
新智元报道
编辑:编辑部
最近,7B 小模型又成为了 AI 巨头们竞相追赶的潮流。继谷歌的 Gemma2 7B 后,Mistral 今天又发布了两个 7B 模型,分别是针对 STEM 学科的 Mathstral,以及使用 Mamaba 架构的代码模型 Codestral Mamba。
Mistral 又惊喜上新了!
就在今天,Mistral 发布了两款小模型:Mathstral 7B 和 Codestral Mamba 7B。
首先是专为数学推理和科学发现设计的 Mathstral 7B。
在 MATH 基准测试中,它获得了 56.6% pass@1 的成绩,比 Minerva 540B 提高了 20% 以上。Mathstral 在 MATH 上的得分为 68.4%,使用奖励模型得分为 74.6%。
而代码模型 Codestral Mamba,是首批采用 Mamba 2 架构的开源模型之一。
它是可用的 7B 代码模型中最佳的,使用 256k token 的上下文长度进行训练。

两款模型均在 Apache 2.0 许可证下发布,目前权重都已上传 HuggingFace 仓库。

Hugging Face 地址:https://huggingface.co/mistralai
Mathstral
有趣的是,根据官宣文章,Mathstral 的发布恰好庆祝了阿基米德 2311 周年诞辰。
Mathstral 专为 STEM 学科设计,以解决需要复杂、多步骤推理的高级数学问题。参数仅有 7B,上下文窗口为 32k。
而且,Mathstral 的研发还有一个重量级的合作伙伴——上周刚刚在 Kaggle 第一届 AI 奥数竞赛中得到冠军宝座的 Numina。

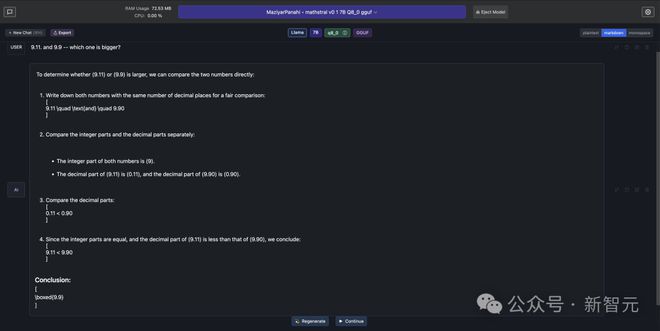
而且,有推特网友发现,Mathstral 可以正确回答「9.·11 和 9.9 哪个更大」这个难倒一众大模型的问题。
整数、小数分开比较,思维链清清楚楚,可以说是数学模型优秀作业的典范了。
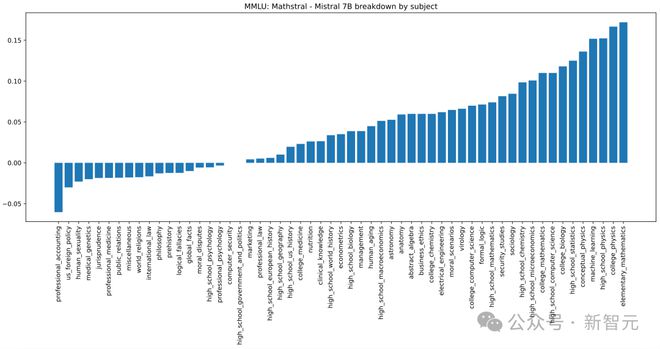
基于 Mistral 7B 的语言能力,Mathstral 进一步聚焦 STEM 学科。根据 MMLU 的学科分解结果,数学、物理、生物、化学、统计学、计算机科学等领域都是 Mathstral 的绝对优势项目。
根据官方博客文章的透露,Mathstral 似乎牺牲了一些推理速度以换取模型性能,但从测评结果来看,这种权衡是值得的。
在多个数学、推理领域的基准测试中,Mathstral 打败了 Llama 3 8B、Gemma2 9B 等流行的小模型,特别是在 AMC 2023、AIME 2024 这类数学竞赛题上达到了 SOTA。
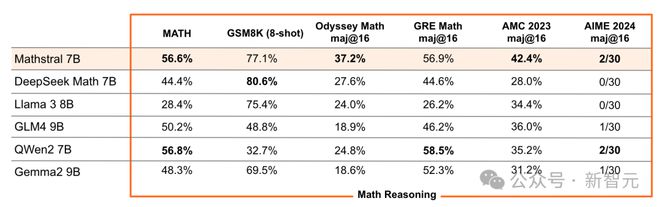
而且,还可以进一步增加推理时间以取得更好的模型效果。
如果对 64 个候选使用多数投票(majority voting),Mathstral 在 MATH 上的分数可以达到 68.37%,进一步添加额外的奖励模型,还能取得 74.59% 的高分。
除了 HuggingFace 和 la Plateforme 平台,还可以调用官方发布的 Mistral-finetune 和 Mistral Inference 两个开源 SDK,使用或微调模型。
Codestral Mamba
继沿用 Transformer 架构的 Mixtral 系列发布后,第一个采用 Mamba2 架构的代码生成模型 Codestral Mamba 也问世了。
而且,研发过程也得到了 Mamba 原作者 Albert Gu 和 Tri Dao 的协助。
有趣的是,官宣文章专门 cue 到了和有关的「埃及艳后」Cleopatra 七世,她就是戏剧般地用一条毒蛇终结了自己的生命。
Mamba 架构发布后,其优越的实验性能得到了广泛的关注和看好,但由于整个 AI 社区在 Transformer 上投入了太多成本,我们至今也很少看到实际采用 Mamba 的工业界模型。
此时,Codestral Mamba 恰好能为我们提供研究新架构的全新视角。
Mamba 架构首发于 2023 年 12 月,两位作者又在今年 5 月推出了更新版的 Mamba-2。
与 Transformer 不同,Mamba 模型具有线性时间推理的优势,并且理论上能够建模无限长度的序列。
同为 7B 模型,Mathstral 的上下文窗口只有 32k 时,Codestral Mamba 却能扩展到 256k。
这种推理时间和上下文长度方面的效率优势,以及实现快速响应的潜力,在用于提升编码效率的实际场景中尤为重要。
Mistral 团队正是看到了 Mamba 模型的这种优势,因而率先尝试。从基准测试来看,7B 参数的 Codestral Mamba 不仅比其他 7B 模型有明显优势,甚至可以和更大规模的模型掰掰手腕。
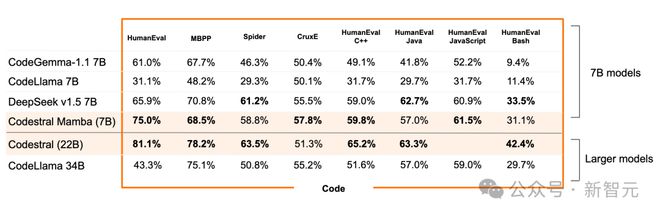
在 8 个基准测试中,Codestral Mamba 基本达到了和 Code Llama 34B 相匹配的效果,甚至在其中 6 个测试上实现了性能超越。
然而相比大姐姐 Codestral 22B,Codestral Mamba 的参数量劣势就体现出来了,依旧显得能力不足。
值得一提的是,Codestral 22B 还是不到两个月前发布的新模型,再次感叹一下总部在巴黎的 Mistral 竟如此之卷。
Codestral Mamba 同样可以使用 Mistral-inference 部署,或者英伟达发布的快速部署 API TensorRL-LLM。
GitHub 地址:https://github.com/NVIDIA/TensorRT-LLM
对于本地运行,官方博客表示,可以留意后续 llama.cpp 的支持。但 ollama 行动迅速,已经将 Mathstral 加入到了模型库中。
面对网友催更 codestral mamba,ollama 也非常给力地表示:「已经在弄了,稍安勿躁。」
参考资料:
https://mistral.ai/news/codestral-mamba/
https://mistral.ai/news/mathstral/
https://venturebeat.com/ai/mistral-releases-codestral-mamba-for-faster-longer-code-generation/






