
新智元报道
编辑:乔杨
继去年初的第一代 VALL-E 模型之后,微软最近又上新了 VALL-E 2 模型,标志着第一个在合成语音稳健性、相似度、自然程度等方面达到人类水平的文本到语音模型。
最近,微软发布了零样本的文本到语音(TTS)模型 VALLE-2,首次实现了与人类同等的水平,可以说是 TTS 领域里程碑式的进展。

论文地址:https://arxiv.org/pdf/2406.05370
随着近年来深度学习的快速进步,用录音室环境下的干净单人语音训练模型,已经可以达到人类同等水平的质量,但零样本 TTS 依旧是一个有挑战性的问题。
「零样本」意味着推理过程中,模型只能参照一段简短的陌生语音样本,用相同的声音说出文本内容,就像一个能即时模仿的口技大师。
听到这里,不知道你会不会突然警觉——有这种能力的模型就是 Deepfake 的最佳工具!
令人欣慰的是,MSRA 考虑到了这一点,他们目前只将 VALL-E 系列作为研究项目,并没有纳入产品或扩大使用范围的计划。
虽然 VALL-E 2 有很强的零样本学习能力可以像配音员一样模仿声音,但相似度和自然度取决于语音 prompt 的长度和质量、背景噪音等因素。
在项目页面和论文中,作者都进行了道德声明:如果要将 VALL-E 推广到真实世界的应用中,至少需要一个强大的合成语音检测模型,并设计一套授权机制,确保模型在合成语音前已经得到了声音所有者的批准。
对于微软这种只发论文不发产品的做法,有些网友表示非常失望。
毕竟最近各种翻车的产品让我们深深明白,只看 demo 完全不可靠,没法自己试用=没有。
但 Reddit 上有人揣测:微软只是不想当「第一个吃螃蟹的人」,不发模型是担心可能的带来的批评和负面舆论。
一旦有了能将 VALL-E 转化为产品的方法,或者市场上杀出其他竞品,难道还担心微软有钱不赚吗?

的确如网友所说,从项目页面目前放出的 demo 来看,很难判断 VALL-E 的真实水平。
项目页面:https://www.microsoft.com/en-us/research/project/vall-e-x/vall-e-2/
共 5 条文本都是不超过 10 个单词的英文短句,语音 prompt 的人声音色都非常相近,英语口音也不够多样化。
虽然 demo 不多,但能隐隐感受到,模型对英美口音的模仿非常炉火纯青,但如果 prompt 略带印度或者苏格兰口音,就很难达到以假乱真的程度。
方法
模型前身 VALL-E 发布于 2023 年初,已经是 TTS 在零样本方面的重大突破。VALL-E 能够用 3 秒的录音合成个性化语音,同时保留说话者的声音、情绪和声学环境。
然而 VALL-E 存在两方面的关键限制:
1)稳定性:推理过程中使用的随机采样(random sampling)可能会导致输出不稳定,而 top-p 值较小的核采样可能会导致无限循环问题。虽然可以通过多次采样和后续排序来缓解,但会增加计算成本。
2)效率:VALL-E 的自回归架构绑定了与现成的音频编解码器模型相同的高帧率,且无法调整,导致推理速度较慢。
虽然已经有多项研究用于改进 VALL-E 的这些问题,但往往会使模型的整体架构复杂化,而且增加了扩展数据规模的负担。
基于这些之前的工作,VALL-E 2 包含两方面的关键创新:重复感知采样(repetition aware sampling)和分组代码建模(grouped code modeling)。
重复感知采样是对 VALL-E 中随机采样的改进,能够自适应地采用随机采样或者核采样(nucleus sampling),选择的依据是曾经的 token 重复,因此有效缓解了 VALL-E 的无限循环问题,大大增强解码稳定性。

重复感知采样的算法描述
分组代码建模则是将编解码器代码划分为多个组,自回归时每组在单个帧上建模。不仅减少了序列长度、加速推理,还通过缓解长上下文建模问题来提高性能。
值得注意的是,VALL-E 2 仅需要简单的语音-转录文本数据进行训练,不需要额外的复杂数据,大大简化了数据的收集、处理流程,并提高了潜在的可扩展性。
具体来说,对于数据集中每条语音-文本数据,分别用音频编解码器编码器(audio codec encoder)和文本分词器将其表示为编解码器代码=[0,1,…,(−1)]和文本序列=[0,1,…,(−1)],用于自回归(AR)和非自回归(NAR)模型的训练。
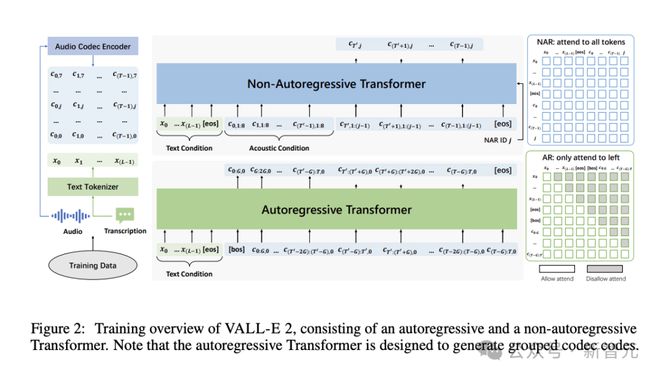
AR 和 NAR 模型都采用 Transformer 架构,后续的评估实验设计了 4 种变体进行对比。它们共享相同的 NAR 模型,但 AR 模型的组大小分别为1、2、4、8。
推理过程也同样是 AR 和 NAR 模型的结合。以文本序列和代码提示<′,0 为条件生成目标代码≥′,0 的第一代码序列,再用自回归的方式生成每组的目标代码。
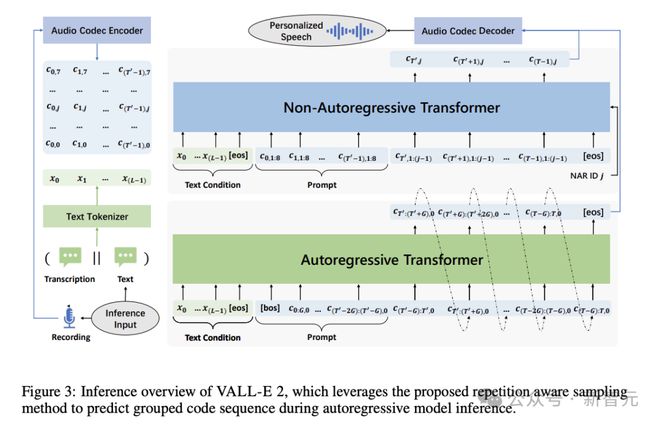
给定≥′,0 序列后,就可以使用文本条件和声学条件<′推断 NAR 模型,以生成剩余的目标代码序列≥′,≥1。
模型训练使用了 Libriheavy 语料库中的数据,包含 7000 个人朗读英语有声书的 5 万小时语音。文本和语音的分词分别使用 BPE 和开源的预训练模型 EnCodec。
此外,也利用了开源的预训练模型 Vocos 作为语音生成的音频解码器。
评估
为了验证模型的语音合成效果是否能达到人类同等水平,评估采用了 SMOS 和 CMOS 两个主观指标,并使用真实的人类语音作为 ground truth。
SMOS(Similarity Mean Opinion Score)用于评估语音与原始提示的相似度,评分范围为1~5,增量为 0.5 分。
CMOS(Comparative Mean Opinion Score)用于评估合成语音与给定参考语音的比较自然程度,标度范围为-3~3,增量为1。
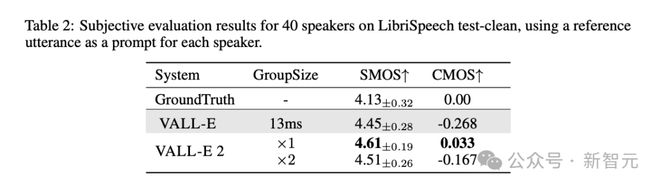
根据表 2 结果,VALL-E 2 的主观评分不仅超过了第一代的 VALL-E,甚至比人类真实语音有更完美的表现。
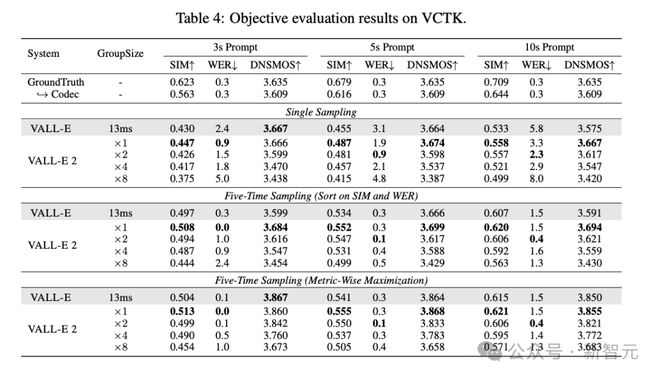
此外,论文也使用了 SIM、WER 和 DNSMOS 等客观指标来评估合成语音的相似度、鲁棒性和整体感知质量。
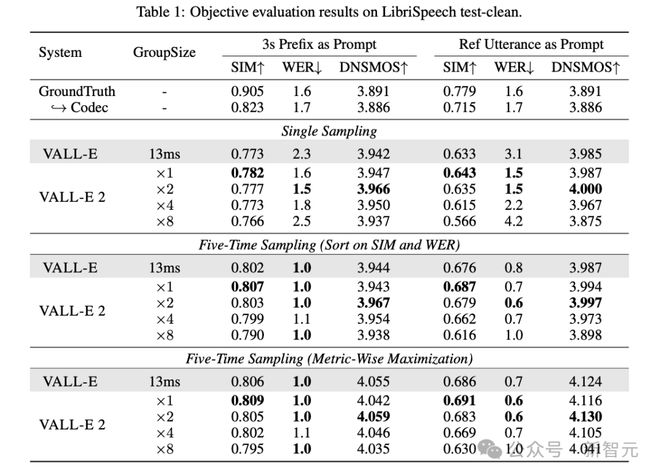
在这 3 个客观指标上,无论 VALL-E 2 的组大小如何设置,相比 VALL-E 都有全方位的提升,WER 和 DNSMOS 分数也优于真实人类语音,但 SIM 分数还存在一定差距。
此外,从表 3 结果也能发现,VALL-E 2 的 AR 模型组大小为 2 时,可以取得最优效果。
在 VCTK 数据集上的测评也可以得到相似的结论。当 prompt 长度增加时,分组代码建模方法可以减少序列长度,缓解 Transformer 架构中不正确注意力机制导致的生成错误,从而在 WER 分数上得到提升。
作者简介
本文第一作者陈三元是哈尔滨工业大学和微软亚洲研究院的联合培养博士,他从 2020 年开始担任 MSRA 自然语言计算组的实习研究员,研究兴趣主要是用于语音和音频处理的预训练语言模型。

参考资料:






