
AI 考生语数外三科加起来最高能得 303 分
此前 6 月,上海人工智能实验室旗下司南评测体系 OpenCompass 发布了首个 AI 高考全卷评测结果,显示语数外三科加起来,AI 考生最高能得 303 分,数学全不及格。
7 月 17 日,OpenCompass 进一步发布了扩大学科范围的测评,团队对 7 个 AI 大模型进行了高考 9 个科目的全科目测试,这样一来也就能与高考录取分数线作比较。
如果 AI 参加高考,能被什么大学录取?OpenCompass 测试发现,大模型如果参加文科考试,最好的成绩能被“录取”到一本,而参加理科考试,则最多只能被二本“录取”(以今年高考人数最多的河南省的分数线为参考)。
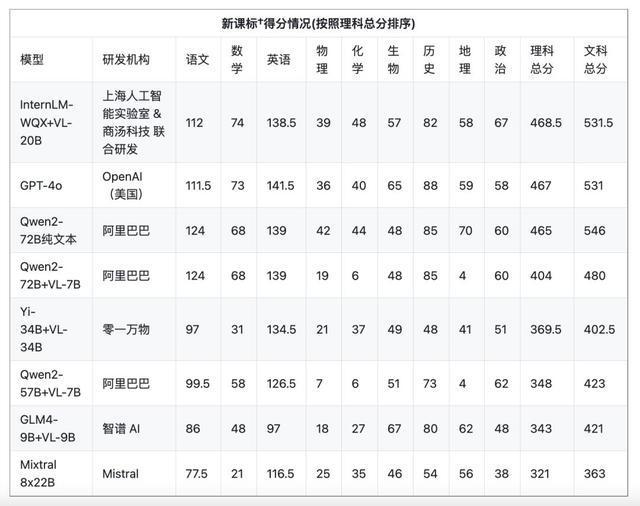
AI 大模型高考 9 个科目的全科目测试得分
此次测试的模型仍然来自阿里巴巴、零一万物、智谱 AI、上海人工智能实验室&商汤、法国 Mistral 的开源模型,以及来自 OpenAI 的闭源模型 GPT-4o。
从总分来看,文科最高分是阿里通义千问大模型,以 546 分的成绩获得 AI 高考“文科状元”。理科最高分则是上海人工智能实验室&商汤联合研发的浦语文曲星,达到了 468.5 分。OpenAI 的 GPT-4o 在文科上得分 531,排名第三,理科得分为 467,排名第二。
就评测结果的公正透明方面,相关人士介绍,大模型高考评测的生成答案的代码、模型答卷、评分结果完全公开,可供各界参考(公开评测细节可访问 https://github.com/open-compass/GAOKAO-Eval)。
评测团队选取了河南省录取批次线作为参考,对比了大模型得分与对应分数线。总的来说,参考 2024 年河南本科批次录取线,表现最优的三个大模型文科成绩过一本,理科超二本。其他大模型文理科成绩均未达到二本线标准。
如果 AI 参加的是文科考试,那么通义千问、书生浦语文曲星、GPT-4o 的文科成绩均超越一本线,展现了大模型在语文、历史、地理、思想政治等科目上深厚的知识储备和理解能力。
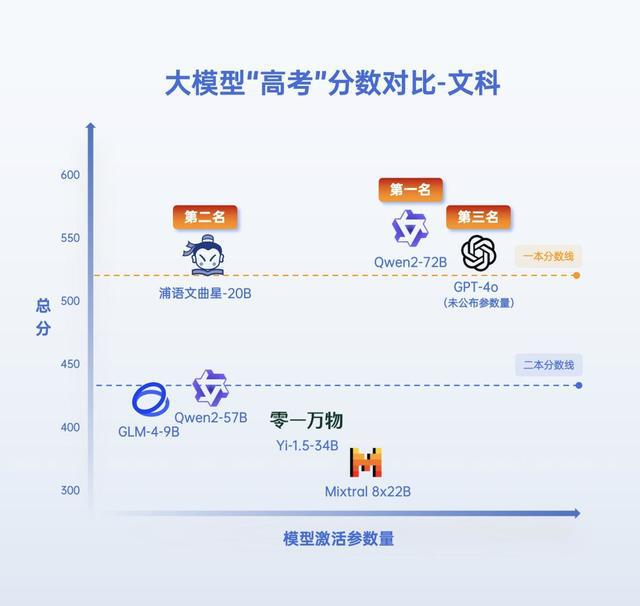
大模型“高考”分数对比-文科
如果 AI 参加的是理科考试,整体表现则会弱于文科,体现了大模型在数理推理能力上普遍存在短板,但前三甲的理科成绩也均超过二本分数线,“录取”上二本不成问题。
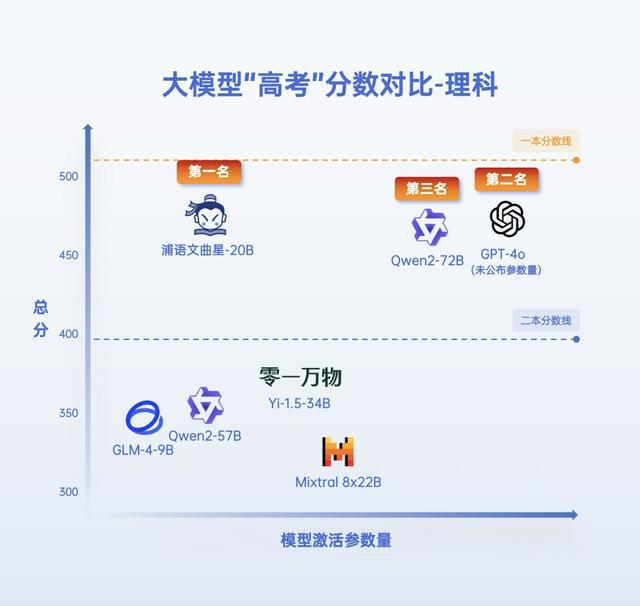
大模型“高考”分数对比-理科
团队表示,为更贴近真实高考情况,评测采用3(语数外)+3(理综/文综)的形式对大模型进行了全科目测试。评测过程中,所有纯文本题目由大语言模型作答,而综合科目中的带图题目,则由对应团队开源的多模态大模型回答。
测评发现,对于纯文本题目,大模型平均得分率可达 64.32%,而面对带图题目,得分率仅有 37.64%。在图片理解和运用能力方面,所有大模型均存在较大提升空间。
此外,部分大模型已达到一本分数,经过再训练,是否可达到顶尖高校录取线水平?完成阅卷后,老师们一致认为,大模型与真人考生仍存在差距,虽然对于基础知识的掌握表现出色,但在逻辑推理和知识灵活应用方面,大模型仍然差强人意。
具体而言,在作答主观题时,大模型往往无法完整理解题干,不明白代词指向,结果导致答非所问;解答数学题时,解题过程机械且逻辑性差,对于几何题,常出现与空间逻辑相违背的推断;对物理、化学实验理解肤浅,无法准确识别并运用实验器材。此外,大模型也会伪造虚构内容,编造看似合理但实际不存在的诗句,或在存在明显计算错误的情况下之后不反思,“硬着头皮蒙”一个答案,均给阅卷老师带来了困扰。
在公开评测细节中,第一财经记者发现收录了一些阅卷老师的点评。
理科数学老师点评称,大模型做题总体感觉很机械,大部分题目都无法通过正常的推理过程得出。例如填空题第一题,大模型都只能进行到少部分过程而达到一个结果,并不能够像考生做题一样进行全面分析,列出完整的计算过程达到正确结果。大模型的基础公式记忆能力较为优秀,但无法做到灵活使用。此外有些题目结果正确,但过程逻辑差不符合正规计算,导致阅卷比较困难。
地理老师认为,大模型在答题过程中展现了对地理知识的全面覆盖,从自然地理到人文地理,从地理现象到地理规律,都能有所涉及。尤其在基础知识点的考查上较为出色,然而,在涉及一些深入分析或推理的问题中,存在一定的偏差和遗漏,所以模型在面对非常规、开放性较强的问题时,其表现较差。
物理老师发现,大模型总体感觉比较机械,很多都无法识别到题目的意思,有些选择题即使选项对了,但是分析也是错误的。一些大题步骤冗杂,并且没有逻辑,常常出现将本次的结论带入到推理出本次结论的证据中,如此循环,没有道理。
阅卷老师们认为,相对于人类考生,目前大模型依然存在较大局限性。
栏目主编:张武文字编辑:董思韵题图来源:图虫图片编辑:徐佳敏
来源:作者:第一财经






