克雷西发自凹非寺
量子位公众号 QbitAI
Claude 3.5 Sonnet 的图表推理能力,比 GPT-4o 高出了 27.8%。
针对多模态大模型在图表任务上的表现,陈丹琦团队提出了新的测试基准。
新 Benchmark 比以往更有区分度,也让一众传统测试中的高分模型暴露出了真实能力。

该数据集名为CharXiv,内容全部选自 arXiv 论文中的真实图表,共计 2323 张。
相比此前的 FigureQA 等测试基准,CharXiv 涵盖的任务类型更加广泛,而且不按套路出牌,难度大幅增加。
为了宣传这套新 Benchmark,研究团队还写出了一首洗脑神曲,并制作了视频宣传片。
【视频请到公众号查看】
这段魔性的宣传片,让有些网友表示已经被成功“洗脑”,脑海中充满了(歌词中的)“2323 张图表”。
导师陈丹琦也感到印象十分深刻,直言这是自己见过最 fancy 的视频。
那么,CharXiv 究竟新在哪,又难在哪呢?
来自学术论文的图表测试集
团队指出,过去的表格测试标准太过简单,而且不能反映模型的真实水平。
比如 FigureQA、DVQA 和 ChartQA 的子集,只要稍作简单修改,模型的成绩就能下降超过1/3。
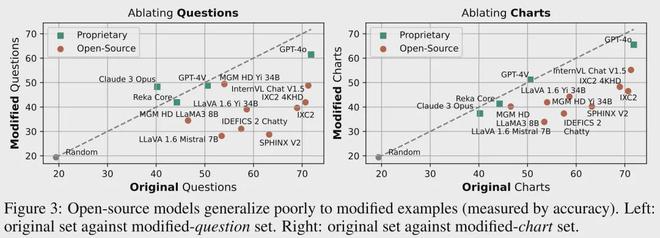
究其原因,作者认为是之前的数据集中图表都是由程序合成,问答也高度模板化。
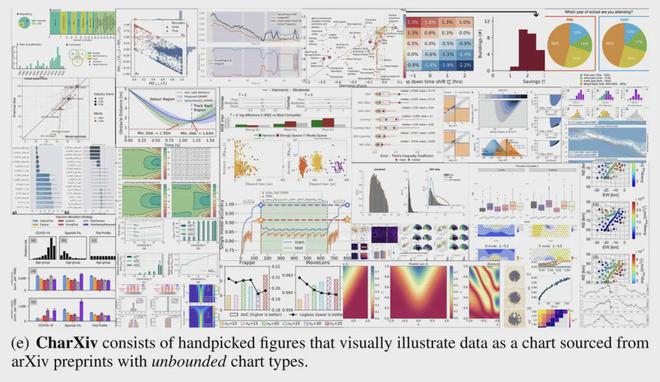
于是,研究团队提出了 CharXiv,由人类专家从 arXiv 论文中精心选择了 2323 个真实图表。
图表的类型也更加丰富,提出的问题也避免了套路化的问题。
根据重点考察能力的不同,作者将测试题目分成了两类——描述性问题和推理性问题。
两类问题的比例为4:1,即每张图表配有 4 个描述性问题和 1 个推理性问题。
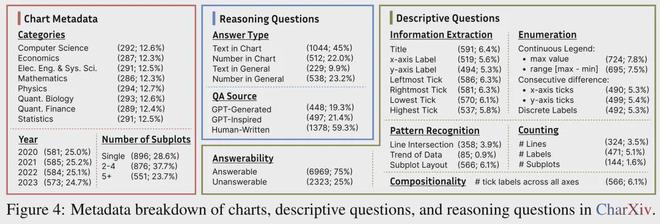
其中描述性问题包括信息提取(Information extraction)、列举(Enumeration)、计数(Counting)、模式识别(Pattern recognition)等等。
这当中,模式识别指的是要求模型识别图表中数据的趋势和分布模式,如线条是否相交、数据是递增还是递减等。
另外还有较难的组合型(Compositionality)任务,模型需要综合多个视觉元素的信息回答问题,体现图表信息的组合理解。
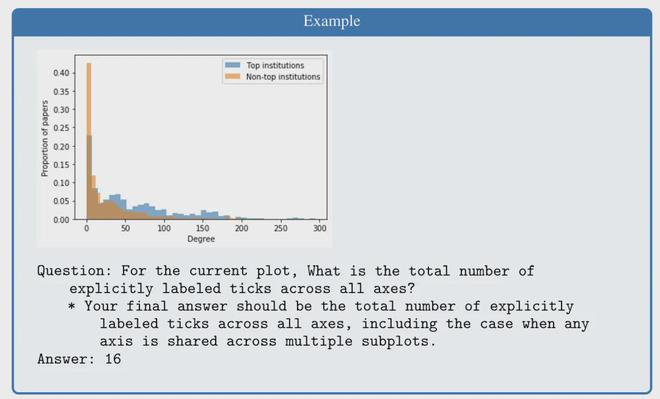
比如这道题目就是一道组合型的描述类问题,它需要在识别清楚坐标轴的同时,完成计数的任务:
在当前的图表中,所有坐标轴中一共有多少明确标记的刻度?(这里问的是标记的数量,不是求和)
推理性问题则根据答案出现的方式又分为了四个子类:
- Text-in-chart:问题的答案是图表中出现的文本,如图例标签、离散刻度标签等。
- Text-in-general:问题的答案是一个易于验证的文本短语,但不一定显式出现在图表中。
- Number-in-chart:问题的答案是图表中给出的一个数值,,如坐标轴刻度值。
- Number-in-general:问题的答案是一个精确到特定小数位数的数值,但可能需要通过阅读和推理才能得出,而不一定直接出现在图表中。
举个例子,下面的问题要求模型对表格中各列的数值进行求和,然后比较后给出和最小的一列对应的标签,这就是一项推理型任务。

利用这套数据集,作者在零样本的条件下评估了一些知名的开源和闭源模型。
模型依然不擅长推理
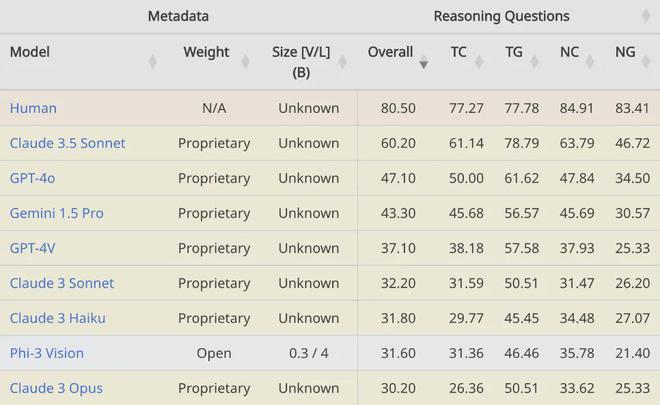
在推理类问题上,作者发现所有模型的表现都不是很理想。
表现最好的是真人,模型当中则是 Claude 3.5 Sonnet,不过也仅仅及格,和人相比还是差了四分之一,成绩超过 40 的模型一共也只有三个。
紧随其后的是 GPT-4o、Gemini 1.5 Pro 和 Claude 3 家族,有意思的是,Claude 3 的“超大杯”Opus,表现还不如小一些的 Sonnet 和 Haiku。
开源模型中,表现最好的是微软的“小”模型 Phi-3,参数量一共只有 4B,成绩却跻身到了 Claude 3 家族的中间。
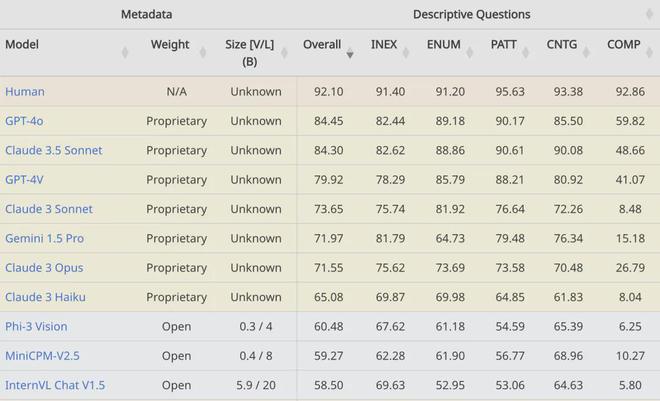
在描述类任务当中,表现最好的依然是人类,但模型和人类的差距小了,表现最好的 GPT-4o 和人类只差了不到 10%。
不过开源模型的表现就不那么好了,分数最高的 Phi-3 才刚刚及格。
另外,其中的组合型问题(COMP)任务,对于模型来说也依旧是难点,没有任何一个模型得分超过 60,而人类的表现是大于 90 的。
例如,数出x轴和y轴上的刻度标签数量,对于人来说是十分简单的任务,但测试下来,20 个模型在该任务中的准确率无一达到 10%。
而且,随着子图数量的增加,模型的描述能力也会下降。当有 6 个以上子图时,商业模型的成绩会下降 10-30%,开源模型对子图的处理则更加困难,性能下降比例达到了 30-50%。
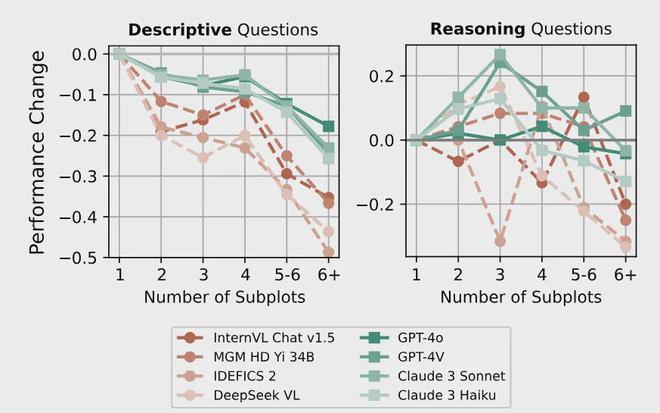
经过综合比对,作者发具备良好描述能力是推理能力的前提——推理能力强的模型一般描述能力也强,但描述强的模型推理能力不一定强。当模型无法准确描述图表时,即使使用思维链(CoT)推理,成绩也不会提升。
论文地址:






