鱼羊西风发自凹非寺
量子位公众号 QbitAI
大模型圈再曝抄袭大瓜,这回,“被告”还是大名鼎鼎的谷歌 DeepMind。

“原告”直接怒喷:他们就是把我们的技术报告洗了一遍!
具体是这么个事儿:
谷歌 DeepMind 一篇中了顶流新生代会议 CoLM 2024 的论文被挂了,瓜主直指其抄袭了一年前就挂在 arXiv 上的一项研究。开源的那种。

两篇论文探讨的都是一种规范模型文本生成结构的方法。
抓马的是,谷歌 DeepMind 这篇论文中确实明晃晃写着引用了“原告”的论文。

然鹅,即便是标明了引用,“原告”的两位论文作者 Brandon T. Willard(布兰登)和R´emi Louf(雷米)还是坚称谷歌抄袭,并认为:谷歌对两者差异性的表述“简直荒谬”。
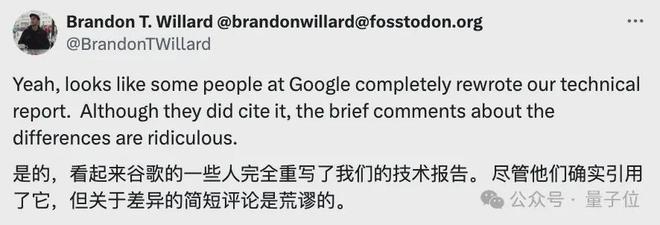
而不少网友看过论文后也缓缓打出一个问号:CoLM 是怎么审的稿?

唯一区别是换了概念?

赶紧瞅一眼论文对比……
两篇论文的比较
先浅看一眼两篇论文的摘要对比。
谷歌 DeepMind 的论文说的是,tokenization 给约束语言模型输出带来了麻烦,他们引入自动机理论来解决这些问题,核心是避免在每个解码步骤遍历所有逻辑值(logits)。
该方法只需要访问每个 token 的解码逻辑值,计算与语言模型的大小无关,高效且易用于几乎所有语言模型架构。
而“原告”的说法大致是:
提出了一个高效框架,通过在语言模型的词汇表上构建索引,来大幅提升约束文本生成的效率。简单来说,就是通过索引避免对全部逻辑值的遍历。
同样“不依赖于具体模型”。

方向上确实大差不差,我们还是接着来看看更多详细内容。
我们用谷歌 Gemini 1.5 Pro 分别总结了两篇论文的主要内容,并接着让 Gemini 来比较两者的异同。
对于“被告”谷歌这篇论文,Gemini 总结其方法是将 detokenization 重新定义为有限状态转换器(FST)操作。
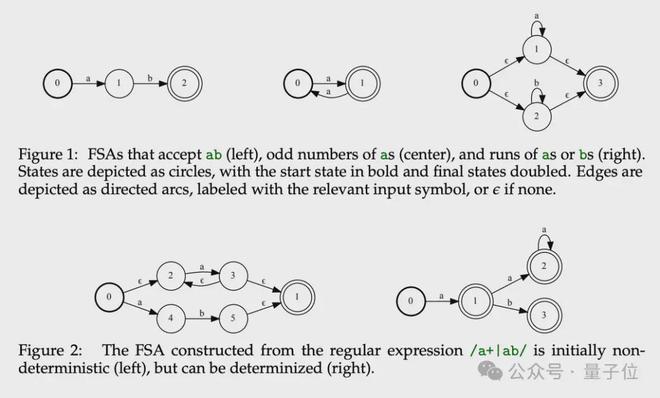
将此 FST 与表示目标形式语言的自动机组合,这种自动机可以用正则表达式或语法来表示。
通过以上结合,生成一个基于 token 的自动机,用于在解码过程中约束语言模型,确保其输出的文本符合预设的形式语言规范。
此外,谷歌论文中还进行了一系列正则表达式扩展,这些扩展通过使用特别命名的捕获组来编写,显著提升了系统处理文本时的效率和表达能力。
而对于“原告”论文,Gemini 总结其方法的核心是将文本生成问题重新定义为有限状态机(FSM)之间的转换。
“原告”的具体方法是:
- 利用正则表达式或上下文无关文法构建 FSM,并将其用于指导文本生成过程。
- 通过构建词汇表索引,高效地确定每个步骤中的有效词,避免遍历整个词汇表。
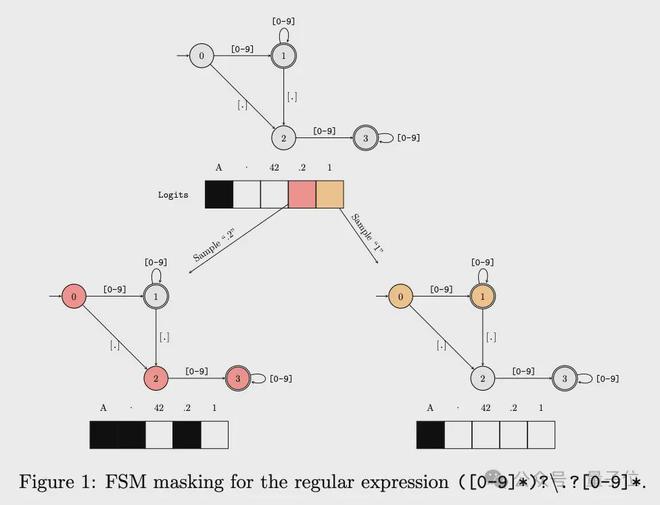
Gemini 列出了两篇论文的共同点。

至于两者的区别,有点像前头那位网友说的,简单总结就是:谷歌将词汇表定义为了一个 FST。

前面也说到了,谷歌在“Related work”中将原告论文列为“最相关”的一项工作:
最相关的研究是 Outlines(Willard&Louf, 2023),该研究同样采用有限状态自动机(FSA)和下推自动机(PDA)作为约束手段——我们的方法是在 2023 年初独立开发的。
谷歌认为两者的差异在于,Outlines 的方法基于一种特制的“索引”操作,需要手动扩展到新的应用场景。相比之下,谷歌使用自动机理论彻底重新定义了整个过程,使得应用 FSA 和泛化到 PDA 变得更加容易。
另一个区别是,谷歌定义了扩展以支持通配符匹配,并提高了可用性。

谷歌紧接着在介绍下面的两项相关工作中,也都提到了 Outlines。
一项是 Yin 等人(2024 年)通过增加“压缩”文本段到预填充的功能,扩展了 Outlines。
另一项是 Ugare 等人(2024 年)近期提出的一个系统,名为 SynCode。它也利用 FSA,但采用 LALR 和 LR 解析器而非 PDA 处理语法。
与 Outlines 类似,该方法依赖于定制算法。
但吃瓜群众们显然不是很买账:
CoLM 的评审们应该注意。我不认为这看上去是各自独立的“同期工作”。
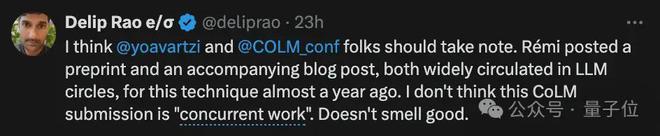
网友:这事儿不罕见…
这件事一发酵,不少网友都怒了,抄袭可耻,更何况“科技巨头剽窃小团队的工作成果不是第一次了”。
顺便一提,布兰登和雷米发布原告论文的时候都在给 Normal Computing 远程工作,这家 AI Infra 公司成立于 2022 年。
哦对了,Normal Computing 的创始团队有一部分就来自 Google Brain……

另外,布兰登和雷米现在合伙出来创业了,新公司名叫 .txt,官网信息显示,其目标是提供快速可靠的信息提取模型。并且官网挂出的 GitHub 主页,就是 Outlines 仓库。
说回到网友这边,更让大家伙儿生气的是,“这种情况已经变得普遍”。
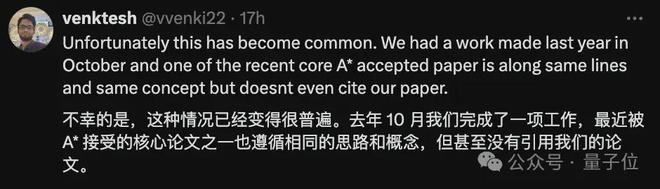
一位来自荷兰代尔夫特理工大学的博士后分享了自己的遭遇:
去年 10 月我们完成了一项工作,最近有篇已被接收的论文采用了相同的思路和概念,但甚至没有引用我们的论文。
还有一位美国东北大学的老哥更惨,这种情况他遭遇过两次,下手的还都是同一个组。并且对面那位第一作者还给他的 GitHub 加过星标……

不过,也有网友表达了不同的意见:
如果说发个博客文章或未经评估的预印本论文就算占坑了,那人人都会占坑,不是吗?

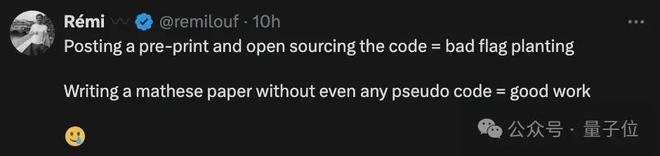
对此,雷米怒怼:
好家伙,发布预印本论文并开源代码 = 占坑;
写篇数学论文,甚至不需要任何伪代码 = 好工作???
布兰登老哥也表示 yue 了:
开源代码并撰写相关论文是“占坑”,复制别人的工作却说“我更早有了这个想法”且投稿了会议反而不是啦?真恶心。

瓜就先吃到这里,对此你有什么想法?不妨在评论区继续讨论~
两篇论文戳这里:
谷歌 DeepMind 论文:https://arxiv.org/abs/2407.08103v1
原告论文:https://arxiv.org/abs/2307.09702
参考链接:
[1]https://x.com/remilouf/status/1812164616362832287?s=46
[2]https://x.com/karan4d/status/1812172329268699467?s=46
[3]https://x.com/brandontwillard/status/1812163165767053772?s=46






