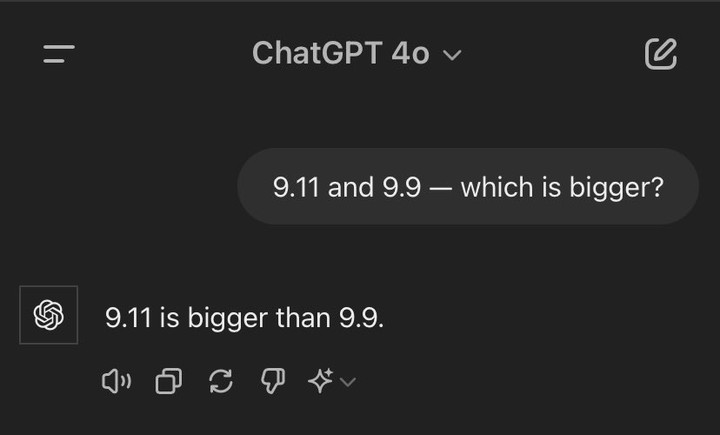
近日,有媒体记者测试了 12 个国内外主流大模型,其中 ChatGPT-4o、字节豆包、月之暗面 kimi、智谱清言、零一万物万知、阶跃星辰跃问、百川智能百小应、商汤商量等模型均在测试中回答:9.11 大于 9.9,相关话题登上微博热搜。
对于上述现象,月之暗面回应新浪科技称,目前对大模型的能力探索还处在非常早期的阶段,像是「9.9 和 9.11 哪个大」和「strawberry 有几个 r」这些边界案例的发现都有助于增加开发者对大模型能力边界的了解。
月之暗面也表示,要解决问题,需要不断增强底层基础模型的智能水平,让大模型变得更加强大和全面,能够在各种复杂和极端情况下依然表现出色。
也有相关人士表示,大模型可能学习到的都是「版本号」、「章节」、「日期」等场景,这些场景下 9.11 确实大于 9.9,大模型回答错误可能是没有跟人类的需求对齐。






