
新智元报道
编辑:LRST 好困
大模型在语言、图像领域取得了巨大成功,时间序列作为多个行业的重要数据类型,时序领域的大模型构建尚处于起步阶段。近期,清华大学的研究团队基于 Transformer 在大规模时间序列上进行生成式预训练,获得了任务通用的时序分析模型,展现出大模型特有的泛化性与可扩展性
时间序列提供了数据随时间变化的视角,对于理解复杂系统、预测未来变化和制定决策规划至关重要,在金融、气象、医疗、供应链等多个行业中发挥着至关重要的作用。
近年来,基于深度学习开发的模型在时序分析领域取得了突破性进展。然而,相较于语言、视觉大模型的蓬勃发展,现有模型依然面临若干瓶颈:
(1)泛化性:模型能处理训练时未遇到的新数据;或在数据稀缺时,根据有限的训练数据快速适配。然而,即便是目前领域前沿的时序模型,在少样本场景下依然会产生明显的性能劣化。
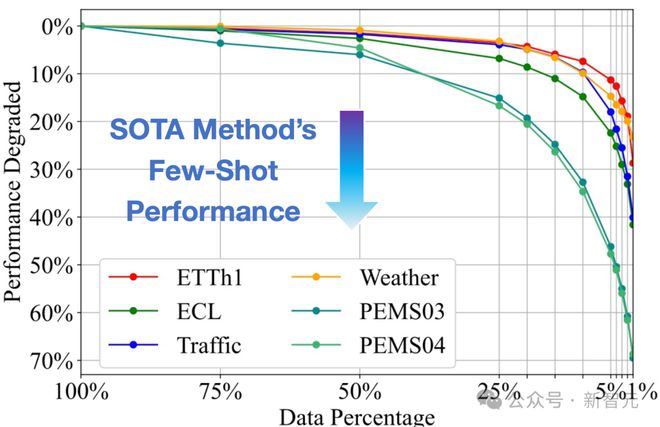
时序预测模型 PatchTST 在不同数据稀缺条件下的效果
(2)通用性:小型深度模型训练后仅适合单一任务和场景,具有固定输入输出长度,适配的变量数等难以泛化的性质,难以像大语言模型一样,适用于各类下游任务,例如 T5,LLaMA 和 BLOOM 等。
(3)可扩展性:大模型关键特征之一在于 Scaling Law:扩大参数量或预训练规模可以取得效果提升。然而,时序领域的大模型骨架尚无定论,即使是 Transformer,在以往时序大模型研究中尚未展现出明显的可扩展性。

最近,清华大学软件学院机器学习实验室和大数据系统软件国家工程研究中心提出了名为 Timer(Time Series Transformer)的面向时间序列的大模型(Large Time Series Model, LTSM)。
模型采用仅编码器(Decoder-only)结构,基于多领域时间序列进行大规模预训练,通过微调突破了少样本场景下的性能瓶颈,适配不同输入输出长度的时间序列,以及预测,填补,异常检测等任务,展现出模型可扩展性。
目前,该工作已被 ICML 2024 接收。

论文链接:https://arxiv.org/abs/2402.02368
代码仓库:https://github.com/thuml/Large-Time-Series-Model
数据构建:基于时序特性构建层次化数据集
尽管时间序列在现实世界中无处不在,大规模时间序列数据集的发展却滞后于语言,图像,视频等领域。
并且,基于低质量,弱语义,以及难预测数据训练的模型无法展现对时间序列的通用理解能力。
为此,作者团队基于可预测性、平稳性等指标重重筛选,文章构建了包含 10 亿数据点的统一时间序列数据集(Unified Time Series Dataset, UTSD)。
UTSD 覆盖七个领域的高质量时间序列,蕴含时间序列模态的通用“常识”,以此训练模型获得跨领域时序建模的基本能力,例如捕捉主要周期,生成重要模式,以及关注自相关部分等。
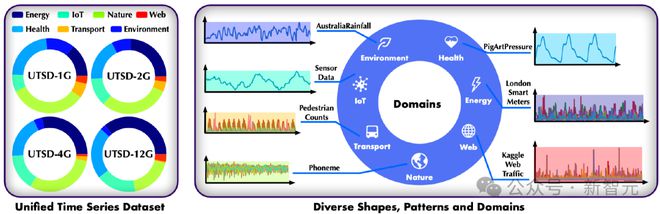
文章尤其重视数据质量的重要性,对数据集进行难度分级和配比,随着数据规模的扩大,变化规律复杂的数据比例也在不断增加,以便逐步进行模型的容量扩展和课程学习。

作者团队目前还在持续扩大数据集,并将 UTSD 公开至 HuggingFace,以促进时序领域的预训练以及大模型研究。
训练方法:统一格式 + 自回归生成
不同于语言、图像有着相对固定的格式,时序领域的数据存在异构性,例如变量数目,采样频率和时间跨度等,因此,进行大规模时序预训练的首要难题在于如何统一异构的时间序列。
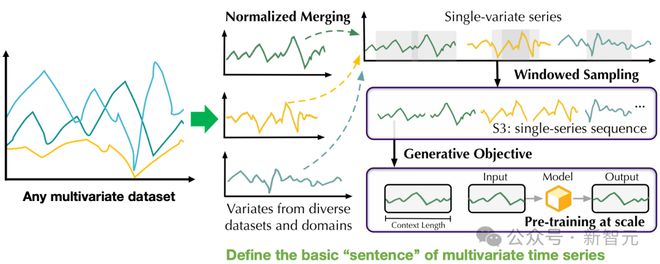
为将异构时间序列转换为统一格式,作者团队提出了一种单序列(Single Series Sequence, S3)格式。
如下图所示,通过变量拆分,归一化合并,分窗和采样等流程,文章将时序数据转换成了与语言类似的固定长度的一维序列,在数值范围内保证分布稳定的同时,让模型更加关注序列本身的变化模式。
在预训练方法上,文章将单序列切分为序列片段,每个片段作为一个“词”,采用与 LLM 类似的下一词预测(Next Token Prediction, NTP)进行预训练。推理时,模型可通过自回归生成任意长度的序列。
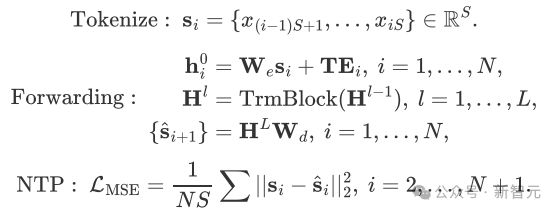
模型结构:剑走偏锋的仅解码器结构
不同于当下时序领域流行的仅编码器结构,Timer 采用 GPT 风格的仅解码器 Transformer。
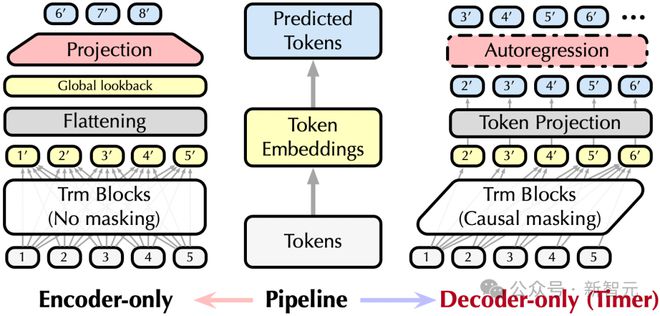
作者团队发现,Encoder-only 结构接受了预测区间的所有监督信号,在端到端的训练场景中能取得较好效果,但在一定程度上限制 Transformer 作为时序大模型的潜力。
一方面,在 Encoder-only Transformer 中,输入序列中的“词”互相可见,可能降低了模型建模序列变化的难度;模型引入的平整化(Flattening)会影响词之间的独立性,导致难以学到序列片段的语义。
另一方面,LLM 广泛采用以词为单位的自回归式监督信号,每个“词”都是预测的目标,产生了细粒度且互相独立的监督信号。
文章认为基于大规模时序数据,学习序列片段的独立语义,能够赋予模型在数据集之间泛化的能力。并且获得的模型和 LLM 一样,模型只限制了最大输入长度,从而能够适用于下游任务中各种长度的序列。
任务统一:生成式模型应对多种任务
Timer 与 GPT 类似进行生成式自回归,为进一步扩展模型的通用性,文章将典型时序分析场景统一为生成式任务。
(1)时序预测(Forecasting):Timer 一次推理输出一个序列片段,通过多步自回归给出任意长的预测结果。作者团队发现,在预测上下文长度不超过预训练序列长度的情况下,模型不会出现明显的多步误差累积现象。
(2)时序填补(Imputation):类似语言模型 T5,作者引入 Mask Token 表示一段连续的缺失序列。通过微调,模型根据 Mask 之前的序列来填补连续的缺失值。
(3)异常检测(Detection):文章提出了一种预测式异常检测方法,模型首先在正常序列上进行微调,随后根据输入给出偏移一段时期的序列作为正常值,将其与实际采集的值对比,基于对比误差给出异常区间的置信度。
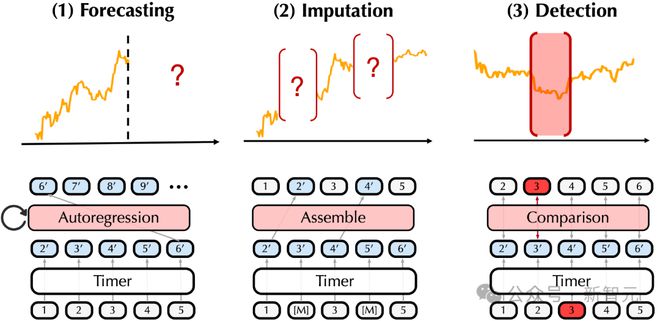
多种时序分析任务与基于 Timer 的生成式分析方案
实验效果
文章从多个角度评估了 Timer 作为时序大模型的能力,包括少样本微调,零样本预测,任务通用性,可扩展性等,并分析了模型骨架选择,以及对于可变序列长度的适配性。
少样本预测
文章测试了 Timer 在不同数据稀缺性下的预测误差(MSE),并与此前的领域最优效果(SOTA)进行了比较。
可以发现:Timer 使用极少的训练样本,例如1% 的 ETTh1 或者3% 的 PEMS03,就能超过领域前沿的 PatchTST,iTransformer 等模型在 100% 数据上的训练效果。
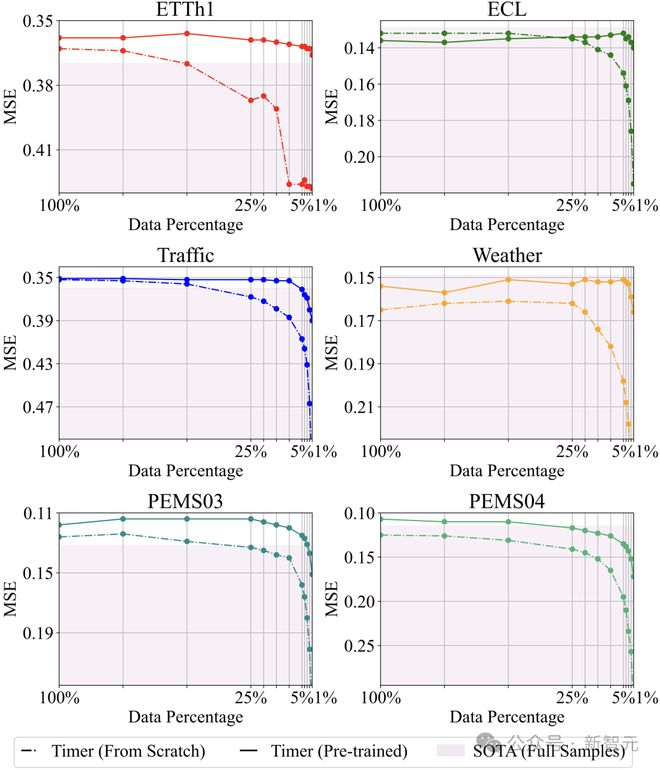
实线:预训练 Timer;虚线:端到端训练的 Timer;深色基准:SOTA 模型在全量数据上的训练效果
另外,预训练 Timer 的预测误差(实线)一致小于未经过预训练的模型(虚线),证明了大规模预训练的有效性。
任务通用性
文章评估了 Timer 在填补任务和异常检测上的效果,验证了预训练能够给模型在各个数据集上带来稳定的收益。
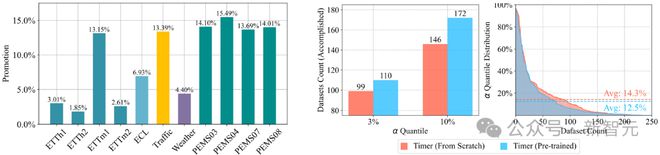
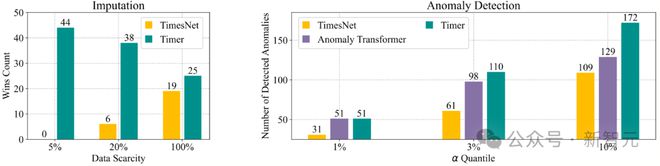
左:填补任务中相对端到端模型的效果提升;右:在 UCR Anomaly Archive 中成功检测出的异常数
文章还将 Timer 与此前的领域专用模型进行了对比:Timer 在全部的 44 个填补场景中取得了领先,并成功检测出了 172 个序列异常,相较之下,Anomaly Transformer 为 129 个,TimesNet 为 109 个。
可扩展性
作者团队研究了 Timer 的可扩展性,发现随着参数量和数据规模的增加,模型在 PEMS 数据集上的多变量预测误差降低了 36.6%(0.194 -> 0.123),低于此前最优的多变量预测模型 iTransformer(0.139)。
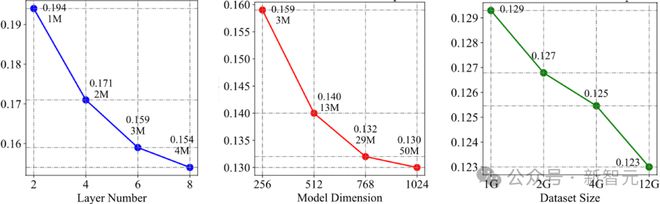
从左到右:扩展 Timer 层数,特征维度和预训练数据规模都能提升预测效果
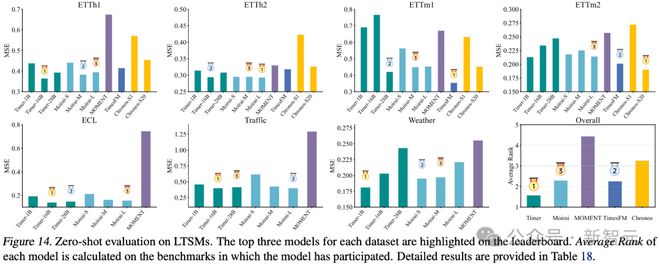
零样本预测
作者团队对同期涌现的时序大模型进行了全面测评,在零样本预测任务中,大模型不更新任何参数,直接输入数据集中时间序列进行预测。在 7 个真实数据集中,Timer 取得了综合最优的水平。
模型分析
为确认时序领域的大模型骨架,作者团队对不同模型进行了同样规模的预训练,包括基于 MLP 的 TiDE、TCN、LSTM 以及 Transformer 的两种结构,结果显示 Transformer 在大规模时序数据预训练中具备足够的模型容量。
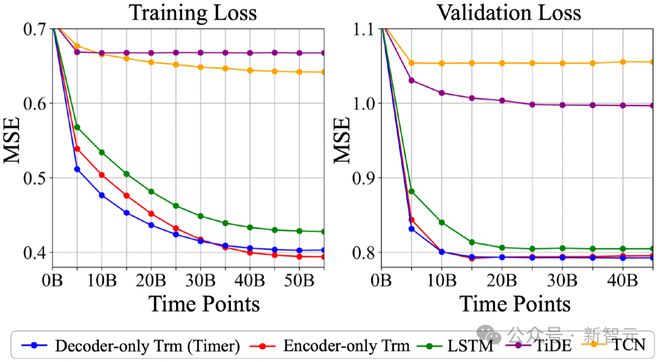
训练/验证时的损失函数,横轴以模型训练过的数据点数代表训练进程
文章探讨了 Timer 对可变序列长度处理能力:如左图所示,随着输入序列的变长,Timer 的预测误差逐步降低。如左图所示,为支持任意长度的序列输出,文章对两种结构的 Transformer 进行了滚动预测。相较于 Encoder-only Transformer,Timer 显著缓解了多步误差累积。
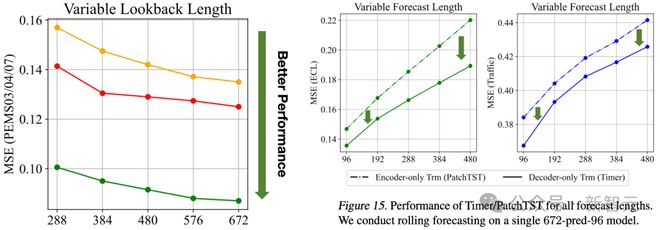
作者进一步分析了两种 Transformer 结构在下游任务上的泛化性,发现时下流行的仅编码器结果在小规模训练场景中可以取得较好的效果。然而,在预训练-微调范式下,Timer 表现出更强的泛化性,即使在多步滚动预测的场景中也能取得领域最优效果,打破了此前针对不同输入-输出长度分别训练的现状。
分析示例
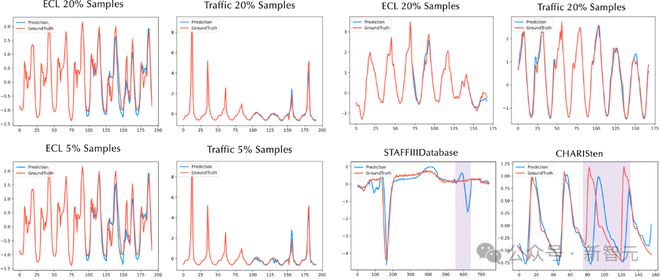
文章提供了 Timer 在各个任务上的分析示例和具体指标,详情可参考论文附录。
未来方向
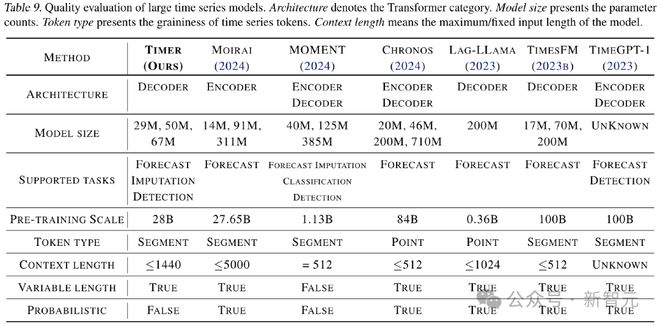
文章最后,作者对现有时序大模型进行了能力测评和对比,总结了时序领域大模型的潜在发展方向,主要包含更强的泛化能力(例如零样本预测),支持更长的上下文长度,支持多变量建模,以及提供置信度的概率预测等。
总结
该工作关注大模型的预训练-微调范式,验证了构建时序领域大模型的可行性,对多领域时间序列的生成式预训练进行了深入探究,证明了生成式模型在处理多种时序分析任务的有效性,相关数据集与代码已经开源,欢迎感兴趣的朋友阅读论文或访问 GitHub 页面。
参考资料:






