
新智元报道
编辑:编辑部
最近,多个机构学者合著的一篇研究为 AI 的规模化指了一条新路:物理神经网络(PNN),这一新兴的前沿领域还鲜少有人涉足,但绝对值得深耕!AI 模型再扩展 1000 倍的秘密可能就藏在这里。
随着 Scaling Law 越来越成功,LLM 的电力和算力消耗也逐渐达到了惊人程度。我们越来越难以想象,当前的模型规模如何能再扩大 10 倍、100 倍,甚至 1000 倍。
即使扩大 1000 倍的模型能够实现,它的能耗还能在人类负担范围内吗?能在智能手机或传感器这些边缘设备上进行本地推理吗?
要回答这些问题,我们需要重新思考 AI 模型的工作和训练方式,尤其是要转换视角,首先考虑底层硬件的物理约束。
或许,物理神经网络 PNN(physical neural network)就是我们要找的答案。
最近,一篇有关 PNN 训练的综述性论文登上了 HN 热榜。作者提出,基于过去几年的研究,我们有理由认为,PNN 可以从根本上改变 AI 系统的可能性和实用性,实现前所未有的模型规模。

论文地址: https://arxiv.org/abs/2406.03372
论文的合著者列表也是星光璀璨,云集了众多顶尖机构,包括微软研究院、DeepMind、剑桥、耶鲁、康奈尔、斯坦福、普朗克研究所、EPFL、UCLA 等。
文章力证,虽然迄今为止 PNN 依旧是在实验室演示阶段的小众领域,但可以说是现代人工智能领域最被低估的重要机会之一。
之前对 PNN 的研究和回顾一般集中在光学、电子学等领域,而这篇论文则是从训练角度,尽可能探索 PNN 的发展,并且不限于特定领域。
PNN 是什么
作者首先提出,当前典型的 AI 系统存在高能耗、低吞吐率、高延迟等问题,其中的核心矛盾在于内存和处理单元的分离,而且两者之间的数据传输速度较低。
由于看到了这些性能限制,研究人员对可替代当前 AI 系统的其他计算平台重新产生了兴趣,例如光学、光子学和模拟电子学。
论文将这些非常规计算平台统称为 PNN,指代利用物理系统的属性执行计算的一种类神经网络,与当前深度学习使用的人工神经网络(artificial neural network, ANN)相区分。
和 ANN 类似,PNN 系统同样使用可训练权重处理输入数据,但不同之处在于,系统中至少有一部分是模拟的而非数字的。
这意味着部分或者全部的输入/输出数据被连续编码为物理参数,权重也可以是物理参数,以期在性能和效率上超越数字硬件。
从是否模仿数字神经网络的角度,PNN 可以被分为两类(图 1a):同构(isomorphic)PNN,和破坏同构(broken-isomorphism)PNN。
前者会设计出严格的、逐个操作的数学同构的硬件来执行数学变换,比如用于矩阵-向量乘法的忆阻器交叉开关。
相比之下,后者则会彻底打破数学同构的想法,直接训练硬件的物理变换。但这种方法的复杂之处在于,我们不知道通用计算或通用函数逼近需要哪些特征。
相比数字方法,破坏同构 PNN 的计算效率更高,从而为速度更快、更有扩展性、能量效率更高的机器学习方法开辟了道路。
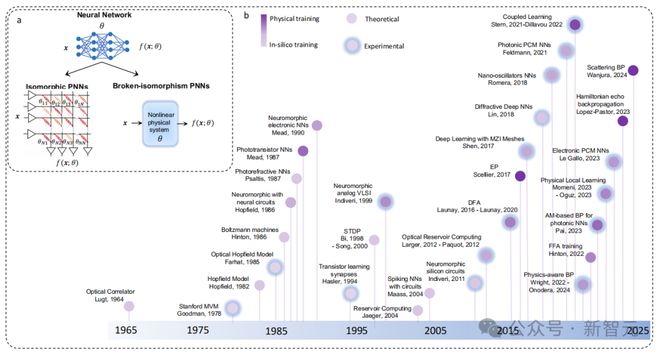
PNN 训练方法发展时间表
PNN 的训练
下图展示了 PNN 训练生态中的 10 种方法,论文对其中 7 种进行了较为详细的论述。目前来看,这些方法各有利弊,谁也不能完全取代谁,大有「百花齐放」之势。
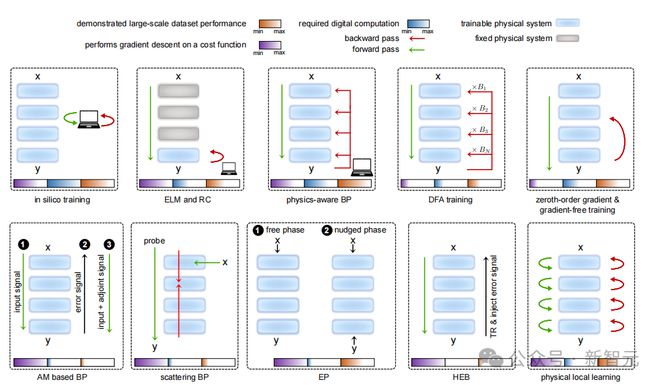
PNN 训练方法生态系统
计算模拟(In-Silico)训练
用于训练 PNN 的计算机模拟方法涉及数字模拟和优化硬件的物理自由度()。
在训练阶段先采用基于物理的前向模型和/或数字神经网络在计算机环境中创建 PNN 的数字孪生,并针对特定任务优化,之后根据优化结果部署硬件,用于新数据的模拟处理。
计算模拟训练可以快速探索、验证和测试各种 PNN 架构,有助于在进行实际的物理建构之前提高 PNN 的准确性和功能性。
这种方法不仅速度更快,成本效益更高,无需为每次设计迭代建立和优化昂贵而耗时的物理系统,还具有可扩展性,并确保了可重复性和透明度。
然而,计算模拟方法也有自身的局限性,比如数字前向模型无法涵盖实际 PNN 硬件中的所有物理现象(噪声、偏移、制造和材料缺陷等),而且连续物理世界的离散化过程需要更精细的网格来提高精度,这可能会导致计算需求的指数级增长。
此外,该方法的效率上限受到计算机性能的限制,而且考虑到建模 PNN 硬件的额外计算开销,通常会比训练常规的数字神经网络更低效。
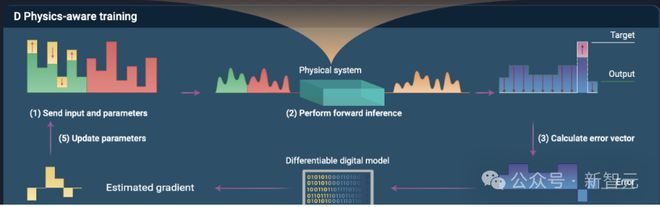
物理感知反向传播训练(Physics-aware BP Training,BPT)
物理感知训练是现场(in-situ)方法和计算模拟方法的混合体:物理系统执行前向计算,后向传播则通过数字模型的微分来执行。
由于其现场方法的成分,PAT 可缓解实验与数字模型之间不匹配的影响,同时,其中模拟方法的本质又能实现精确的训练。
反馈对齐(Feedback Alignment,FA)
反馈对齐(FA)和直接反馈对齐(DFA)方法可以在不将权重从前向计算转移到后向计算的情况下训练 NN,从而提高效率,但通常会牺牲性能。
物理局部学习
局部学习在硬件方面具有巨大的扩展潜力,但这一方法是否能够复现反向传播的性能,目前还很不清楚。
虽然完全匹配反向传播并不是必要的(尤其是考虑到从根本上提高效率的潜力),但在未来,这种有保证的高维扩展是物理局部学习技术的基本要求。
零阶梯度和无梯度训练
为了消除对物理系统详细知识的需求,人们提出了无模型、「黑盒」或无梯度训练算法。
然而,这些算法在硬件上的完整实现仍然很少,而且速度通常很慢,因为梯度更新的次数与网络中可学习参数的数量成线性比例,这给扩展带来了巨大挑战。
通过物理动力学进行梯度下降训练
梯度下降优化是最先进的机器学习系统的主力,与基于 GPU 的神经网络训练相比,这类方法有可能带来 4 个数量级的能量增益。
持续学习
持续学习的目的是使神经网络能够逐步从非稳态数据流中学习。
这有助于解决一个重要问题:当在新的数据集上进行训练时,神经网络往往会因为重写权重而失去之前学习的能力,即「灾难性遗忘」现象。
实现对大型模型的高效模拟
研究人员发现,如果 PNN 硬件设计得当,其不同的底层物理特性可能会使其表现出与数字电子系统不同的能量缩放行为。
这意味着,在模型规模足够大的情况下,PNN 可能实现比数字系统更高的效率。尽管模拟硬件有许多间接成本,例如数模转换成本。
PNN 的光学点积能量缩放优势可能转化为与人工智能模型推理类似的缩放优势,因为大多数模型主要由点积组成。
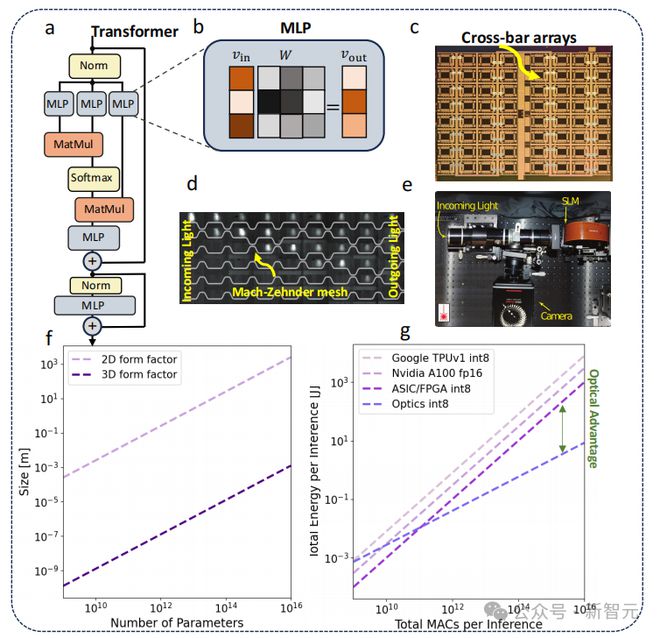
模拟大型模型
PNN 的多样性和使用案例表明,该领域的主要挑战不是找到单一的最佳训练方法。而是针对不同情况找寻出最佳的训练方法。
新兴前沿的 PNN 技术
在论文的最后,研究人员介绍了 PNN 技术的多个应用方向,凸显了这支「潜力股」的发展前景。
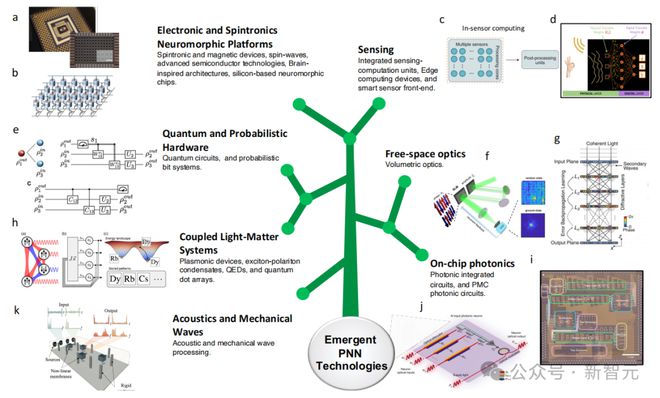
新兴的 PNN 技术
在 PNN 方面,量子计算、概率计算、光子计算、光物质计算和混合计算都是大有可为的发展方向。
量子计算机可以利用量子力学的特点,比如可以利用量子力学的叠加等特征,从而解决对 PNN 训练至关重要的优化问题。
然而,由于当前量子系统的量子比特有限、计算错误率大,这些量子优势的实用性受到了限制。
目前正在设计特定的量子算法和量子神经网络框架,以便在这些限制条件下运行。
例如,利用软量子神经元、量子电路、量子生成对抗网络和变异量子算法,在生成新样本和学习数据分布方面有可能超越经典模型。
概率比特
数字电子设备都是使用经典比特存储,这种技术较为完善。
量子计算通常使用量子比特存储,问题就在于,物理实现量子比特的存储仍然在技术上困难重重。
于是,研究人员就引入了概率比特(p-bits),它是经典比特和和量子比特的一个中间过渡。
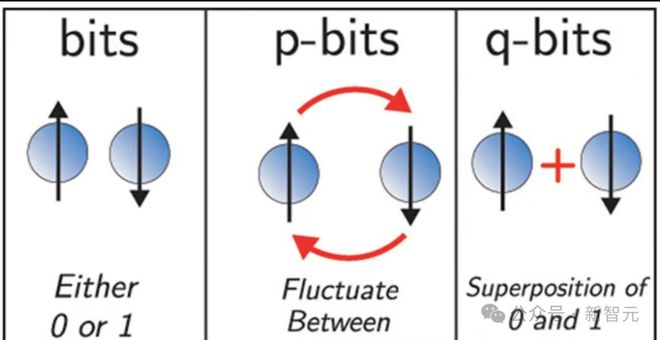
概率比特又被称为「穷人的量子比特」,因为它们可以使用现有的电子设备进行存储和处理,并且可以模拟量子比特的某些属性。
除了量子计算之外,概率比特还可以应用于机器学习中,概率计算机可能有助于机器学习技术开发。
人工智能和机器学习的一个关键步骤是根据不完整的数据预测决策,最好的方法是输出每个可能答案的概率。
目前的经典计算机无法以节能的方式做到这一点,而概率计算机的出现有望填补这一空缺。
概率比特类似于机器学习中所使用的二进制随机神经元,这可令其成为有效的硬件加速器。
因此,它就适合训练深度生成模型和随机神经网络,特别是深度玻尔兹曼机(DBM),为 PNN 的训练带来了另一个机会。
光学神经网络
机器学习技术不断发展,除计算机领域外,在生命科学、医学、材料科学、量子物理、音乐等领域都展现了其独特的优势。
通常意义上的机器学习是一种纯数字化的神经网络模型,往往基于计算机等数字平台实现。
随着越来越多的机器学习算法的开发,大规模机器学习应用对计算机算力和能耗提出了新的挑战。
针对上述问题,搭建基于物理系统的模拟计算平台被认为是一种极具潜力的解决方案。
研究人员利用物理系统固有的声、光、电信号等转换性质,对物理单元进行设计和组合来构建 PNN,从而实现与传统的纯数字化神经网络相似的计算效果。
经过训练的 PNN 可以基于物理系统的自响应进行信号处理,与电子芯片相比能耗更低、速度更快。
与电子系统相比,光的特性,如光学中可实现的空间并行性和光传播中可实现计算的无耗散动态,具有显著优势,利用这种优势,可以为 PNN 带来新的方法。
康奈尔大学的研究人员打破了上述训练模式,提出一种物理感知训练方法(PAT)对基于可调物理系统的物理神经网络进行训练。
在该训练模式下,采用扬声器、光学晶体和电路元件分别构建了声学、光学和电学版的 PNN。
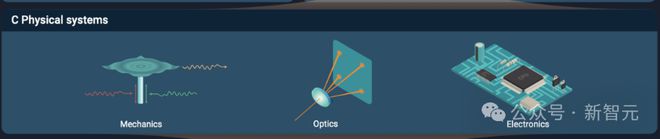
经过训练的 PNN 可以高效地执行元音分类、手写字体识别等常见的机器学习任务。
PAT 训练过程中将基于物理系统的前向计算和基于仿真数字模型的反向传播相结合,显著降低了由于参数移植带来的性能损失。
网络中全光子路由器的编程与 PNN 的训练也有很大的相似之处,这两个领域可以相互助益。
无论具体实现如何,可编程全光子路由器都是(通常是线性的)输入输出系统,具有大量可调整的自由度。
后者必须在运行时重新配置,以实现不同的路由功能(即实现不同的输入-输出关系)。
除了各种成熟的全局优化技术外,纯粹基于局部反馈回路逐步配置特定硬件架构的想法也在不断涌现。
将这些先进的计算范式集成到 PNN 中需要解决几个难题,包括调整学习算法以利用量子和光子,管理量子系统中的噪声和错误率,以及架构的可扩展性。
开发将量子或光子处理单元与经典计算元素相结合的混合系统,可能会为利用这些技术的优势提供实用的途径。
将这些物理系统的独特属性与 PNN 的目标结合起来,可以为下一代智能系统铺平道路。
这些智能系统将拥有前所未有的速度、极高的效率和良好的可扩展性,训练出大 1000 倍的模型也就不是梦了。
参考资料:






