
新智元报道
编辑:耳朵
昨晚,谷歌正式开源了自家最强的开源模型 Gemma 2,直指为全球范围研究开发者提供实用部署工具。
就在昨晚,谷歌的明星开源大模型系列,又迎来两位新成员——Gemma 2 9B 和 Gemma 2 27B!

四个月前谷歌宣布重磅开源 Gemma,四个月后 Gemma 2 上线,专门面向研究和开发人员。
目前,模型权重已经在 HuggingFace 上公开。
项目地址:https://huggingface.co/collections/google/gemma-2-release-667d6600fd5220e7b967f315
Gemma 2 的核心亮点概括来说就是:参数虽小但性能极佳。
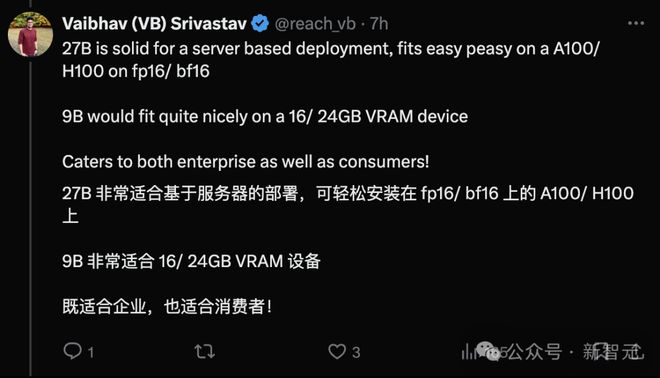
而且,27B 模型甚至可在单张谷歌云 TPU、英伟达 A100 80GB GPU 或英伟达 H100 GPU 上,以全精度高效运行推理。
高效新模型的诞生
Gemma 2 在设计的架构上均有创新,旨在实现卓越的性能和提高推理效率。
在技术报告中,Gemma 2 最引人注目的三大创新优势在于:
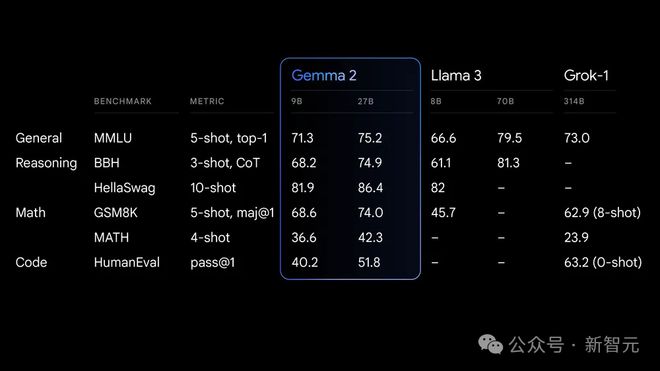
首先,性能远超同同等规模模型。
Gemma 2 27B 在同类产品中性能最佳,甚至能挑战规模更大的模型。
Gemma 2 9B 的性能在同类产品中也处于领先地位,超过了 Llama 3 8B 和其他同规模的开源模型。
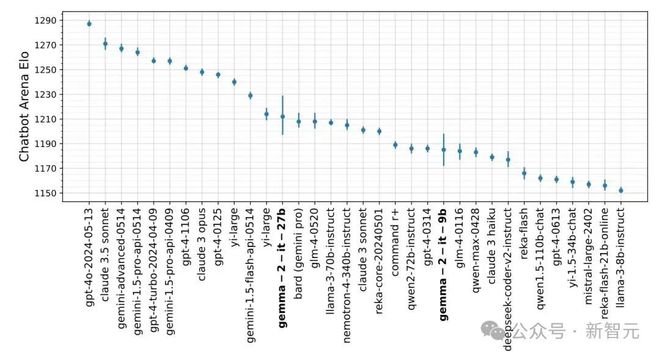
与其他大模型在 Lmsys 同场竞技,同等规模模型中 Gemma 2 的性能「一览众山小」。
其次,超高效率,节约成本。
27B 模型可用于在单个谷歌 Claude TPU 主机或 NIVIDIA H100 GPU 上以全精度高效运行推理,从而在保持高性能的同时大幅降低成本。
用较小的模型规模能够在更广泛的硬件上部署,对于开发者和研究人员带来许多便利。
最后,能够跨硬件快速推理。
Gemma 2 经过优化,可在各种硬件上以惊人的速度运行。
比如在 Google AI Studio 中尝试全精度的 Gemma 2,在 CPU 上使用量化版本 Gemma.cpp 解锁本地性能,或通过 Hugging Face Transformers 库在配备英伟达 RTX 或 GeForce RTX 的家用电脑上,均可使用。
高效的源头:架构创新
Gemma 是谷歌团队推出的一系列轻量级、先进的开源模型,基于与 Gemini 模型相同的研究和技术构建的文本生成解码器大型语言模型。
Gemma 2 训练数据量大约是第一代的两倍,并沿用了上一代的基本架构,但进行了全方位的改良。
局部滑动窗口和全局注意力
Gemma 2 交替使用局部滑动窗口注意力和全局注意力层级进行切换,局部注意力层的滑动窗口大小设置为 4096 个 token,而全局注意力层的设置为 8192 个 token。
在正确捕捉文本细节的同时,又能保持对上下文和全局的正确理解。
Logit 软上限
按照 Gemini 1.5 版,Gemma 对每个注意层和最终层的 logit 进行软封顶。
通过将 logits 设置在一个合理的固定范围内,可以有效提升训练的稳定性,防止内容过长。
使用 RMSNorm 进行前后归一化
为了使训练更加稳定,Gemma 2 运用了 RMSNorm 对每个转换层、注意层和反馈层的输入和输出进行归一化。
这一步和 Logit 软上限都使得模型训练更稳定平滑,不易出现崩溃。
分组查询注意力
GQA 通过对于注意力分组,将算力用于一组注意力的组内。
在计算时显示出更快的数据处理速度,同时还能保持下游性能。
知识蒸馏
传统训练大语言模型的方法主要是根据上一个 Token,预测下一个 Token,需要大量的数据进行训练。
但是,人类的学习过程并不依赖走量的知识输入。比如,一位学生由于阅读原著的需要学习一门外语,他并不需要看遍所有的书籍,只需要以一本书为纲,通过理解后融会贯通。
而知识蒸馏法与人的学习过程更加类似。一个小模型向另一个已经进行过预训练的大模型学习,通过这种方式助产小模型对于 Token 的预测。
站在老师模型的肩膀上,学生模型能用较少的训练数据达到更好的效果。
功能强大,实用为先
人工智能有可能解决人类一些最紧迫的问题,但前提是每个人都拥有使用人工智能的工具。
因此,Gemma 2 非常注重实用性,轻量级且开源是 Gemma 2 最核心的两个关键词。
Gemma 2 同样沿用了 Gemma 1 的许可证,使开发人员和研究人员能够共享他们的创新成果并将其商业化。
此外,Gemma 2 具有广泛的框架兼容性。
Gemma 2 可通过本地 Keras 3.0、vLLM、Gemma.cpp、Llama.cpp 与 Ollama、Hugging Face Transformers 等主要人工智能框架兼容,从而轻松地将 Gemma 2 与个人偏好的工具和工作流程结合使用。
从下个月开始,Google Cloud 客户将能够在 Vertex AI 上轻松部署和管理 Gemma 2。
例如,用户可以自己探索新的 Gemma Cookbook,其中包含一系列实用示例和 codebook;也可指导构建自己的应用程序,并针对特定任务微调 Gemma 2 模型。
因此,Gemma 2 对于个人使用非常便利,能够轻松地将 Gemma 与各类工具结合使用,包括用于精准检索等常见任务。
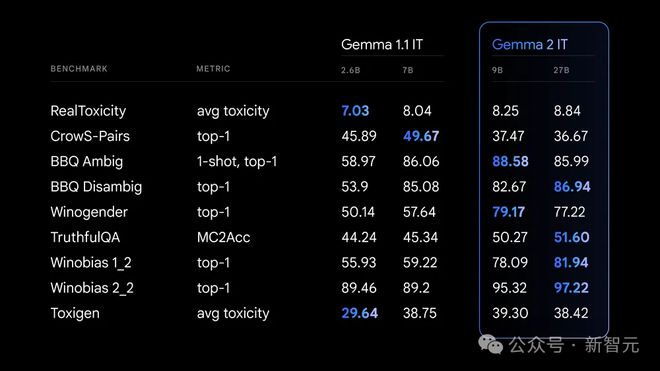
对 AI 安全性的提升
Gemma 2 在实用高效的同时,也从安全角度做出了新举措。
谷歌提供了「负责任的生成式 AI 工具包」,LLM Comparator 可以让开发人员和研究人员深入评估语言模型,使用实用工具的同时保证安全部署。
就个人用户而言,可以使用配套的 Python 库对模型和数据运行比较评估,并在应用程序中将结果可视化。
另外,在训练 Gemma 2 时,预训练数据都经过了严格的筛选,并根据一套安全指标进行严格的测试和评估,以识别并降低潜在的偏差和风险。
可以看出,AI 安全在成为越来越多人关注的问题后,谷歌着重平衡了智力进展和安全保障。希望在后续的网友测评中,不会再出现 Gemini 1.5 Pro 的翻车案例了。
打造史上「最亲民」大模型
Gemma 首次推出后,下载量超过 1000 万次。
全球各地都使用 Gemma 制作项目。例如,Navarasa 利用 Gemma 创建了一个植根于印度语言多样性的模式。

Gemma 2 目前可以在 Google AI Studio 中使用,在 Gemma 27B 下测试其全部性能,而无需硬件要求。
此外,为方便研发人员使用,Gemma 2 还可通过 Kaggle 或谷歌 Colab 免费获取。
参考资料:






