
新智元报道
编辑:桃子
马斯克官宣 xAI 建造的世界最大超算集群,由 10 万块 H100 搭建,预计本月末开始投入训练。另一边,OpenAI 再次加码,将打造由 10 万块 GB200 组成的超算,完全碾压 xAI。
为了抵达 AGI,全世界的公司们准备要烧掉所有的 GPU!
Information 独家报道称,OpenAI 的下一个超算集群,将由 10 万块 GB200 组成。
这可用上了英伟达迄今为止最强的 AI 芯片。

另一边,xAI 也在打造号称「世界上最大超算集群」,由 100k H100 组成,并将在本月末投入训练。
在马斯克最新帖子中,针对报道——xAI 与甲骨文终止服务器交易谈判,立即做出了回应。

他表示,xAI 已经向甲骨文购买了 24000 块 H100,并在这些芯片上训练的 Grok 2。
Grok 2 目前正在进行微调、错误修复,预计下个月准备就绪发布。 与此同时,xAI 也在自行建设 10 万块 H100 搭建的集群,目标是实现最快的训练完成时间,计划本月晚些时候开始训模型。 这将成为世界上最强的训练集群,优势不言而喻。 我们决定自行建设 10 万块 H100 芯片系统,以及下一代主要系统的原因是,我们的核心竞争力取决于能否比其他 AI 公司更快。这是赶上竞争对手的唯一途径。 甲骨文是一家优秀的公司,还有另一家公司(暗指微软)在参与 OpenAI 的 GB200 集群项目中也表现出很大潜力。但是,当我们的命运取决于成为速度最快的公司时,我们必须亲自掌控,而不能只做一个旁观者。

简言之,在这个日新月异的时代下,想要超越竞争对手,必须确保有绝对的速度优势。
xAI 甲骨文谈崩,百亿美元打水漂
今年 5 月,Information 曾报道,xAI 一直在讨论一项多年协议,即从甲骨文租用英伟达 AI 芯片。
这笔交易预计高达 100 亿美元,却因一些问题陷入僵局。
其中就包括,马斯克要求超算建造的速度,完全超越了甲骨文勺想象。还有甲骨文勺担心 xAI 首选地点没有足够的电力供应。

为了改变这一现状,只能依靠自力更生了。
现在,xAI 在田纳西州孟菲斯市,正建起自己的 AI 数据中心,其中用到了 Dell 和 Supermicro 出货的英伟达芯片。
根据参与谈判的人士透露,甲骨文并没有参与这个项目。
其实,在此之前,xAI 已经从甲骨文租用了许多英伟达芯片,成为这家云计算 GPU 供应商最大的客户之一。
尽管更广泛的谈判失败,但这项协议目前仍将继续。
从马斯克最新回应中,可以看出,甲骨文芯片数量已经从 5 月份的 16000 块增长到了 24000 块。
10 万块 H100 串联
不过,马斯克依旧希望建造一台配备 10 万块英伟达 GPU 的超级计算机,将其称为「Gigafactory of Compute」。

他表示,xAI 需要更多的芯片,来训练下一代 AI 模型——Grok 3.0。
老马在 5 月曾向投资者表示,希望在 2025 年秋季之前让这台超级计算机运行起来,而且他将个人负责按时交付超级计算机,因为这对于开发 LLM 至关重要。
他多次公开称,10 万个 H100 组成的液冷训练集群,将在几个月后上线。
之所以 Grok 模型迭代至关重要,因其为X社交应用订阅套餐的一部分,起价为每月 8 美元,包含了各种功能。
就在上周,xAI 还发布了马斯克和其他员工,在数据中心合照。照片后背景中,摆满了服务器。
虽然帖子中,并没有指明位置。但在 6 月的时候,Greater Memphis Chamber 的主席表示,xAI 正在孟菲斯的伊莱克斯工厂建造一台超算。
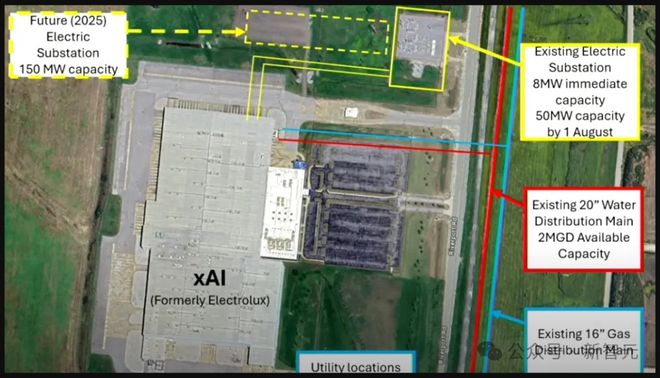
位于田纳西州孟菲斯的新 xAI 工厂的公用设施布局
戴尔公司 CEO Micael Dell 表示,戴尔正帮助 xAI 建立一个数据中心。

另外,Supermicro 的 CEO Charles Liang 还曾发布了一张自己与马斯克在数据中心的合影,也证实这家公司和 xAI 的合作关系。

值得一提的是,上个月马斯克宣布 xAI 已经完成,惊人的 60 亿美元B轮融资,公司估值达到 240 亿美元。
B 轮融资的投资者包括 Andreessen Horowitz、红杉资本、Valor Equity Partners、Vy Capital 和 Fidelity Management&Research 等 8 位投资者。
他个人表示,最新一轮融资中,大部分资金将投入到算力建设之中。

显然,xAI 建设的超算项目,是其追赶 OpenAI 努力的一部分。
10 万块 GB200 超算,两年租用 50 亿美金
其实,另一边,OpenAI 也在马不停蹄地加速研发速度,不敢有一丝懈怠。
两位知情人士透露,甲骨文与微软的交易,涉及一个由 10 万块英伟达即将推出的 GB200 芯片组成的集群。
等这一超算建成之时,马斯克 10 万块 H100 也就不算什么了。

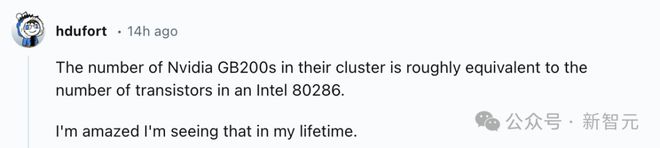
有网友对此惊叹道,集群中英伟达 GB200 芯片数量,大致相当于英特尔 80286 处理器中的晶体管数量我很惊讶在我的有生之年能看到这一幕。
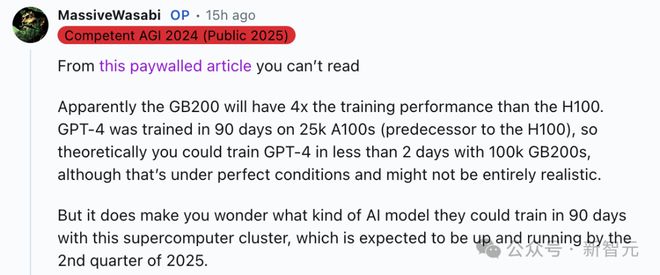
还有人对此分析道,「GB200 的训练性能将是 H100 的 4 倍」。
GPT-4 是在 90 天内用 25,000 个 A100(H100 的前代产品)训练出来的。 所以理论上你可以用 100,000 个 GB200 在不到 2 天内训练出 GPT-4,尽管这是在理想条件下,可能并不完全现实。 但这确实让人不禁想象,他们用这个超级计算机集群在 90 天内能训练出什么样的 AI 模型,而这个集群预计将在 2025 年第二季度投入运行。
在 GTC 2024 大会上,老黄曾介绍道,H100 比 A100 要快 4 倍,B200 比 H100 快 3 倍。

据熟悉 GPU 云定价的人士称,假设两家公司签署了一份多年期协议,那么租用这样一个集群的成本可能会在两年内达到 50 亿美元左右。
这一集群,预计在 2025 年第二季度准备就绪。
甲骨文将从英伟达购买芯片,然后租给微软,微软再把芯片提供给 OpenAI。毕竟,这已经成为微软和 OpenAI 互利互惠一贯的做法了。
微软向 OpenAI 投钱,作为回报,获得 OpenAI 新模型的访问权。

根据参与规划的人士称,甲骨文计划将这些芯片放在德克萨斯州阿比林的一个数据中心。
这笔交易同时表明,微软自己还无法获得足够的英伟达芯片。
而且,云计算供应商之间相互租用服务器的情况,其实并不常见,但对英伟达芯片的强烈需求,才导致了这场不寻常的交易。
去年,微软曾与 CoreWeave 达成了类似的租用服务器协议,以增加英伟达服务器的容量。
参考资料:






