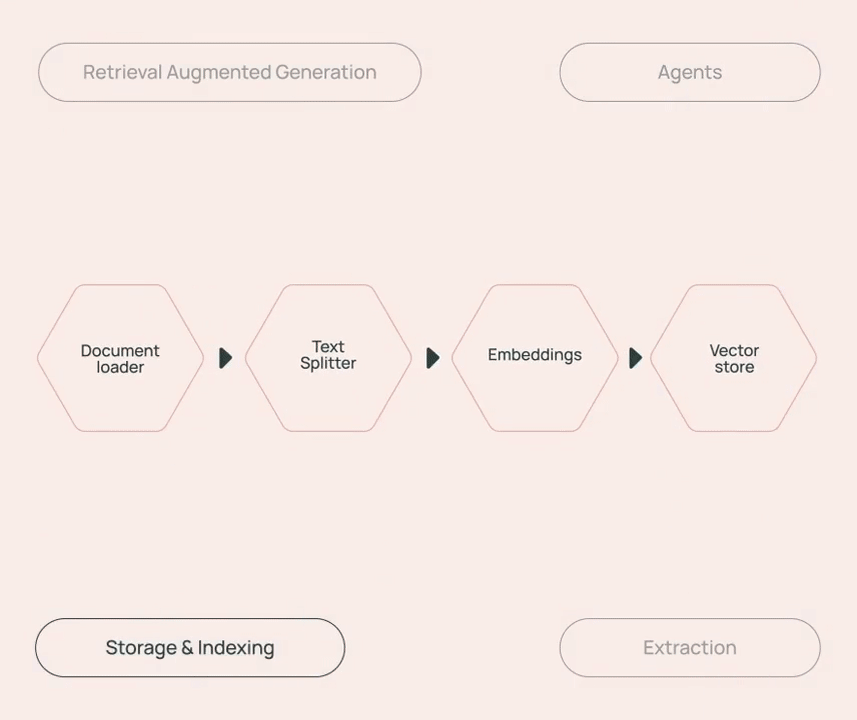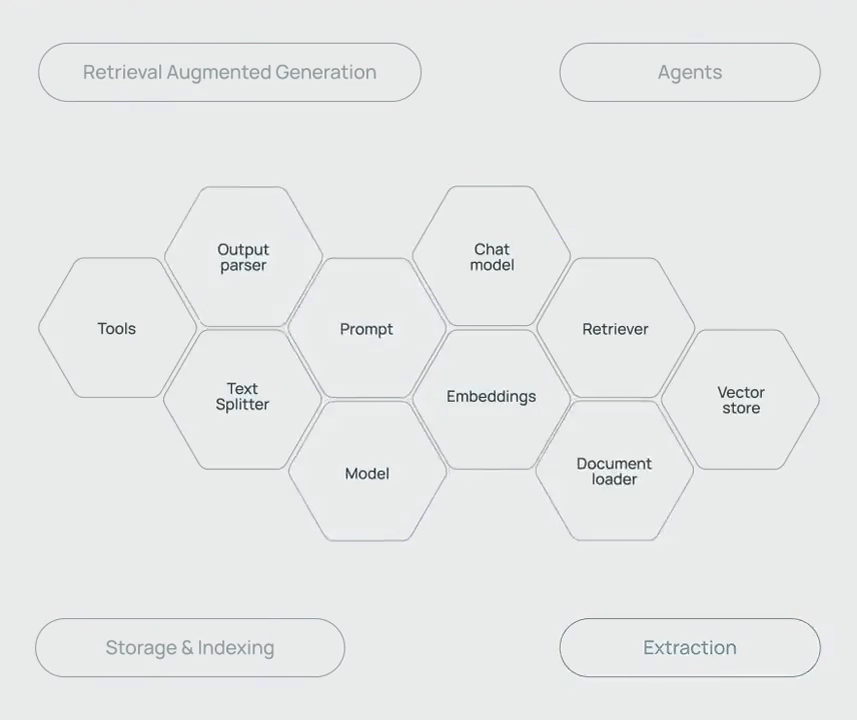
更具体地说,基于 LLM 构建应用程序的过程有点像在搭积木。即使模型本身的能力已经很强大了,我们依旧需要其他的组件和工具才能更好发挥其潜力。
比如聊天模型、提示模板、文本嵌入模型、文本分割器、文档加载器、检索器、向量存储等,这些工具的不同的搭配组合能够构建出各种的应用链,满足 RAG、Agent、存储&索引、信息提取等不同的应用需求。
举个例子,你想用 GPT-4 开发一个旅行顾问机器人,为用户提供行程方面的规划和建议。如果只依靠 GPT-4 在训练时学到的知识,没有实时查询最新的航班、酒店、景区信息,提供的建议就不可能准确实用。
借助 LangChain 框架,这个机器人就能链接到各种 API 和外部数据库,并记住用户的旅行偏好,甚至能根据用户的对话历史提供个性化建议。
这样听起来,LangChain 是一个非常强大的工具,流行起来也是理所应当。
然而,最近一个技术团队的博文登上了 HN 热榜,描述了他们从「入坑」LangChain 到「幡然醒悟」,最终决定抛弃这个热门框架的过程。

「为什么我们不再使用 LangChain 构建 AI agents——当抽象弊大于利时:在生产中使用 LangChain 的教训以及我们应该做什么」
底下的评论也纷纷附和,表示这个框架有种「代码糟糕」的感觉,而且把使用 LangChain 描述为一条「充满雷区的道路」。

「LangChain 的抽象就是死亡的定义。」

从大受追捧到「人人喊打」,LangChain 到底有什么样的问题?
问题浮现
这个技术团队在生产中使用 LangChain 已经超过 12 个月,开始于 2023 年初。
当时,LangChain 似乎是最佳选择,因为它拥有一系列令人印象深刻的组件和工具,并且承诺开发者「用一个下午将想法转变为可执行的代码」,流行程度飙升。
然而,随着需求逐渐变得复杂,LangChain 的不灵活性开始显现出来,开始阻碍生产力、成为摩擦的源头。
团队不得不深入研究框架的内部结构,以改善系统的底层行为。但因为 LangChain 有意通过抽象屏蔽细节,编写底层代码的尝试通常也不可行,或至少是十分复杂。
究其根源,作者认为是 LangChain 的抽象程度过高。在开发的初期阶段,较为简单的需求与框架的假设相一致,因此配合得很好。
但高级抽象很快使之后的代码变得难以理解、维护,团队花费在理解和调试 LangChain 上的时间越来越多,几乎赶上了真正构建功能所用的时间。
举个具体的例子,上代码:用 OpenAI 的包,将英语单词翻译为意大利语(没错,就是 GPT-4o 发布会 demo 的功能)
from openai import OpenAI client = OpenAI (api_key=" " ) text = "hello!" language = "Italian" messages = [ {"role": "system", "content": "You are an expert translator"}, {"role": "user", "content": f"Translate the following from English into {language}"}, {"role": "user", "content": f"{text}"}, ] response = client.chat.completions.create (model="gpt-4o", messages=messages) result = response.choices[0].message.content这段代码很好理解,包含一个 OpenAI 类的实例 client 以及一个函数调用,其余都是标准的 python 代码。
那如果用 LangChain 写呢?
from langchain_openai import ChatOpenAI from langchain_core.output_parsers import StrOutputParser from langchain_core.prompts import ChatPromptTemplate os.environ["OPENAI_API_KEY"] = " " text = "hello!" language = "Italian" prompt_template = ChatPromptTemplate.from_messages ( [("system", "You are an expert translator"), ("user", "Translate the following from English into {language}"), ("user", "{text}")] ) parser = StrOutputParser () chain = prompt_template model parser result = chain.invoke ({"language": language, "text": text})涉及到三个类、四个函数调用。但最令人担忧的是,一个如此简单的任务需要引入三个抽象概念——
-
提示模板(prompt template):为 LLM 提供提示
-
输出解析器(output parser):处理 LLM 的输出
-
链(chain):LangChain 的「LCEL 语法」覆盖了 Python 的「|」运算符
这似乎徒增代码复杂性,却没有任何额外的好处。
LangChain 似乎更适合早期原型,但不适合实际的生产使用。
对于后者而言,开发人员必须理解每一个组件,才能保证代码不会在真实的使用场景中意外崩溃,但 LangChain 限制他们必须遵守给定的数据结构和抽象概念,这无疑是额外的负担。
再举一个例子,这次是从 API 获取 JSON。
要使用 Python 内置的 http 包可以这样写:
import http.client import json conn = http.client.HTTPSConnection ("api.example.com") conn.request ("GET", "/data") response = conn.getresponse () data = json.loads (response.read () .decode ()) conn.close ()用 requests 包的写法则更加简洁:
import requests response = requests.get ("/data") data = response.json ()这感觉上就是好的抽象。虽然是微不足道的小例子,但足以说明一个观点——好的抽象可以简化代码,并能让人快速理解。
LangChain 的初衷是好的,它希望隐藏细节,让开发人员用更少的代码完成更多的功能。但如果代价是失去开发的简洁和灵活,这种抽象就失去了价值。
此外,LangChain 还习惯于「嵌套抽象」,在一个抽象概念之上再使用抽象。
这不仅让学习 API 的过程更加复杂,开发人员还不得不面对大量的堆栈跟踪信息,并调试那些自己不熟悉的内部框架代码。
以这个技术团队自己的开发为例,他们的应用程序使用大量 AI agent 执行不同类型的任务,比如测试用例发现、Playwright 测试生成和自动修复。
当他们想要从只有单个顺序代理的架构转向更复杂架构时,例如,生成 sub-agnet 并与原始 agent 交互,或者多个专业 agent 彼此交互,LangChain 就成为了限制因素。
另一个示例中,需要根据业务逻辑和 LLM 的输出,动态更改 agent 可访问工具的可用性。但 LangChain 没有提供从外部观察 agent 状态的方法,导致他们不得不缩小实现范围,以适应 LangChain 对 agent 可用功能的限制。
下决心删除 LangChain 之后,技术团队仿佛得到了真正的「解脱」。不仅工作高效了,内耗也少了。
一旦删除了它,我们就可以不用先将需求转化为适合 LangChain 的解决方案。我们只写代码就可以了。
抛弃 LangChain,下一个框架用什么?
事后,团队仔细反思复盘了这个问题。他们认为,长期来看,不使用框架是更好的选择。
LangChain 提供了一长串组件,让人感觉 LLM 驱动的应用程序很复杂,但其实并不是。核心组件只有几样——
-
用于 LLM 通信的客户端
-
函数或调用函数的工具
-
用于 RAG 的向量数据库
-
用于追踪、评估等功能的可观察平台
其余的组件,要么是以上核心组件的辅助(比如向量数据库的分块和嵌入),要么只是完成常规应用程序的任务(比如使用数据持久化和缓存,以管理文件和应用程序状态)。
如果不使用任何框架,毫无疑问会增加前期用于学习、调研的工作量,开发者需要更长时间来组建自己的工具箱。
但「磨刀不误砍柴工」,这些时间是值得的。在即将进入的领域打下基础,这对你本人和应用程序的未来都是良好的投资。
而且,很多情况下,使用 LLM 的流程都是非常简单直接的。开发人员主要编写顺序代码、迭代提示,并提高输出的质量和可预测性。绝大多数任务都可以通过简洁的代码和较小的外部包集合来实现。
即使用到了 agent,也不一定需要框架才能实现。在处理业务逻辑时,一般只需要在预定顺序流中进行 agent 之间的通信,处理它们的状态和响应,超出这个范围的工作内容并不多。
虽然 agent 领域正在迅速发展,并带来许多令人兴奋的用例和可能性,但在代理的使用模式逐渐固化的过程中,我们还是应该遵循简洁原则。
构建基本块,「轻装疾行」
假设技术团队没有在生产中混入垃圾代码,那么创新和迭代的速度是衡量成功的最重要指标,因为 AI 领域的许多发展都是由实验和原型设计驱动的。
这意味着,代码库需要尽可能精简且适应性强,才能最大限度提升开发人员的学习速度,每个迭代周期才能产生更多价值。
然而,「框架」的概念与此并不相容,它通常是人为设计出一种代码结构,为了匹配根据既有的使用模式。
但 LLM 驱动的应用还在发展阶段,没有固定的使用模式。当你不得不将创新的想法「翻译」为特定于某个框架的代码时,就限制了迭代速度。
因此,相比于使用框架,更好的办法是构建基本块(builing blocks),通过简洁的底层代码和精心挑选的外部依赖包,保持架构的精简,从而让开发人员专注于真正需要解决的问题。
「构建基本块」意味着简洁、可被完全理解,且不易变动。最典型的例子就是矢量数据库,它属于已知类型的模块化组件,只有基本功能,因此可以轻松被更换或取代。
因此,作者所在团队目前的策略是,完全不使用任何框架,用尽可能少的抽象进行模块化构建,从而让开发过程更快、更流畅。
虽然 LangChain 的槽点如此之多,但作者还是选择不过分苛责。某种程度上,这些缺陷都是无法避免的。
在 AI 和 LLM 这样快速变化的领域,每周都会涌现新的概念和想法。因此,想要在如此多新型技术中间创建 LangChain 这样的框架,并设计出经得起时间考验的抽象,是非常困难的。
作者非常坦诚地承认,如果当初是自己去构建 LangChain,也不会做得比现在更好。当一个「事后诸葛」指出错误总是容易的,这篇博文的目的并不是批评任何 LangChain 的开发人员或贡献者,因为每个人都在尽力而为。
即使能很好地理解需求,构建精心设计的抽象也是很困难的。因此在不断变动的条件下对组件(比如 agent)进行建模时,更安全的选择是仅对底层模块使用抽象。
参考资料:
https://www.octomind.dev/blog/why-we-no-longer-use-langchain-for-building-our-ai-agents






