梦晨发自凹非寺
量子位公众号 QbitAI
陶哲轩在国际数学奥赛 IMO 上亲自给一支 AI 团队颁奖!
怎么回事?
一同举办的 AI 数学奥林匹克竞赛,让大模型做 IMO 级别的竞赛题。

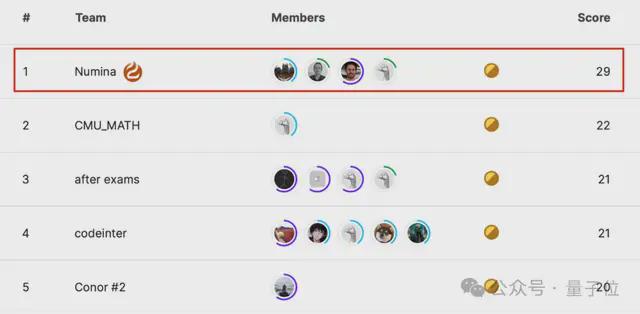
获奖团队Numina,在不公开的 50 道测试题中成功解决了 29 道,与第2-5 名方案明显拉开差距。
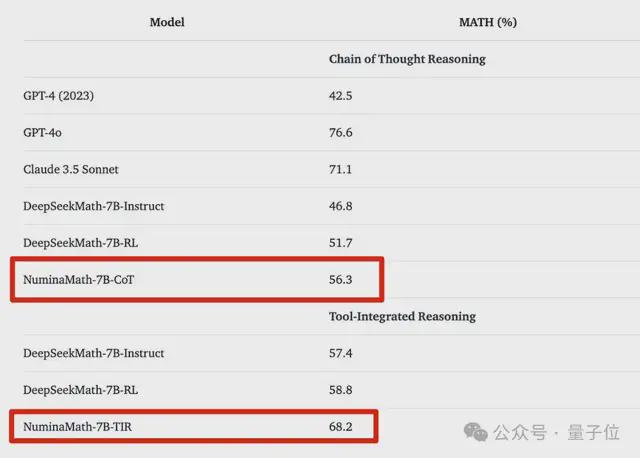
NuminaMath-7B模型,也一举成为数学推理方面最好的 7B 模型之一。
更重要的是,获奖后团队宣布,从模型到数据到代码甚至详细的训练过程,全!都!开!源!
目前模型权重、Demo、数据集已经发布到 HuggingFace,更多内容还在加速整理中。
已有尝鲜的网友惊奇发现,这位“奥赛做题家”模型的一点秘诀:会主动使用 Python 代码验证自己的想法。
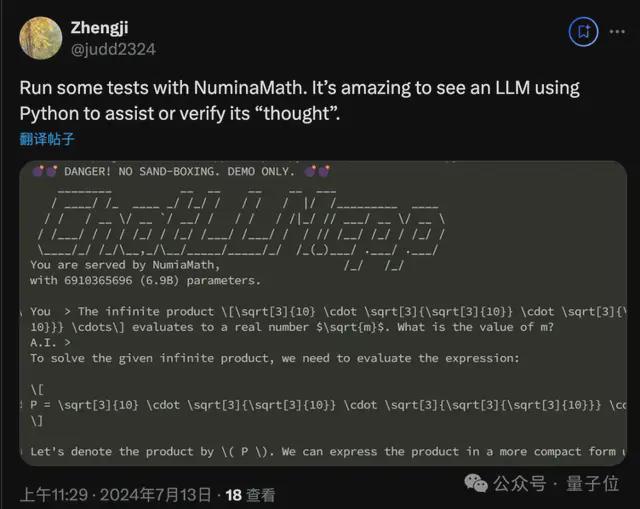
Numina 团队一战成名,但还比较神秘——
并非隶属于某个大学或公司,而是一个独立的非盈利组织,要引领 AI4Math 的开放研究。
他们到底是谁,具体如何让大模型解决数学奥赛难题,我们找到负责人李嘉聊了聊。(因签证问题,李嘉没能去现场领奖)
陶哲轩支持的 AI 数学奥赛
首先来了解一下这个比赛。

AI 数学奥林匹克奖(AIMO),于 2023 年 11 月设立,旨在促进能在 IMO 竞赛中赢得金牌的开放共享 AI 模型诞生。
顾问委员会成员包括菲尔兹奖得主陶哲轩和 Timothy Gowers、以及更多著名数学家、AI 和机器学习专家。

500 万美元大奖(The Grand Prize),将颁发给首个在获批竞赛中达到 IMO 金牌标准的 AI 模型。
除了大奖之外,AIMO 还推出了一系列进步奖,用来纪念朝着这一最终目标的里程碑。
Numina 团队赢得的是首个进步奖(The First Progress Prize),题目难度低于 IMO 决赛,属于 IMO 预选赛水平。

△赛题示例
可能与大家想象中的不一样,这场比赛规则比较特别:
- 算力有限制,只能使用单卡 P100 或双卡 T4 推理;
- 模型有限制,只能使用在比赛开始之前已经公开发布的开放模型;
- 时间有限制,每次提交最多有 9 个小时来解决 50 个问题。
而且除了公共题目以外,同样还有 50 道参赛者看不到的私有题目。
换句话说:靠砸钱、砸算力刷榜是行不通的,靠“押题”去拟合题目也是行不通的,想赢必须实打实的在方法创新上做文章了。
100 万道数学题微调
由于算力和时间的限制,决定了无法使用太大的模型,团队的初步想法是 7B-20B。
经过实验对比后,最终选择了DeepSeekMath-Base 7B作为底座模型。
由经过整个比赛过程中的多次迭代,最终获奖方案由三个主要部分组成:
- 通过微调让基础模型充当 Agent,通过自然语言推理,使用 Python REPL 计算中间结果混合来解决数学问题。
- 一种用于工具集成推理(TIR)的新颖解码算法,具有代码执行反馈,可在推理过程中生成候选解决方案。
- 用来指导模型选择并避免过度拟合公共排行榜的各种内部验证数据集。
李嘉向量子位进一步介绍了训练过程中的细节,主要参考了来自好未来和中国海洋大学的一篇论文MuMath-Code。

- 第一阶段的训练,在一个接近 100 万条 CoT(思维链)的数据集上做微调,微调数据为数学问题和按详细步骤解题的文本答案
- 第二阶段的训练,在一个 10 万条 TORA (Tool Integrated Reasonning Agent)的数据集上做微调,使得模型可以多次输出思维链加上代码来解数学题。
- 最终部署的时候,模型输出代码我们把执行结果返回给模型继续推理直接推理结束。
- 为了加快解题速度,团队提交的是 8bit 量化的模型,用 vllm 做 32 次采样做 majority voting
经过这样一系列步骤,基础模型就成了“数学做题家”,拿来闲聊、多轮对话它是不擅长的,会把一切都当成题来做。
Demo 发布后经网友测试,即使面对像“一千克棉花和一千克铁谁重”这种脑筋急转弯问题,也会严格按照分解步骤、列式子、写代码,最后再分析代码执行结果得出结论。
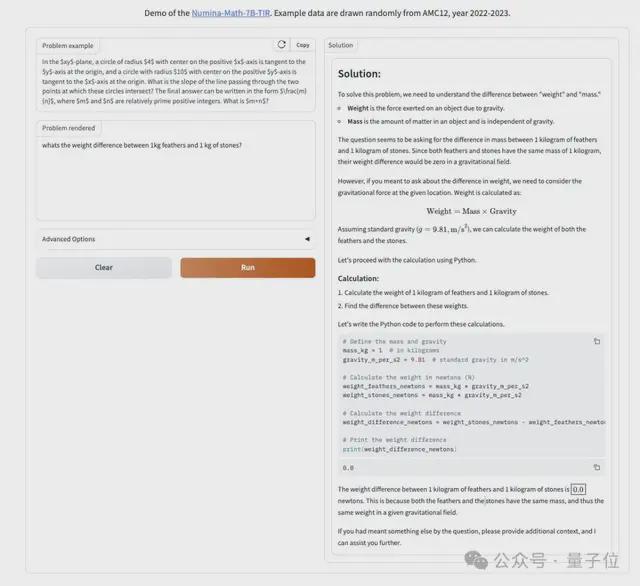
由于赛制上的种种限制,最终方案 NuminaMath-7B 肯定并非最优解,比如由于算力有限,与最近热门Q*相关的搜索方法就派不上用场。
但李嘉认可正是由于这些限制,促使参赛团队去寻找更优化的方法,而不是一味地砸算力。
其中积累下来的成果和经验,都可以继续用于更大规模的研究,这也是整个赛事的初衷和意义所在。
对此,李嘉还透露了一个好消息,团队在竞赛过程中参照 DeepSeekMath 和其他学者的方案,在前人基础上扩大数据集规模,最终得到的是约 86 万道涵盖从高考数学到竞赛数学的题目微调数据集,也已经开源。
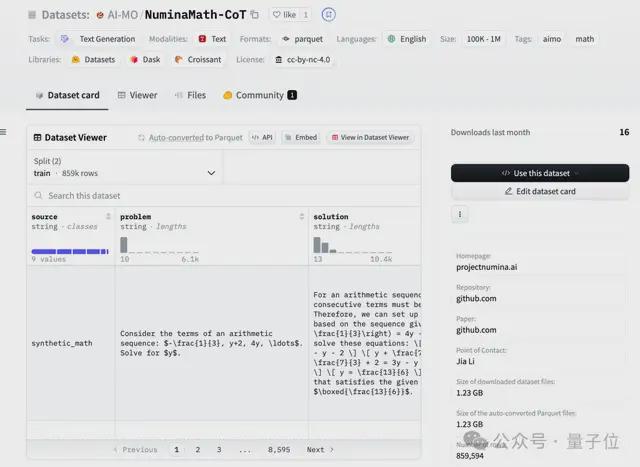
另外,团队还在 HuggingFace 上撰写了介绍获奖方案完整 Blog,包括训练、数据、算法实现上的细节,还介绍了尝试过但最终没有采纳的踩坑经验。
也是非常值得一看了。(地址在文末获取)

要做 AI 数学的 ImageNet
最后再来介绍一下获奖团队 Numina,2023 年底成立的非营利组织。
核心成员也都是对 AI 和数学充满热情的科研人员,联合创始人中许多来自巴黎综合理工的校友圈,其中包括Mistral 联合创始人 Guillaume Lample。

Numina 不融资,只接受捐赠,要引领 AI4MATH 领域的开放研究。
这样的理想也获得了行业内大量支持,成了一个朋友圈多多的组织。
这次参赛得到了 HuggingFace 和 Mistral 在算力和人员方面的支持,同时也得到了 Answer.ai 和北京大学北京国际数学研究中心的帮助,得以建立我们的数据集。
李嘉从巴黎综合理工毕业之后先创办了 AI 医疗公司 Cardiologs,被收购以后投身开源研究。
为什么搞起 AI 数学?李嘉在华南师范大学附属中学读高中时就接触了数学竞赛,后来与 HuggingFace 合作开发 BigCode 的时候开始接触大模型,看到了在数学方面的潜力。
那么为什么要成立一个非营利组织?也是在与 HuggingFace 合作的经历中认识到开放研究很重要,这次参加 AIMO 比赛的方案也受很多国内开源工作如 DeepSeek、MetaMath,TORA,Xwen-LM 团队的启发。
他们很遗憾看到整个领域越来越封闭,各大 AI 公司都认为数学数据是自己的核心优势,减少和大学的合作。
我们能够给各种大学、各种研究实验室提供一个相对好的平台,我们也能够有非常大的工程的勇气和毅力去做一些数据集。
联合创始人李嘉认为,就像 ImageNet 数据集和竞赛催生了 AlexNet,开启了视觉乃至整个深度学习的繁荣。
像这次比赛只要求验证模型输出的最终数值结果,不考虑计算过程、证明过程,也是由于缺少有效的过程测评方法。
最近的另一个代表性案例是 SWEbench,用于解决 GitHub Issue 来评估 AI 的代码能力,自基准发布后 6 个月内 SOTA 成绩从2% 上升到 40%。有效的测评方法出现,带动了整个任务的飞速发展。
所以说 Numina 的最终目标之一,是要做出 AI 数学的 ImageNet。
One More Thing
另外值得一提的是,这次比赛前 4 名参赛团队,无一例外全都使用了同一款基础模型:来自深度求索的 DeepSeekMath-7B。
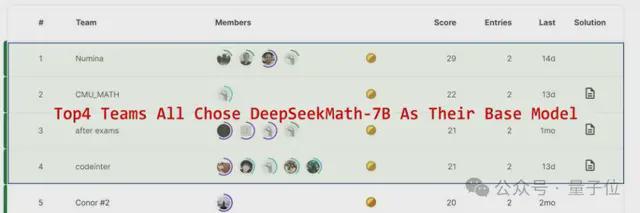
在数学任务上,可以说这款模型得到了最挑剔使用者的认可。
NuminaMath-7B
https://github.com/project-numina/aimo-progress-prize/tree/main
NuminaMath-CoT 数据集
https://huggingface.co/datasets/AI-MO/NuminaMath-CoT
参考链接:






