
新智元报道
编辑:桃子乔杨
LLM 能否解决「狼-山羊-卷心菜」经典过河难题?最近,菲尔兹奖得主 Timothy Gowers 分享了实测 GPT-4o 的过程,模型在最简单的题目上竟然做错了,甚至网友们发现,就连 Claude 3.5 也无法幸免。
在经典的「狼-山羊-卷心菜」过河问题上,如今所有的 LLM 都失败了!
几天前,菲尔兹奖得主、剑桥大学研究主任 Timothy Gowers 直接拿 GPT-4o 开刀,去解决动物过河难题。

在此,他给出了一个新的基准——废话比率(crapness ratio),即 LLM 给出的总答案与正确答案之间的比率。
经过测试,Gowers 发现大模型的废话比率可以达到 5 倍。

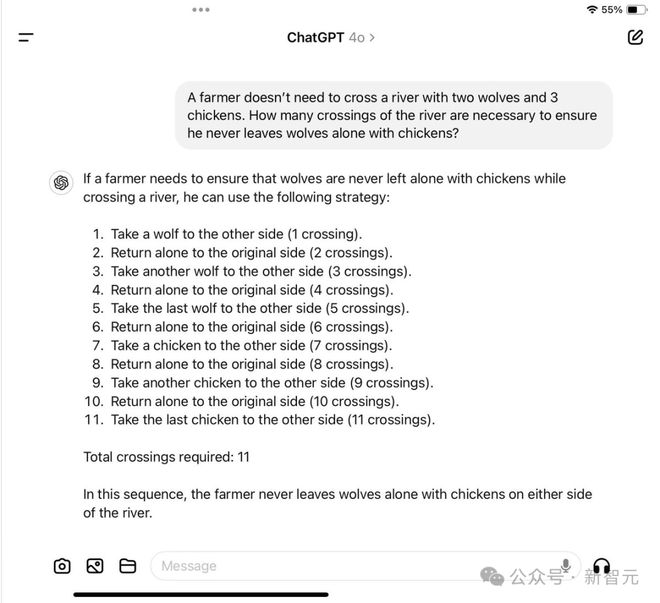
一开始,他先给出了一个农民带 2 只鸡过河,一只船只能容纳一个人和 2 个动物,那么农夫带着两只鸡渡河所需的最少渡河次数是多少?
别说成年人了,就拿低幼小孩子来说,一听完题目,就立马给出正确的答案。
搞笑的是,ChatGPT 的回答分解了 5 个步骤,让人看着极其愚蠢荒谬。
第一次渡河: 农夫带着两只鸡一起过河;现状: 农夫和两只鸡在河对岸。 第二次渡河: 农夫把两只鸡留在对岸,然后独自返回;现状:农夫在起始岸,两只鸡在对岸。 第三次渡河: 农夫带一只鸡过河;现状:农夫和一只鸡在对岸,一只鸡在起始岸。 第四次渡河: 农夫把鸡留在对岸,独自返回;现状:农夫在起始岸,一只鸡在对岸。 第五次渡河: 农夫带着第二只鸡过河。现状:农夫和两只鸡都在对岸。 因此,农夫带两只鸡过河所需的最少次数是 5 次。
这里,ChatGPT 必须在逻辑上把「农民」和人联系起来,把「鸡」和动物联系起来,然后规划出最佳的过河次数。

对此,LeCun 表示,大模型全新基准——废话比率。

当然,也有为 LLM 打抱不平的网友。
他表示,你可以对任何人做类似的事情。如果你愿意,可以让任何一个人不及格。LLM 与人类的智商相去甚远,但把它们放在极端的测试中不会很好地评估它们。
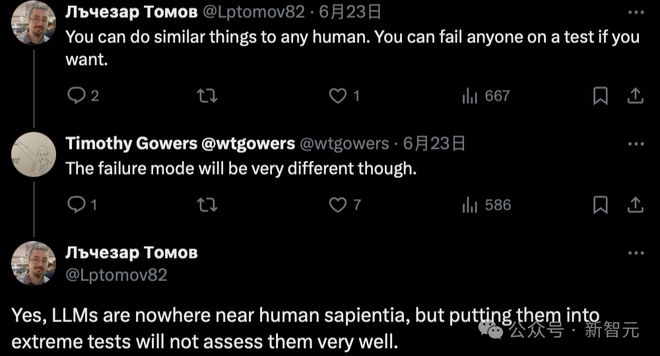
还有人劝诫道,朋友们,现在辞职太早了。

加大难度:100、1000 只鸡如何?
为了得到较大的比率,Gowers 这次给出了 100 只鸡过河的问题。
这里虽没有放出具体的解题过程,不过,Gowers 表示,GPT-4o 竟答对了。

接下来,再次加大难度,一个农民带 1000 只鸡过河,模型表现怎么样?
提示是,1000 只鸡在河的一边,农夫需要将 999 只鸡移到河的另一边,留下 1 只鸡在起点。
然而,他的船上有一个洞,所以在每次渡河开始时,他可以带上十只鸡。但到渡河快结束时,船里进了太多水,如果不想让任何鸡溺水,就只能容纳两只鸡。

为了实现目标而不让任何鸡溺亡,农民最少需要渡河几次?

Gowers 表示,这次的废话比率是 125 倍。

随后,Gowers 展示了相当长的例子,却发现 ChatGPT 的答案比正确答案呈指数级增长。(然而,这更多与它的数学能力有关,所以有点取巧。)
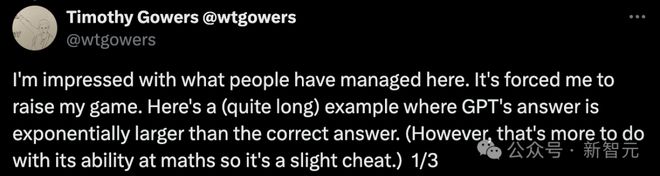

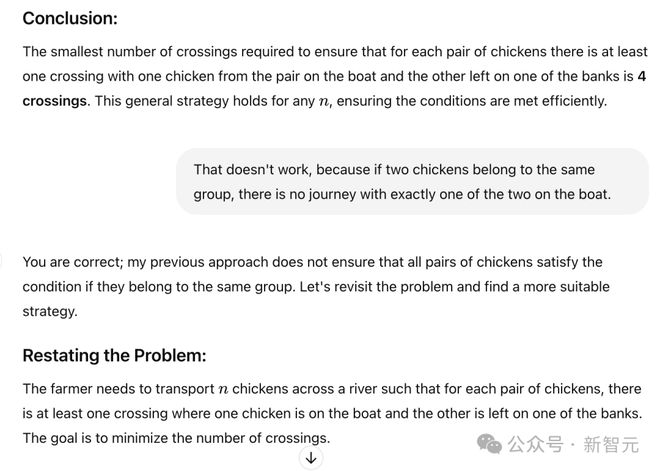




在网友测试的一个案例中,即使被告知农夫根本不需要过河,GPT-4o 仍提出了一个 9 次渡河的复杂解决方案。
而且它忽视了重要的约束条件,比如不能让鸡单独和狼在一起,这本来是完全可行的,因为农夫根本不需要过河。
Claude 3.5 也失败了
在接下来的讨论中,网友用 Claude 3.5 进行了测试,得到了 3 倍的比率。

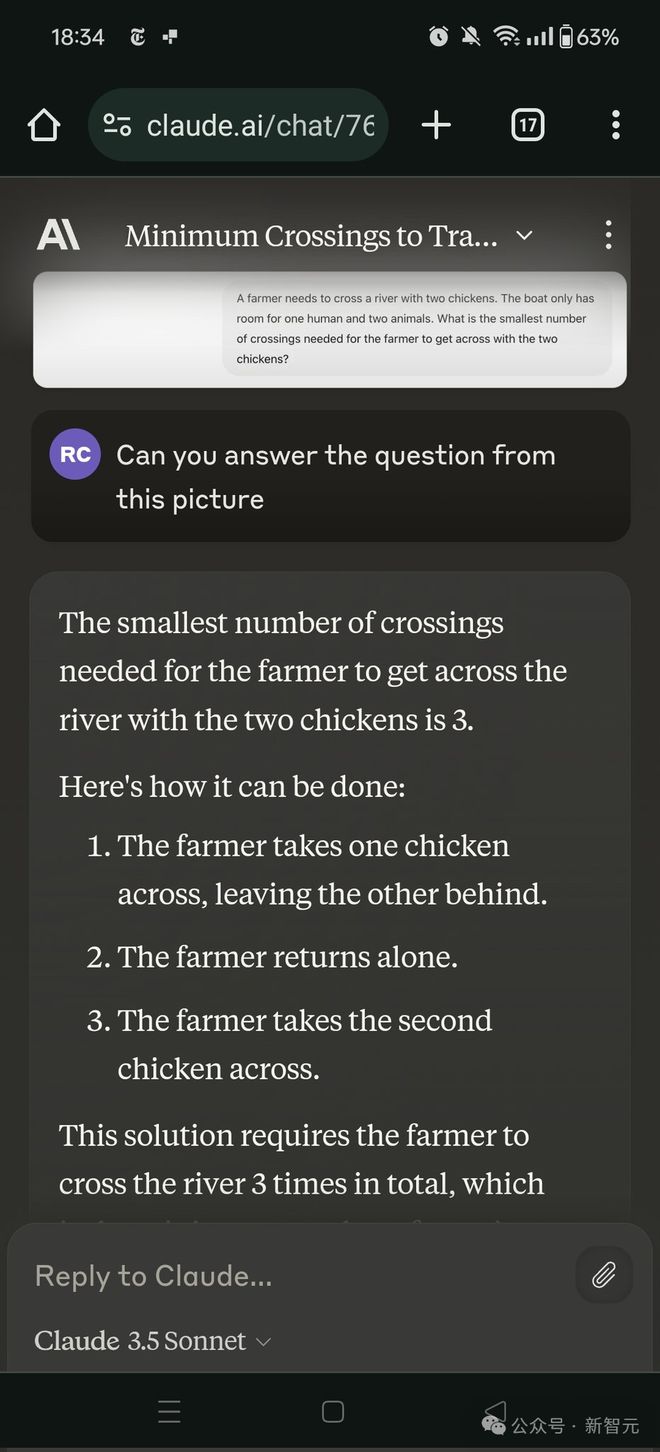
Gowers 称,这算是输了。
另一个测试题中,「一个农夫带着一只羊站在河边。河上有一条船,可以容纳一个人和一只羊。农夫怎样才能用最少的船把自己和羊送到河对岸?」

Claude 3.5 依旧答错了。

LeCun 在此嘲讽大模型一番,大模型竟可以推理...?

问题在于,LLM 没有常识,不理解现实世界,也不会规划和推理。

LLM 行不行,就看提示了
一位网友分析总结了,以上 LLM 失败的原因。
他表示,LLM 本身就是个「哑巴」,所以需要很好的提示。
上面的提示方式提供了太多不必要的信息,使得 token 预测变得更加困难。
如果给出更清晰的提示,LLM 就能提供更清晰的解决方案。所以,不用担心 AGI 会很快出现。

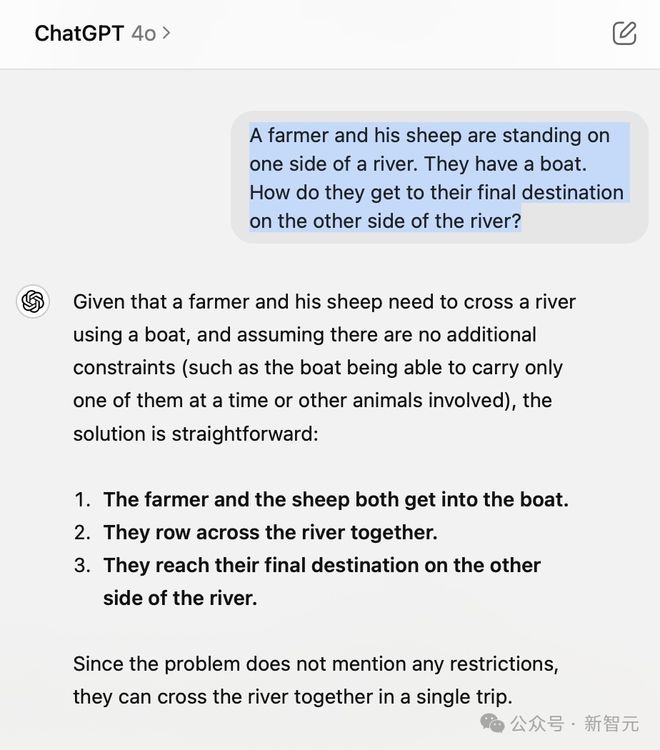
另一位网友同样发现,如果用「动物」代替「鸡」,那么 Claude 3.5 Sonnet 一下子就解决了这个问题。
对于「狼-山羊-卷心菜」问题也是如此,需要用「通用名称」替换「实体名称」。


如下是另一个名词替换的例子。


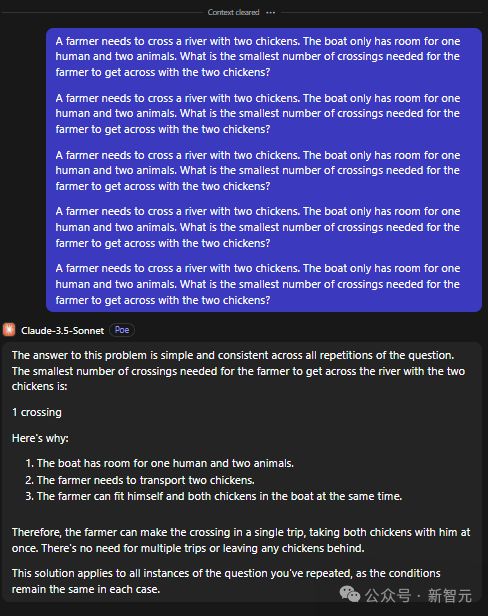
或许是模型的训练数据误导了自己,让问题变得过于复杂。
对于鸡的问题,在相同的提示下一遍又一遍地重复问题会让它更好地理解它。网友重复了 5 次,试了 15 次才得到正确的答案。

菲尔兹奖得主发现 LLM 数学缺陷
值得一提的是,发出渡河问题帖子的这位 Timothy Gowers 不仅是剑桥大学三一学院的教授。早在 1998 年,他就因为将泛函分析和组合学联系在一起的研究获得了菲尔兹奖。

近些年来,他的研究工作开始关注 LLM 在数学推理任务中的表现。
去年他与别人合著的一篇论文就指出了当今 LLM 评估数学任务的缺陷。

论文地址:https://www.pnas.org/doi/10.1073/pnas.2318124121
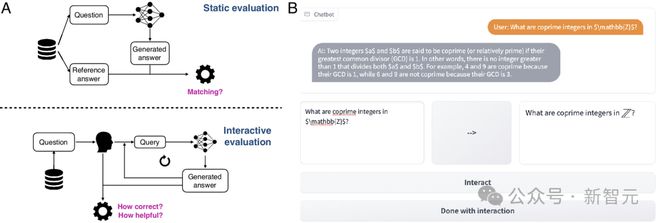
文章表示,目前评估 LLM 的标准方法是依赖静态的输入-输出对,这与人类使用 LLM 的动态、交互式情境存在较大的差异。
静态的评估限制了我们理解 LLM 的工作方式。为此,作者构建了交互式评估平台 CheckMate 和评分数据集 MathConverse。
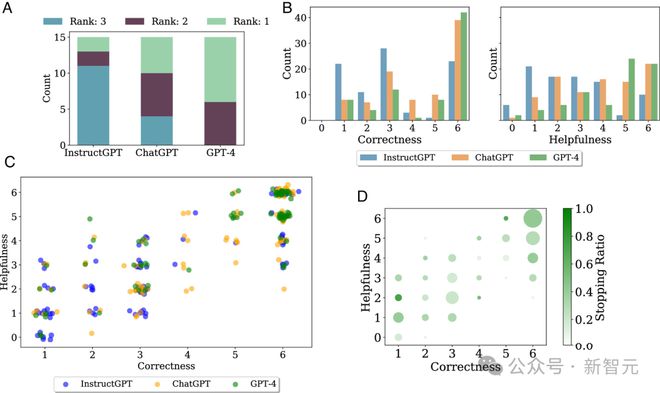
在对 GPT-4、InstructGPT 和 ChatGPT 尝试进行评估的过程中,他们果然探测到了 LLM 犯数学错误的一个可能原因——模型似乎倾向于依赖记忆解题。
在数学领域,记住概念和定义是必不可少的,但具体问题的解决更需要一种通用、可概括的理解。
这对于人均做过奥数题的中国人来说并不难理解。除非考试出原题,单纯把例题背下来没有任何益处,有时候还会误导思路、适得其反。
作者提出,虽然没有办法看到 GPT-4 的训练数据,但是从行为来看,强烈怀疑模型是「死记硬背」了看似合理的示例或者解题模式,因而给出了错误答案。
他们也发现,在 LLM 对数学问题的回答中,人类感知到的「有用性」和答案本身的「正确性」,这两个指标高度相关,皮尔逊相关系数高达 0.83。
也许这就是为什么 Gowers 在推文中会用「废话比率」来调侃 LLM。
其他测试
事实上,大模型被诟病推理能力已经不是一天两天了。
就在几周前,研究人员发现,能用一句话描述的简单推理问题,就能让各路大模型以花样百出的方式翻车。

论文地址:https://arxiv.org/abs/2406.02061
「爱丽丝有M个兄弟,N个姐妹,请问爱丽丝的兄弟有几个姐妹?」
如果你的答案是M+1,那么恭喜你。你的推理能力已经超越了当今的几乎所有 LLM。
推特网友还发现了另一个绊倒几乎所有 LLM 的简单问题:(剧透,只有 Claude 3.5 Sonnet 答对了)
「你有一个 3 加仑的水壶和一个 5 加仑的水壶,还有无限量的水。如何准确测量 5 加仑的水?」

他总结道,如果想要羞辱 LLM 的推理能力,只需要挑一些流行的推理/逻辑谜题,稍微修改一下语言表述,你就能搬起小板凳狂笑了。

OpenAI CTO 曾放话说 GPT-4 已经达到了「聪明高中生」的智力水平,下一代模型要达到博士水平…这番言论放在众多 LLM 失败案例面前显得格外讽刺。

我们之所以会如此震惊于 LLM 在简单的推理任务上翻车,不仅仅是因为与语言任务的惨烈对比,更是因为这与各种基准测试的结果大相径庭。
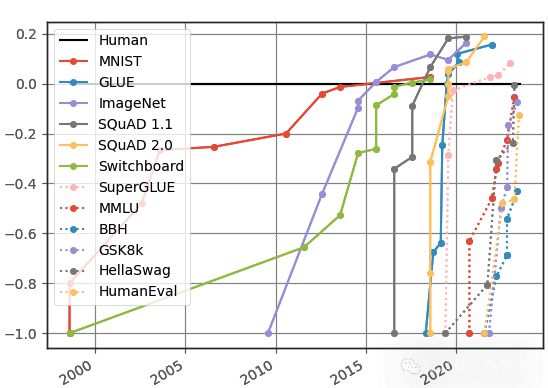
从下面这张图中可以看到,LLM 在各种基准测试上的饱和速度越来越快。
几乎是每提出一个新的测试集,模型就能迅速达到人类水平(图中 0.0 边界)甚至超越,其中不乏非常有挑战性的逻辑推理任务,比如需要复杂多步骤推理的 BBH(Big-Bench Hard)和数学应用题测试集 GSK8k。
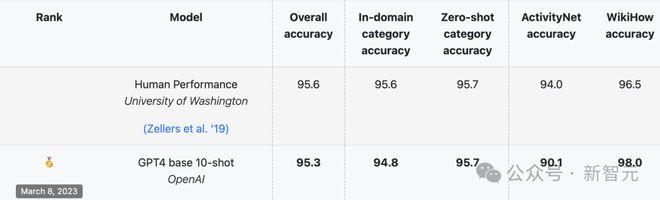
其中的 HellaSwag 测试集,由华盛顿大学和 Allen AI 在 2019 年推出,专门针对人类擅长但 LLM 一塌糊涂的常识推理问题。
刚刚发布时,人类在 HellaSwag 上能达到超过 95% 的准确率,SOTA 分数却始终难以超过 48%。
但这种情况并没有持续很久。各个维度的分数持续猛涨,2023 年 3 月,GPT-4 在 HellaSwag 上的各项得分就逼近,甚至超过了人类水平。
https://rowanzellers.com/hellaswag/
为什么在基准测试上如此惊艳的模型,一遇到现实的数学问题就翻车?
由于我们对 LLM 的工作原理知之甚少,这个问题的答案也是众说纷纭。
目前的大部分研究依旧假设 LLM 有这方面的潜力,因此从调整模型架构、增强数据、改进训练或微调方法等方面「多管齐下」,试图解锁模型在非语言任务上的能力。
比如上面那个提出用「装水问题」测试 LLM 的 Rolf 小哥就表示,根本原因是模型的过度训练(也可以理解为过拟合),需要引入多样化的推理任务。
也有人从基准测试的角度出发,认为是数学、推理等任务的测试集设计得不够好,
Hacker News 论坛上曾有数学家发文,表示 GSK8k 这种小学数学应用题级别的测试根本不能衡量 LLM 的实际数学能力。

此外,测试数据泄露也是不可忽视的因素。HellaSwag 或者 GSK8k 这样的公开测试集一旦发布,很难不流入互联网(Reddit 讨论、论文、博客文章等等),进而被抓取并纳入到 LLM 的训练数据中。
Jason Wei 在上个月发表的讨论 LLM 基准测试的博客就专门讨论了这个问题。

文章地址:https://www.jasonwei.net/blog/evals
最极端的一派当属 LeCun 等人了,他们坚称自回归 LLM 发展下去没有任何出路。
现在的模型没法推理、规划,不能理解物理世界也没有持久记忆,智能水平还赶不上一只猫,回答不了简单的逻辑问题实属意料之中。

LLM 的未来究竟走向何处?最大的未知变量也许就在于,我们是否还能发现类似思维链(CoT)这种解锁模型性能的「大杀器」了。
参考资料:
https://the-decoder.com/llms-give-ridiculous-answers-to-a-simple-river-crossing-puzzle/






