蚂蚁集团发布了开源项目 EchoMimic。据介绍,EchoMimic 不仅能根据人像面部特征和音频来帮人物对口型,还可以结合面部标志点和音频内容生成较为稳定、自然的视频。
GitHub:https://github.com/BadToBest/EchoMimic
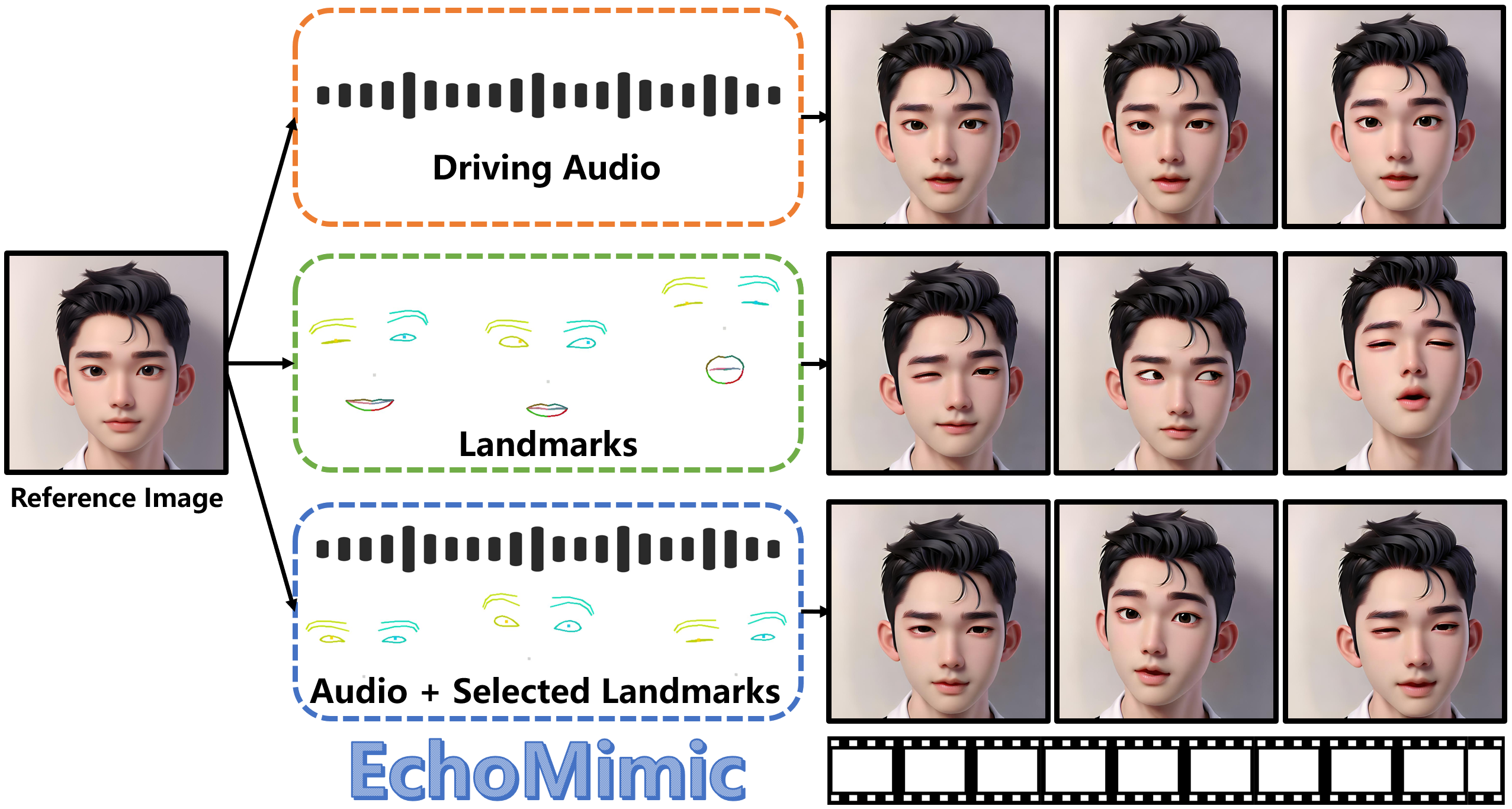
EchoMimic 具备较高的稳定性和自然度,通过融合音频和面部标志点(面部关键特征和结构,通常位于眼、鼻、嘴等位置)的特征,可生成更符合真实面部运动和表情变化的视频。
其支持单独使用音频或面部标志点生成肖像视频,也支持将音频和人像照片相结合做出 “对口型” 一般的效果。
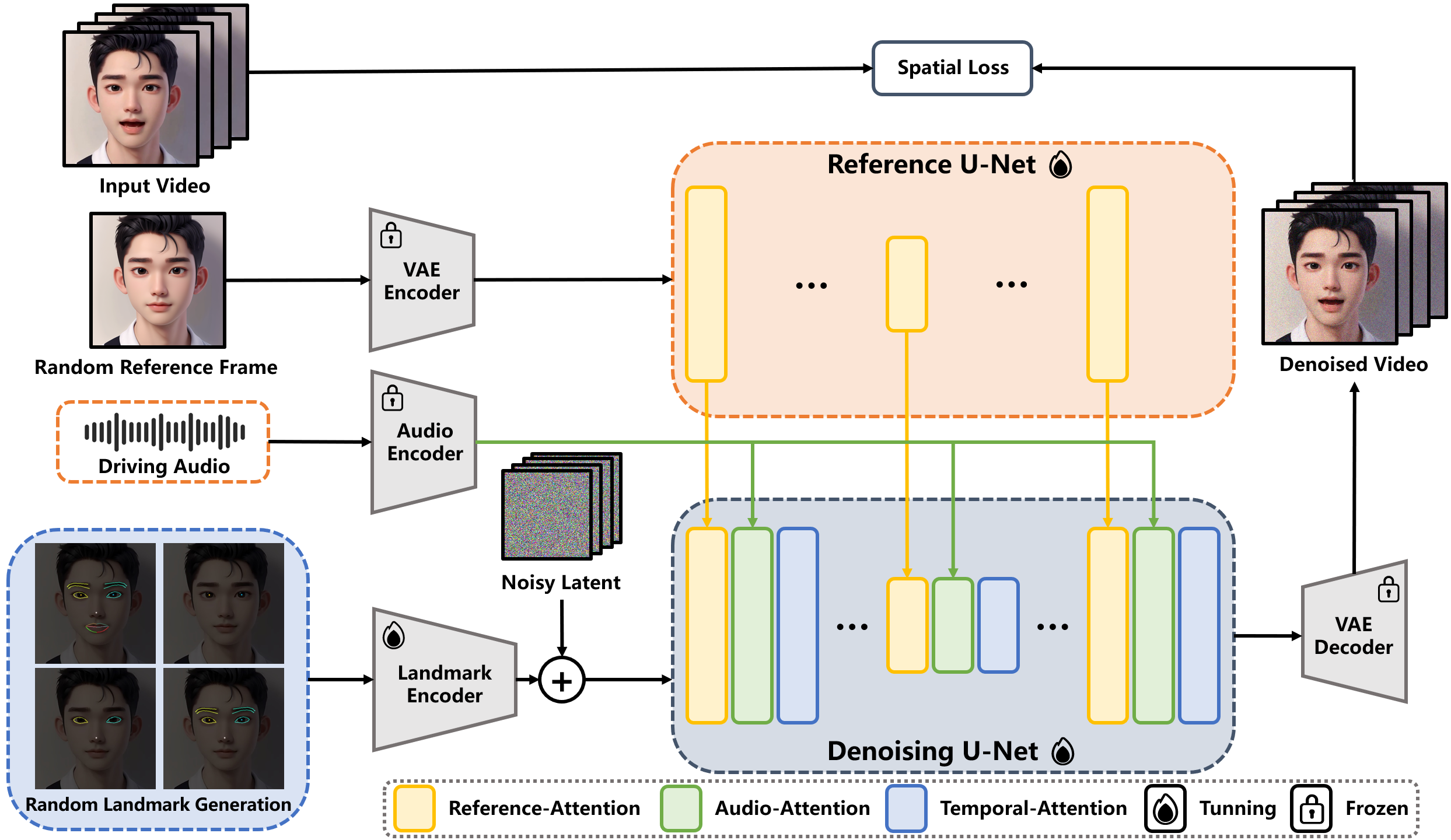
下图是 EchoMimic 的工作原理:
EchoMimic 支持多语言(包含中文普通话、英语)及多风格,也可应对唱歌等场景。
访问主页查看更多示例:https://badtobest.github.io/echomimic.html







