
新智元报道
编辑:乔杨
Scaling Law 还没走到尽头,「小模型」逐渐成为科技巨头们的追赶趋势。Meta 最近发布的 MobileLLM 系列,规模甚至降低到了 1B 以下,两个版本分别只有 125M 和 350M 参数,但却实现了比更大规模模型更优的性能。
从 5 月和 6 月几家科技巨头的发布会中,我们已经能隐隐感受到 AI 的一个重要发展趋势:从云数据中心走向个人用户,从大型服务器走向笔记本和移动设备。
遵循 Scaling Law 已经不再是唯一的路径,模型「以小搏大」的故事不断上演。
先有微软更新;后有谷歌用。
硬件方面,我们看到了 AI 功能逐渐与电子产品进行深度集成。
比如微软臭名昭著的 Recall 功能,正是他们的重要组成部分;苹果也在 Apple Intelligence 的大旗下推出用于,力求与 iOS 无缝衔接。
如今 LLM 的参数量动辄上百亿,苹果 3B 的参数量已经显得十分迷你,但对手机这种移动设备来说依旧有很高门槛。
不仅用2-bit 和4-bit 混合精度压缩模型(平均每个权重 3.5-bit),而且要有至少 8G 内存和 M1 芯片才能运行。
Meta 最近发表的一篇论文就表明,参数量可以进一步收缩,最新提出的 MobileLLM 模型参数量小于 1B,但性能依旧可观。

论文地址:https://arxiv.org/abs/2402.14905
LeCun 也亲自发推为这项研究背书,称赞了其中一系列精简参数量的操作。

这篇论文已被 ICML 2024 接收,模型的训练代码也已经在 GitHub 上开源。
GitHub 地址:https://github.com/facebookresearch/MobileLLM
简介
我们首先做个假设,如果把 GPT-4(大约有 1 万亿参数)以 50tokens/s的推理速度部署在生活中,你需要什么样的硬件?
答案是 1 亿个 H100 GPU。别说是移动设备了,家里都放不下。
那如果降低标准,用 LLaMA-v2 7B 这样的模型,再加上8-bit 量化呢?
简单计算一下,光存储模型参数就需要约 7GB,但不是存储空间,而是珍贵的运存空间(DRAM)。
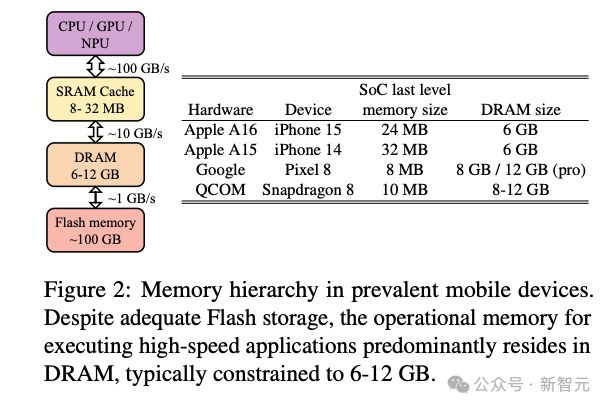
而且 DRAM 也不能被 AI 模型全占了,考虑到操作系统和其他应用的运行,LLM 的运存占比不能超过 10%。
按照图 2 的统计,各个品牌最近发布的移动设备一般会配备6~12GB 的 DRAM。这就意味着,如果要在手机上顺利部署,模型的参数量最好能降低到<1B。
不仅是运存,耗电也是一大问题。7B 模型的能耗大概是 0.7J/token,一个满电的 iPhone 大概有 50kJ 可供挥霍。计算下来,如果生成速度是 10tokens/s,手机充满一次电只够你和模型对话 2 小时。
基于上述考虑,用<1B 的模型部署在移动端是更理想的选择,因此 MobileLLM 的参数量定位在 125M/350M,比苹果的 3B 模型还少了一个数量级,可谓「迷你中的迷你」。
但是别被 Scaling Law 局限,参数小不意味着能力弱,模型架构的重要性应该重新进入我们的视线。
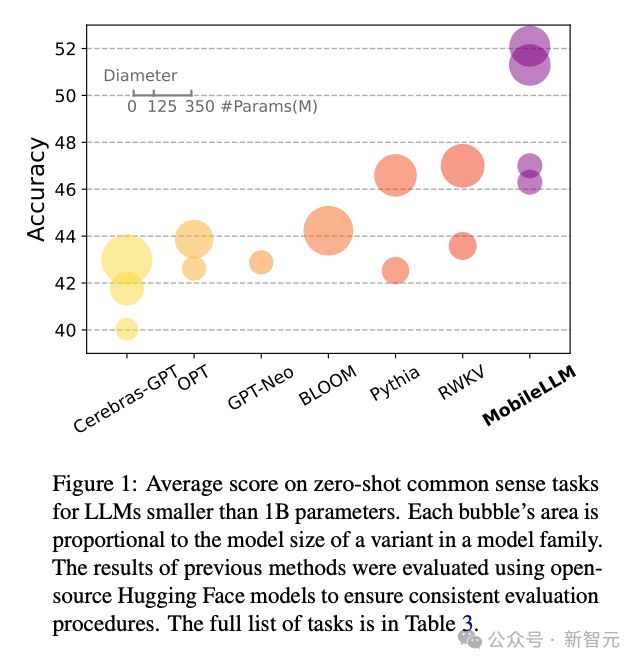
MobileLLM 不仅在同等大小的模型中达到了 SOTA 性能,而且提出,架构的深度比宽度更重要。一个「深而窄」的「瘦长」小模型同样可以学习到抽象概念。
架构与方法
在只有 125M/350M 参数的情况下,如何在有限范围内实现架构设计的最优化就成为了重要的问题。
对于<1B 的 LLM,作者探索出了 4 种行之有效的架构设计技巧。
1) 使用 SwiGLU 前馈网络
2) 让网络整体形状变得「狭长」,即深而窄
3) 重新使用编码共享(embedding sharing)方法
4) 使用组查询注意力机制(grouped query attention)
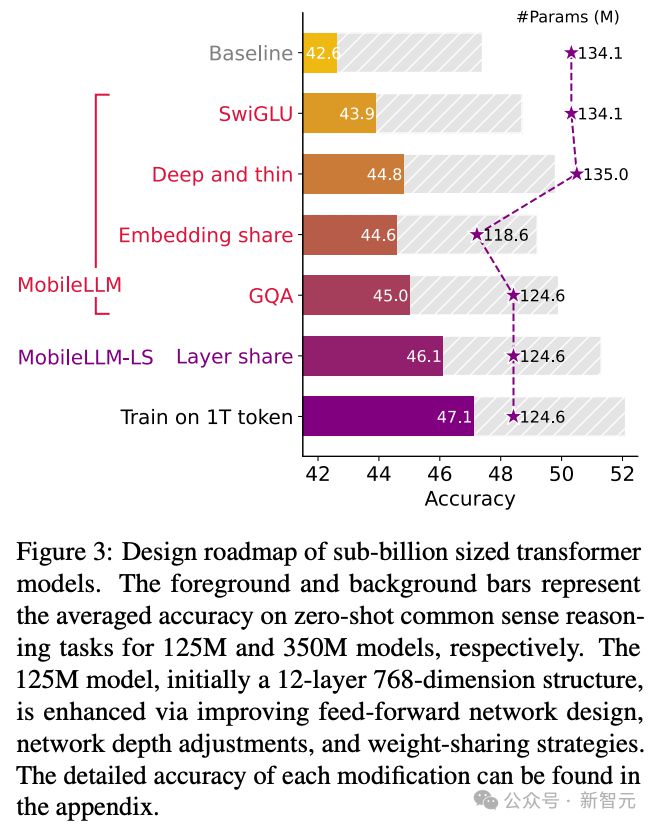
在此基础上,作者还提出了一种块间层共享(block-wise layer-sharing)方法,能够在不引入额外内存开销的情况下进一步提高模型准确率,但代价是增加解码过程的推理延迟。
这种添加了层共享机制的模型被标记为 MobileLLM-LS。
反驳 Scaling Law:小模型的架构设计很重要
2020 年提出 Scaling Law 的论文认为,训练数据量、参数量以及训练迭代次数才是决定性能的关键因素,而模型架构的影响几乎可以忽视。
然而这篇论文的作者通过对比实验提出,这个定律对小模型并不适用。
当模型参数固定在 125M 或者 350M 时,30~42 层的「狭长」模型明显比 12 层左右的「矮胖」模型有更优越的性能(图4),在常识推理、问答、阅读理解等 8 个基准测试上都有类似的趋势。
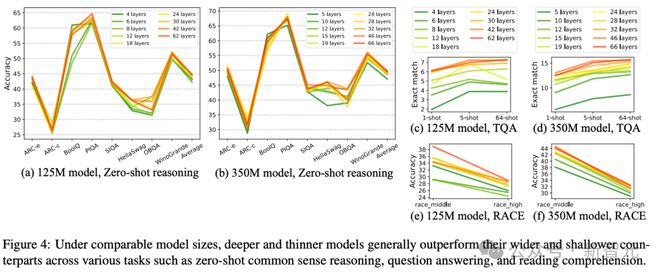
这其实是非常有趣的发现,因为以往为 125M 量级的小模型设计架构时,一般都不会叠加超过 12 层。
为什么要重拾「编码共享」
「编码共享」(embedding sharing)方法最开始由 OPT 这样的小模型提出,因为小模型中编码层的参数占到了相当大的比例。
比如,125M 模型中要使用上下文长度 32k、维度 512 的编码,输入和输出编码层就包含了 16M 的参数,占比达到 20%。
相较之下,大模型的编码层参数量显得微不足道。比如 LLaMA-7B 中,这个比例就下降到了 3.7%,LLaMA-70B 甚至只有 0.7%。因此,共享编码对于 LLM 来说可有可无。
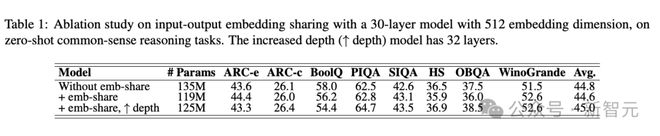
编码共享在大模型时代的过气,不代表这种技术不再适用于小模型,它可以让模型架构更紧凑、更有效率。
如表 1 所示,进行编码共享后,模型在总参数量降低 16M 的情况下依旧总体维持了原有性能,甚至在某些基准上有提升。
层共享机制
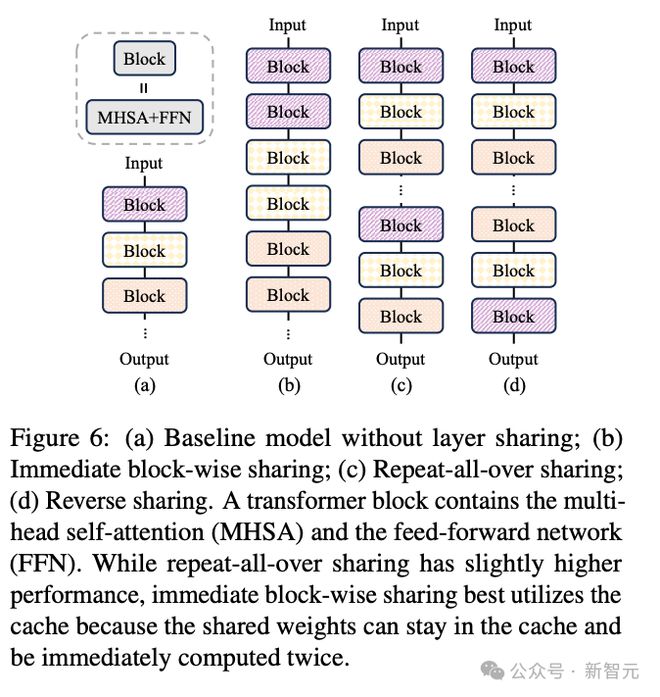
之前提到,论文的实验结果发现,让小模型变得「瘦长」有利于性能提升。于是作者想到:如果引入层共享机制,不就相当于保持参数总量不变的同时,增加了模型深度。
实验证明,这种方法的确可以提升性能,而且论文还对比了不同的层共享方法(图6),最终权衡设备内存、性能和推理延迟,选择了即时块间层共享(immediate block-wise sharing,图 6b)。
评估实验
作者构建了 125M 和 350M 参数的 MobileLLM/MobileLLM-LS 模型,并在 1T 的数据集上进行训练。
预训练后的模型在多个数据集上进行零样本测试,包括 ARC-easy、ARCchallenge、HellaSwag、 WinoGrande、TQA、RACE 等常用基准。
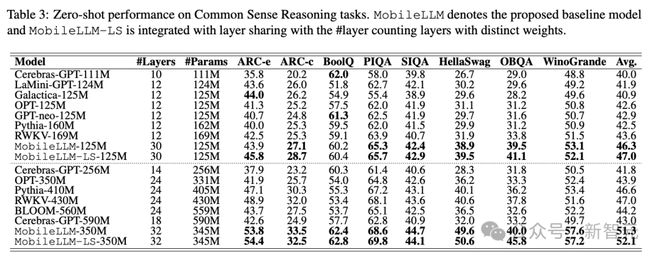
表 3 展示的是零样本常识推理方面的测评结果,MobileLLM 系列基本实现了全面 SOTA,不仅能超越之前发布的 OPT、BLOOM 等经典模型,也优于最近发布的 GPT-neo、Galactica、RWKV 等参数更大的模型。
在问答和阅读理解方面,MobileLLM 依旧表现出色(表4)。相比其他模型,125M 和 325M 的 MobileLLM 在 TQA 上分别有>6.4 分和约 10 分的提升。
下游任务
除了在基准测试上跑分,论文还考虑到了应用场景部署时对模型多方面的要求,并进行了相应测评。
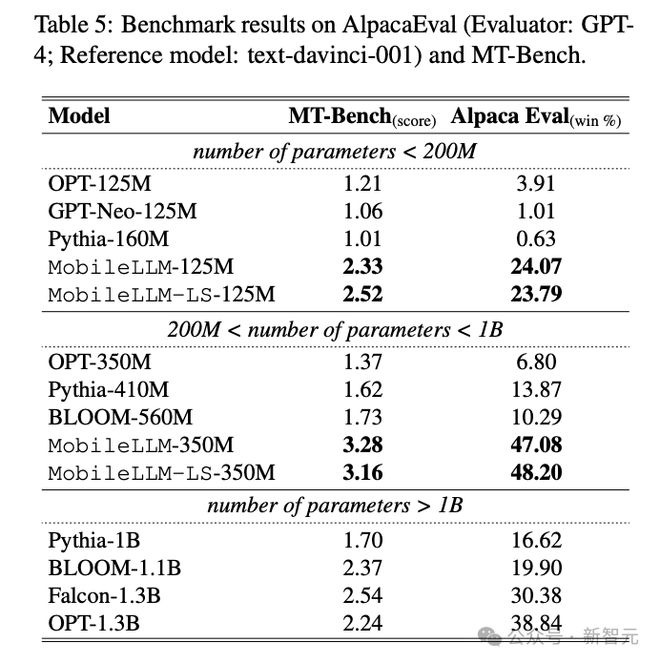
AlpacaEval 和 MT-Bench 分别测试模型在单轮和多轮聊天任务中的表现,相比其他 3 个基线模型,MobileLLM 依旧是性能最优,而且甚至能用 350M 的参数超过其他参数>1B 模型的表现。
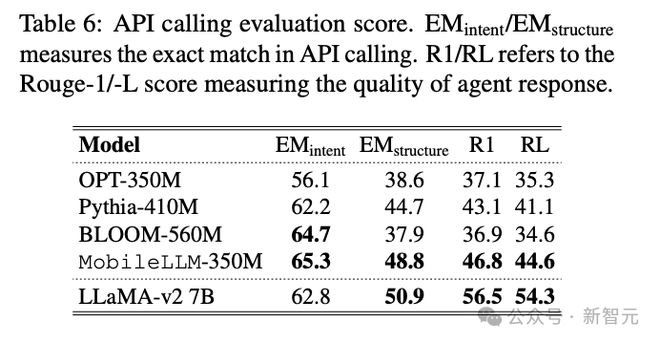
除了对话,在 API 调用的场景中,MobileLLM 的 EM 分数可以和 7B 参数的 LLaMA-v2 相匹配。
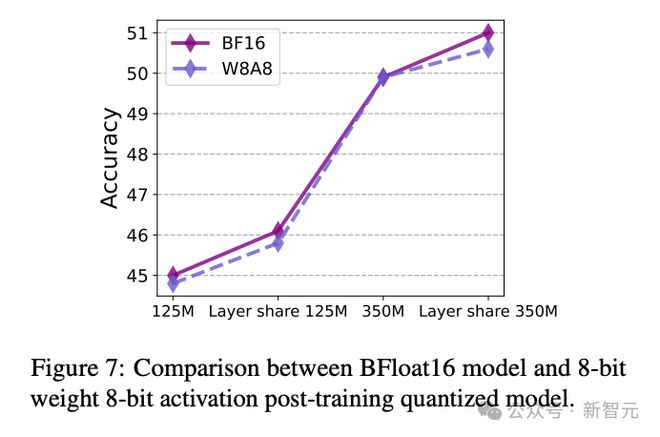
此外,MobileLLM 与量化(PTQ)的兼容性也很好。经过 W8A8 量化后,模型的性能只有不到 0.5 分的下降,并且依旧与层共享机制兼容,因此可以适应更严苛硬件条件下的部署。
作者简介
本文的通讯作者 Zechun Liu 是 Meta Reality Labs 的研究科学家。她本科毕业于复旦大学,博士毕业于香港科技大学,加入 Meta 前曾有两年多的时间在 CMU 担任访问学者。

Zechun 的研究兴趣是深度学习在现实场景中的应用,例如资源不足的限制、计算资源和精度之间的权衡等,其中重点关注网络二值化和量化、网络通道剪枝、架构设计、知识蒸馏等方面。
参考资料:






