
新智元报道
编辑:桃子
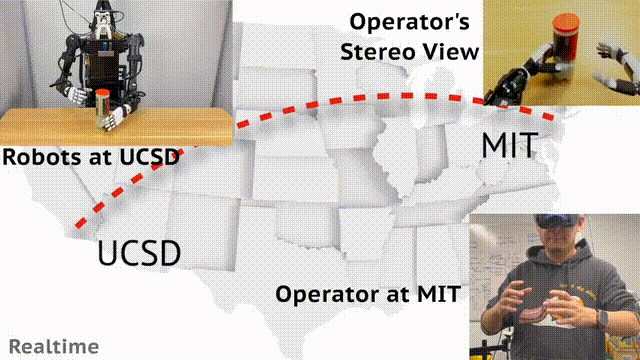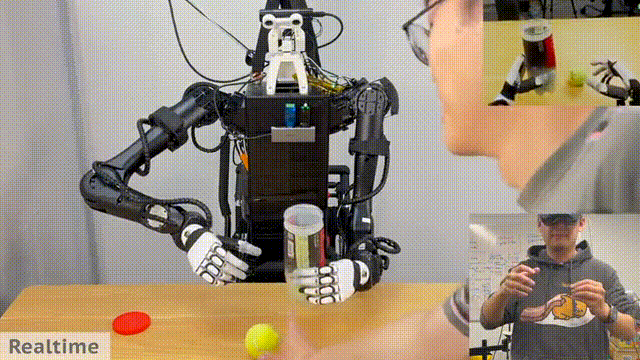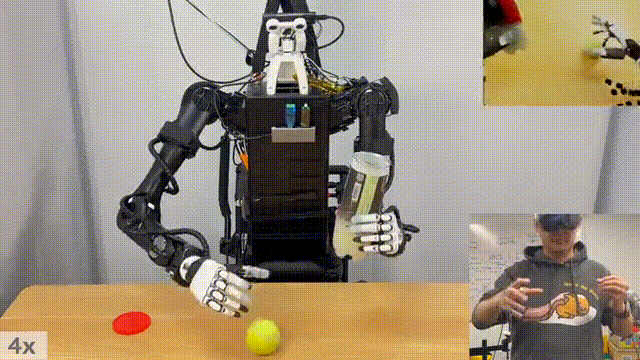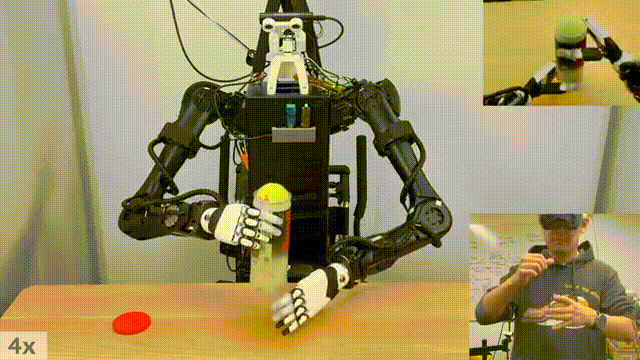
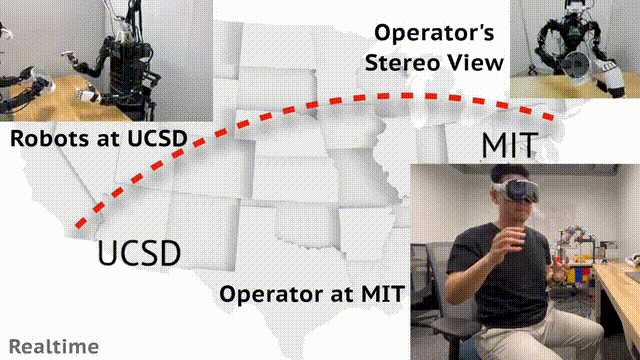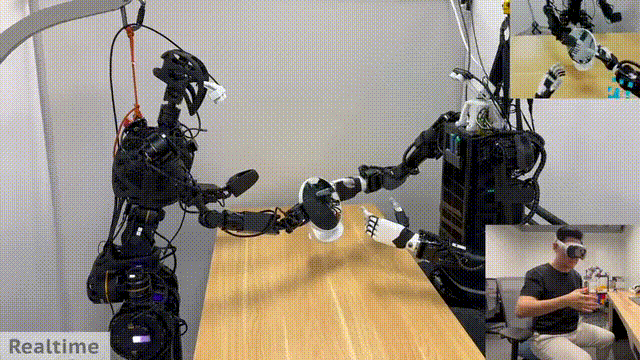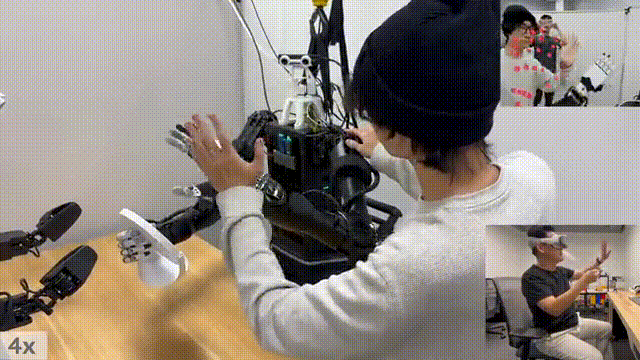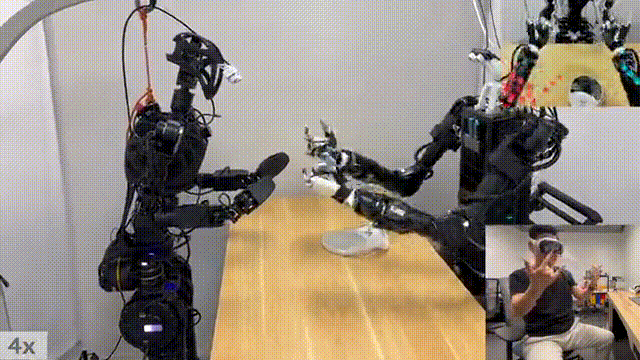
现实中,机器人收据收集可以通过远程操控实现。来自 UCSD、MIT 的华人团队开发了一个通用框架 Open-TeleVision,可以让你身临其境操作机器人,即便相隔 3000 英里之外。
你是否曾想过,自己身处某地,可以控制几千公里以外的「机器人」本体?
这个想法,最近被来自 UCSD 和 MIT 的华人学者们实现了。
UCSD 位于加利福尼亚州,MIT 位于马萨诸塞州,这两地之差,约 3000 英里(4800 公里)。
不过,MIT 的研究人员竟通过头戴 Apple Vision,实现了远程操控 UCSD 实验室中的机器人,效果让人为之惊叹。
只见人类空手做出了手持易拉罐的动作,机器人在另一边也做出了同步的动作,然后依次将 6 罐芬达放置在了盒子里。
完成之后,人类做了 OK、以及手势,机器人也跟着有模有样,做了出来。
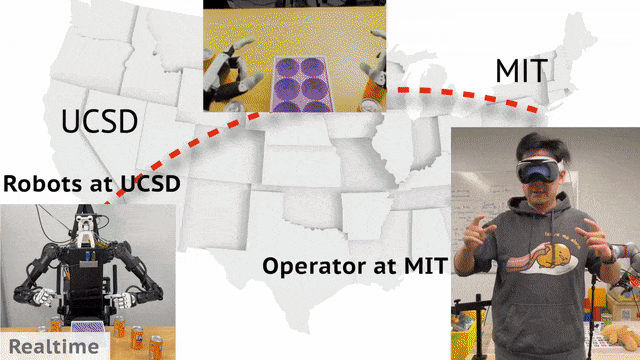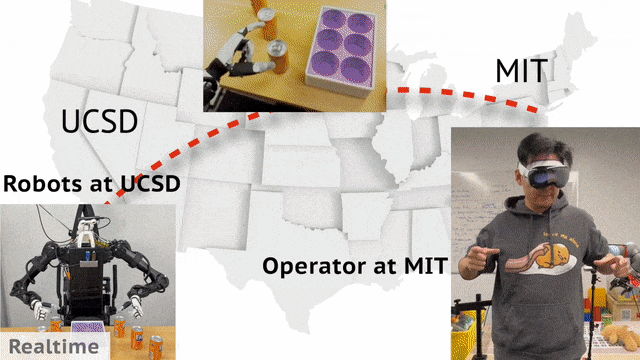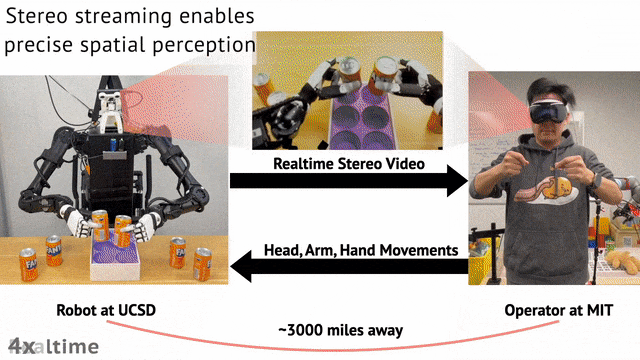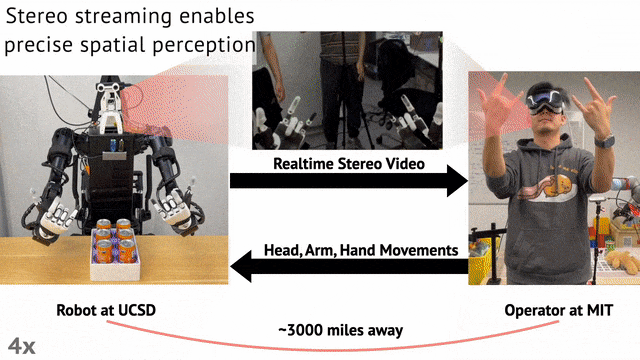
这一想法之所以能够实现,背后源于研究者提出了一个沉浸式的远程操作系统——Open-TeleVision。

论文地址:https://robot-tv.github.io/resources/television.pdf
Open-TeleVision 创新之处在于,可以提供立体式感知环境,实现操作者动作到机器人的精确镜像,创造出一种沉浸式体验。
正如论文作者所言,仿佛操作者的思维被传输到了机器人的身体中。
值得一提的是,你不仅可以用头显,还可以用笔记本、iPad、甚至是手机,完成对机器人的远程操控。
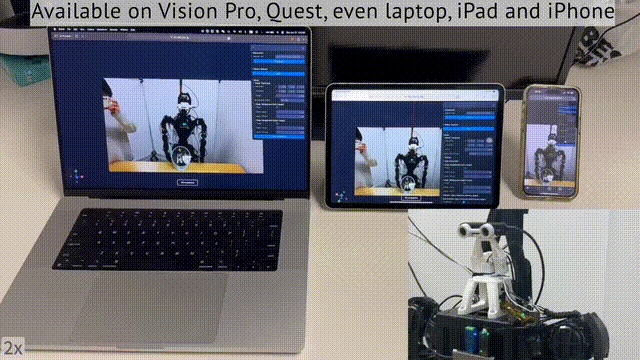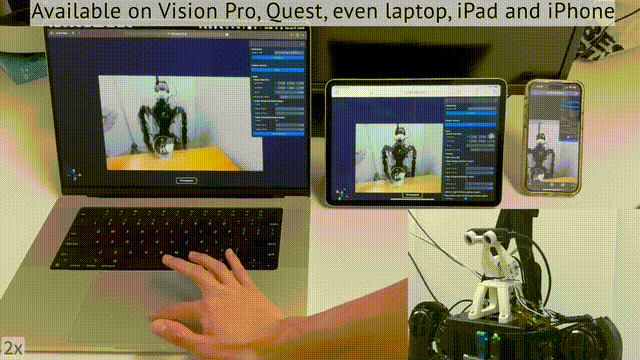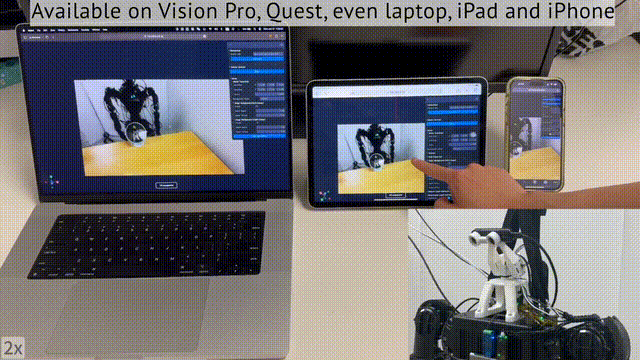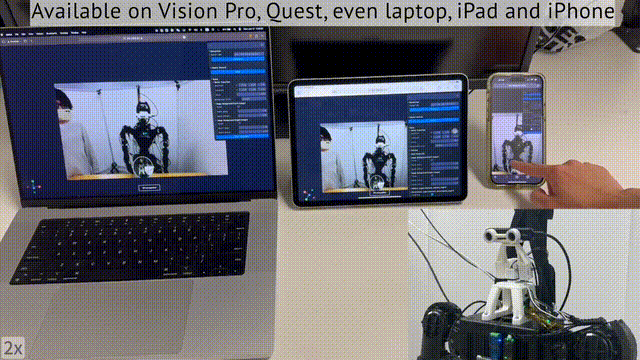
那么,这项研究意义何在?
现实生活中,机器人能够学习的数据非常少。远程操控的方法,可以用于收集机器人行示范中学些所需的真实机器人数据。
研究人员正式希望通过 Open-TeleVision 这一方式,进一步帮助这一领域探索出更多的场景数据。
远程操控,让机器人替人类打工
可以畅想下,有了这样的技术,我们未来生活会有怎样的巨变?
在实验室闷头苦干的人不一定非得是自己,你可以在家即可操控机器人,取样本、分析都能完成。

而且流水线上的工人们,可能要被这些机器人逐渐取代。看着将耳塞精准熟练地装进透明的盒子,足见其强大。

它们还可以胜任收银员的工作,一手拿着扫码器,一手拿着商品,逐一完成扫码任务。

建筑工地中,一些危险的活儿,也能交由它们做。拿着电锯在指定位置打孔,不得不说真的强。

你还可以让机器人作为你的化身,陪你做游戏。

友好互动,机器人做的也是毫无违和感。

下面这是一个超有爱的画面,只见机器人将 Hellokitty 挂件递给女生后,还做出了比心的动作。

再来看看更多,跨越更远区域的演示。
研究人员做装网球的动作,机器人将现实中物体装进桶中。
下面这个比较有意思,MIT 研究人员控制一台机器人,向与另一台机器人传递镜子。
以上皆是远程操控完成任务的案例,不过研究者开发的系统,也能够让机器人本体,自主去完成一些精准的任务。
比如,分类不同易拉罐饮料。

叠毛巾等等。

看过这么多精彩演示,你一定想了解其背后的技术原理,不如一起来看看。
技术介绍
正如开头所述,研究人员开发了一种通用框架 Open-TeleVision,可以应用到不同机器人、机械手臂上,用 VR 设备完成高精度远程操控。
通过捕捉人类操作者的手部姿势,作者执行重定向操作,来控制多指机器人手或平行夹持器。
另外,研究者依靠逆运动学将操作者的手根位置,转换为机器人手臂末端执行器的位置。


整体的系统概述如下图 2 所示。
研究人员基于 Vuer 开发了一个网络服务器。VR 设备将操作者的手、头和手腕的姿态以 SE (3) 的形式流式传输到服务器,服务器负责处理人类到机器人的动作重定向。
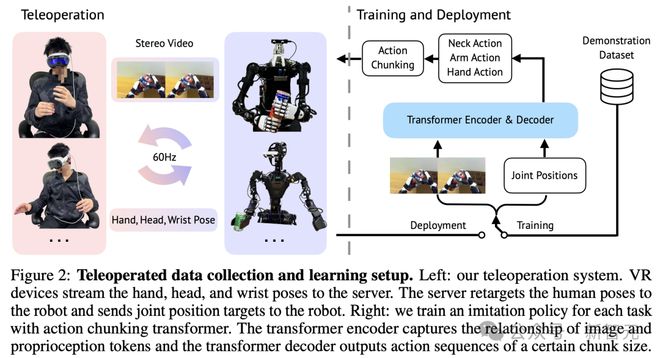
图 3 展示了机器人的头部、手臂和手如何跟随人类操作者的动作。
反过来,机器人以每只眼睛 480x640 的分辨率流式传输立体视频,整个循环以 60Hz 的频率进行。

硬件配置
具体来说,研究人员对两种机器人进行了实验,如下图 4 所示。
它们分别是人形机器人 Unitree H1,以及配备夹持器的 Fourier GR-1,来执行双手操作的任务。
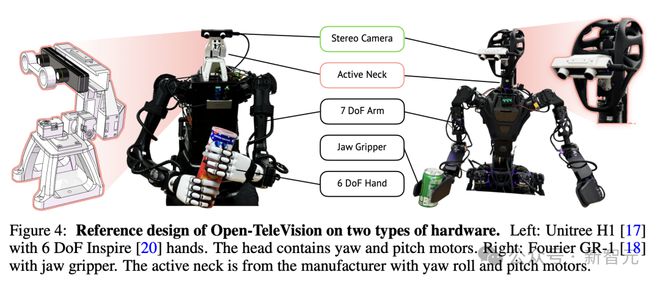
对于主动感知,研究人员专为 H1 设计了一个具有两个旋转自由度(偏航和俯仰)的云台,安装在躯干顶部。
这个云台由 3D 打印部件组装而成,由 DYNAMIXEL XL330-M288-T 电机驱动。

对于 GR-1,他们使用了厂商提供的 3 自由度颈部(偏航、滚动和俯仰)。
两种机器人都使用 ZED Mini 立体相机提供立体 RGB 视频流。
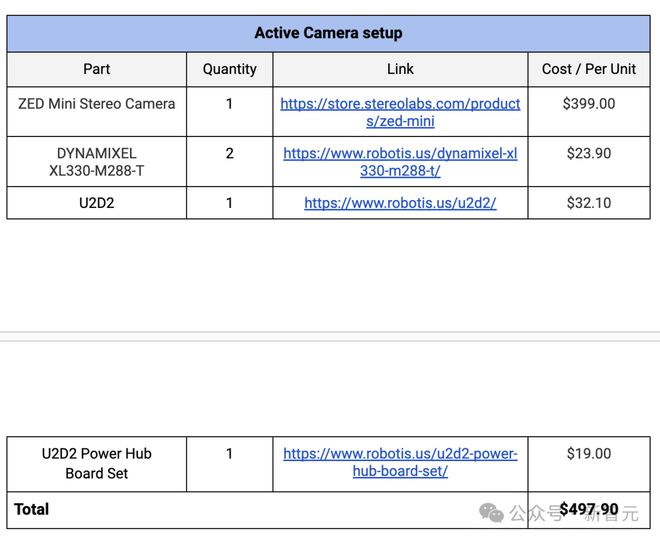
具体材料费用细节,下表列出了一些要点。
有了所具备的硬件,就要开启实验了。
实验结果
论文中,研究人员主要研究了两个问题:
- Open-TeleVision 系统的关键设计选择如何影响模仿学习结果的表现?
- Open-TeleVision 远程操作系统在收集数据方面的效率如何?
这里,研究人员选择 ACT 作为模仿学习的算法,并进行了两项关键修改。
一是,用更强大的视觉骨干网络 DinoV2 替换了 ResNet。DinoV2 是一个通过自监督学习预训练的视觉 Transformer(ViT)。
二是,使用两个立体图像作为 Transformer 编码器的输入,而不是使 4 个独立排列的 RGB 相机的图像。
DinoV2 骨干网络为每张图像生成 16 × 22 个 token。状态 token 是从机器人当前的关节位置投影而来的。
对于 H1 机器人,动作维度是 28(每个手臂 7 个,每只手 6 个,主动颈部 2 个)。对于 GR-1 机器人,动作维度是 19(每个手臂 7 个,每个夹持器 1 个,主动颈部 3 个)。
具体实验中,作者选择了四个强调精确性、泛化能力,以及长期规划的任务,以展示 Open-TeleVision 的有效性,如下图 5 所示。

模仿学习
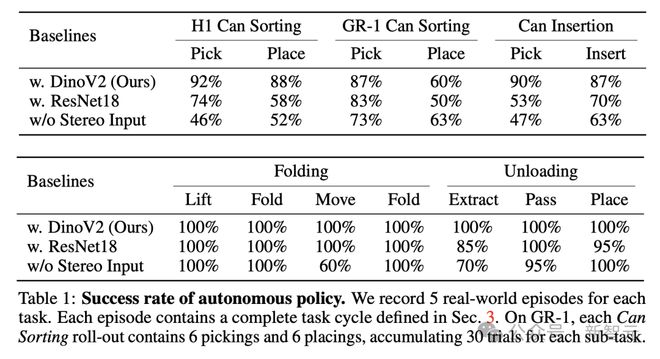
在易拉罐分类任务中,分别评估了拾取罐子的成功率和将其放置到指定位置的准确性。根据表 1 中 H1 的结果,Open-TeleVision 在这两项评估指标上都具有最高的成功率。
在拾取子任务中,新模型始终优于其他两个基准模型。
在毛巾折叠任务中,研究者的模型和使用 ResNet18 的模型都达到了 100% 的折叠成功率。
泛化能力
此外,研究人员在随机化条件下评估了模型的泛化能力。
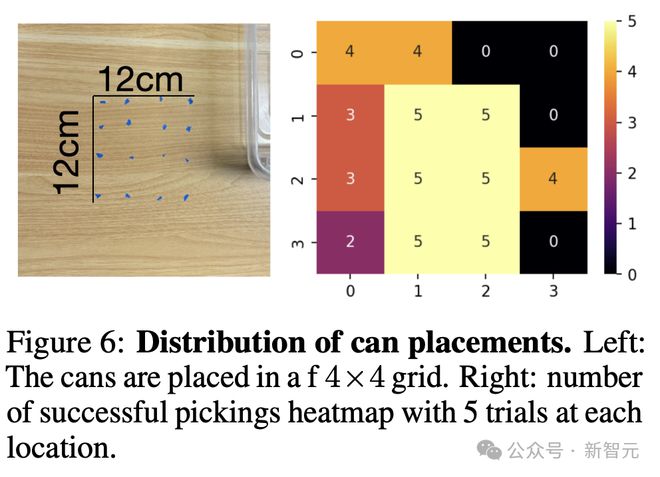
在使用 H1 进行的罐子分类任务中,评估了模型从一个 4x4 网格(每个网格单元为 3 厘米)中拾取罐子的成功率,如图6(左)所示。
详细结果在图6(右)中展示,这表明新策略能很好地泛化到数据集中覆盖的大面积区域,实现 100% 的成功率。
与此同时,TeleVision 系统在相同批量大小下训练速度提高了 2 倍,并且在 4090 GPU 上可以在一个批中容纳 4 倍的数据。
在推理过程中,TeleVision 系统也快了 2 倍,为逆运动学(IK)和重定向计算留出了足够的时间,以达到 60Hz 的部署控制频率。

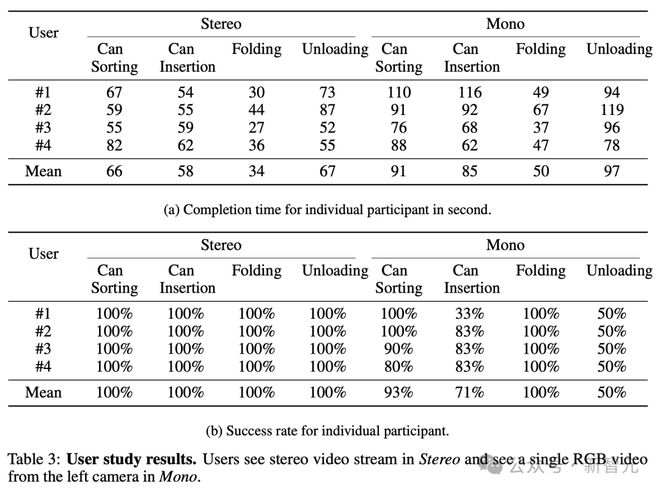
针对用户研究,可以看出不同用户对机器人在任务分类中的偏好。
在图 8 中,展示了 Open-TeleVision 能够执行的更多远程操作任务,比如木板转孔、耳塞包装任务,液体试管。

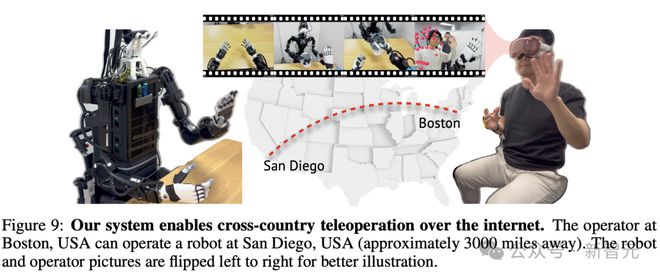
如图 9 所示,Open-TeleVision 系统还实现了远程操作。
总而言之,这项研究中提出了一个沉浸式远程操作系统 Open-TeleVision,实现了精确的任务操作。
不过,作者也指出,系统仍缺乏其他形式的反馈,比如触觉。
而且在第一人称视觉被遮挡和需要大量触觉任务中,触觉反馈通常是主要的反馈形式。
一个能够重新标记专家数据的系统,对提高成功率可能非常有帮助,这也是当前系统所缺失的。
参考资料:






