
新智元报道
编辑:桃子好困
一年一度的 ICML 顶会大奖终于公布了!今年,共有十篇论文夺得最佳论文奖,而这其中的 3 篇可谓是家喻户晓——图像生成模型 SD3、视频生成模型 VideoPoet、基础世界模型 Genie。另外,时间检验奖颁给了贾扬清和团队十年前提出的框架 DeCAF。
ICML 2024 大奖新鲜出炉了!
刚刚,ICML 开幕式正式召开,会上公布了 10 篇最佳论文奖,还有 1 篇十年前论文摘得时间检验奖。
最佳论文中,有几篇 AI 图像、视频生成领域的爆火之作,包括 SD3 技术报告、CMU 谷歌 AI 视频模型 VideoPoet、谷歌基础世界模型 Genie。

值得一提的是,AI 大牛贾扬清等人在 2013 年 10 月发表的论文 DeCAF,获得了时间检验奖。
刚刚,他发文表示,深感荣幸获此殊荣。

CMU 教授、Meta GenAI 副总 Russ Salakhutdinov 对 ICML 2024 整体录用结果做了一个总结:
这届顶会一共收到了 9473 篇论文,其中 2610 篇被录用,录用率为 27.55%。144 篇是 Oral,还有 191 篇是 Spotlight。
今年全新引入的 Position 论文,提交有 286 篇,75 篇被接收(26%)。15 篇是 Oral,11 篇是 Spotlight。
另外,Workshop 中有 145 个提案,30 个被接收。Tutorial 有 55 个提案,12 个被接收。

今年,是 ICML 2024 第 41 届年会(每年一届),于 7 月 21 日-27 日在奥地利维也纳举办。

8675 人纷纷前来现场参会,台下虚无坐席。


ICML 2024 顶会速览
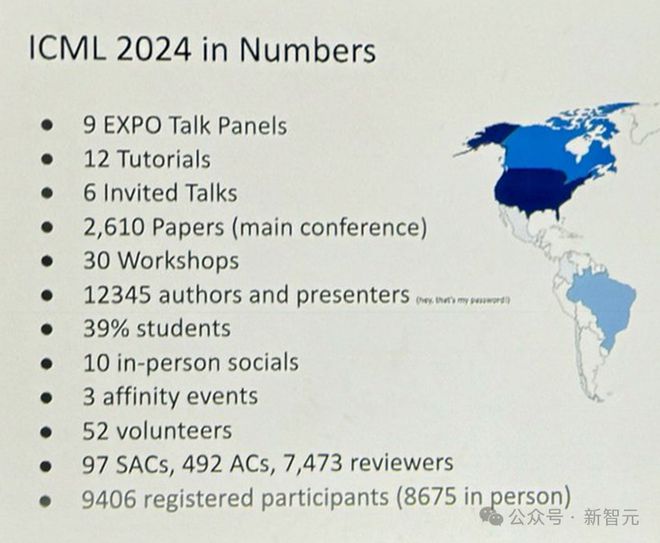
颁奖前,组委会首先介绍了下,今年大会的整体情况:
· 9 个 EXPO Talk Panel
· 12 个 Tutorial
· 6 个特邀演讲
· 2,610 篇论文(主会议)
· 30 个研讨会
· 12345 位作者和演讲者
· 39% 参与者是学生
· 10 个线下社交活动
· 3 个 affinity event
· 52 名志愿者
· 97 位高级区域主席(SAC),492 位区域主席(AC),7473 名审稿人
· 9406 名注册参会者(其中8,675 人现场参会)
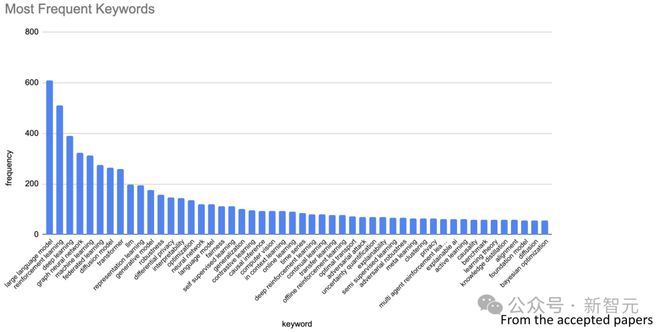
根据被录用的论文,ICML 汇总了出现的高频词,也正是这一年的热点词:
大模型出现频率最高,超过了 600+ 次。
其次是强化学习、深度学习、图神经网络、机器学习、联邦学习、扩散模型、Transformer、LLM、表示学习、生成模型等等。
从注册国家/地区来看,美国高达 2463 人,中国以 1100+ 人位列第二。
时间检验奖
通常来说,时间检验奖颁给 10 年以上的产生重要持久影响的学术论文。

这篇论文还是 Caffe 之父贾杨清就读于 UC 伯克利,在谷歌实习期间和团队合作完成的经典之作。
他曾在采访中表示,2013 年在谷歌实习时喝了太多咖啡,由此起名 DeCAF,为的是督促自己把咖啡戒了。

加班途中,他发文称,「DeCAF 应该是视觉领域的 foundation features 和 deepembedding,也让计算机视觉领域有了一个 generalizable feature..」
DeCAF 研究的影响在于,催生了通用物体检测框架R-CNN,高性能异构计算的框架 Caffe,间接促成了伯克利和英伟达合作编写了第一代的加速框架 CuDNN,雅虎实验室创作的大规模分布式训练 CaffeOnSpark 等一系列工作,奠定了伯克利在深度学习浪潮当中的领先地位。

题目:DeCAF: A Deep Convolutional Activation Feature for Generic Visual Recognition
作者:Jeff Donahue,Yangqing Jia,Oriol Vinyals,Judy Hoffman,Ning Zhang,Eric Tzeng,Trevor Darrell
机构:加利福尼亚大学伯克利分校

论文地址:https://arxiv.org/abs/1310.1531
为了用一个更好的概率框架来表达人的行为,团队亲自写了第一个框架——DeCAF。
在这项工作中,作者评估了从一个在大量固定物体识别任务上以全监督方式训练的深度卷积网络中提取的特征,能否在新的通用任务上重新得到利用。
这些通用任务与最初的训练任务可能存在显著差异,且可能缺乏足够的标注数据,或完全没有标注数据,因此无法使用常规方法训练或微调深度网络来适应新任务。
此外,作者还可视化了深度卷积特征在场景识别、领域适应和细粒度识别等任务中的语义聚类,并通过比较依赖于网络不同层次来定义固定特征的效果,提出了在几个重要的视觉挑战上取得的新 SOTA。
最后,作者发布了这些深度卷积激活特征的开源实现——DeCA,以及所有相关的网络参数。从而帮助视觉作者能够在各种视觉概念学习范式中进行深度表征的实验。

十篇最佳论文
今年,一共有十篇最佳论文。


以上排名皆以 oral 展示为序
论文一:Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
作者:Aaron Lou,Chenlin Meng,Stefano Ermon
机构:斯坦福大学,Pika Labs

论文地址:https://arxiv.org/abs/2310.16834
这项研究提出了一个全新的机器学习模型 SEDD(Score Entropy Discrete Diffusion),主要针对离散数据生成任务。
当前,扩散模型在许多生成建模任务中,展现出突破性的性能,但在自然语言等离散数据领域却表现不佳。
论文中,作者提出了得分熵(score entropy)的概念,来弥补这种差距。
这是一种新颖的损失函数,自然地将得分匹配扩展到离散空间,无缝集成以构建离散扩散模型,并显著提升性能。
实验评估过程中,SEDD 比现有语言扩散模型表现更好(困惑度降低 25-75%)。
而且,它还在某些方面超过了 GPT-2 等自回归模型。
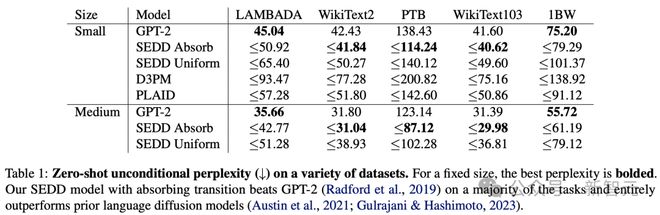
总而言之,SEDD 的优势在于:
- 无需使用温度 scaling 等技术就能生成高质量文本(生成困惑度比未退火的 GPT-2 好约6-8 倍)
- 可以在计算资源和输出质量之间进行灵活权衡(使用 32 倍更少的网络评估次数达到相似的性能)
- 支持可控的文本填充,提供更多灵活性。(匹配核(matching nucleus)采样质量,同时支持除从左到右提示之外的其他策略)。
论文二:Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
作者:Patrick Esser,Sumith Kulal,Andreas Blattmann,Rahim Entezari,Jonas Müller,Harry Saini,Yam Levi,Dominik Lorenz,Axel Sauer,Frederic Boesel,Dustin Podell,Tim Dockhorn,Zion English,Kyle Lacey,Alex Goodwin,Yannik Marek,Robin Rombach
机构:Stability AI

论文地址:https://arxiv.org/abs/2403.03206
正如开头所述,这篇论文是爆火出圈的 Stable Diffusion 3 的技术报告。
与 Sora 类似,SD3 采用了改进版的 Diffusion 模型和一个基于 DiT 的文生图全新架构。
具体而言,作者利用了三种不同的文本编码器——两个 CLIP 模型和一个 T5——来处理文本信息,同时使用了一个更为先进的自编码模型来处理图像信息。
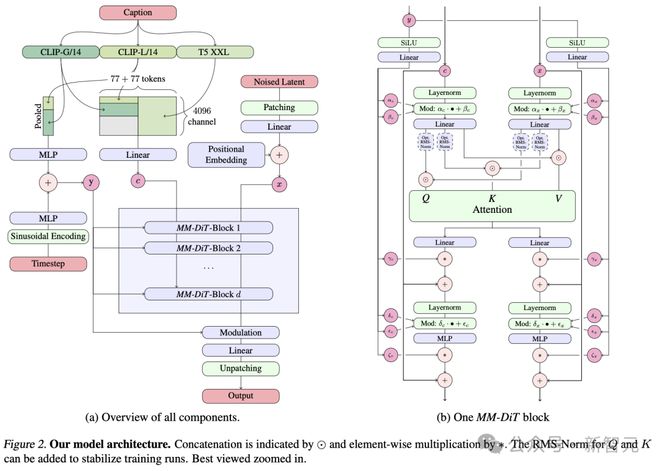
全新提出的多模态扩散 Transformer(MMDiT)架构,采用了分别针对图像和语言表示的独立权重集,与 SD3 的早期版本相比,显著提升了对文本的理解和文字的拼写能力。
评估结果显示,无论是在遵循提示的准确性、文本的清晰呈现还是图像的视觉美感方面,SD3 都达到或超过了当前文生图生成技术的最高水平。

论文三:Probabilistic Inference in Language Models via Twisted Sequential Monte Carlo
作者:Stephen Zhao,Rob Brekelmans,Alireza Makhzani,Roger Grosse
机构:多伦多大学,Vector Institute

论文地址:https://arxiv.org/abs/2404.17546
这项研究主要关注的是,大模型中采样和推理问题。
LLM 许多能力和安全技术,比如 RLHF、自动化红队测试、提示工程和填充等,皆可以被视为:
给定奖励或潜在函数,在其定义的未归一化目标分布中进行采样。这一分布是针对完整序列定义的。
论文中,作者提出利用序列蒙特卡洛(SMC)方法,来解决这些采样概率问题。
对此,作者提出了扭曲函数(twist functions)来估计每个时间步的潜在未来值,进而优化采样过程。
此外,他们还提出了使用新型双向 SMC 边界(bounds),以评估 LLM 推理技术准确性的方法。
最终结果显示,扭曲 SMC 在以下方法中展现出强大效力:从预训练模型中采样不良输出、生成带有不同情感的评论,以及执行填充任务。
论文四:Position: Measure Dataset Diversity,Don't Just Claim It
作者:Dora Zhao,Jerone T.A. Andrews,Orestis Papakyriakopoulos,Alice Xiang
机构:斯坦福大学,慕尼黑工业大学,Sony AI

论文地址:https://arxiv.org/abs/2407.08188
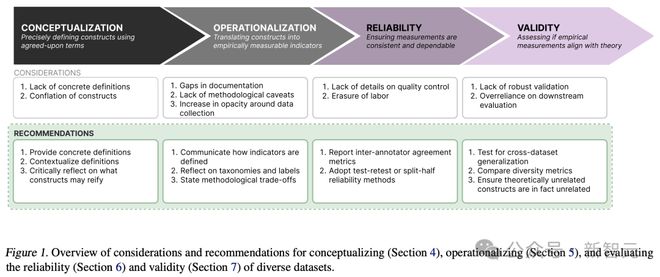
当前,许多数据集都为自己贴上多样性的标签,但实际上却包含着抽象且富有争议的社会概念。
在这项工作中,作者通过分析 135 个图像和文本数据集中的「多样性」,来探讨这一问题。
如下图所示,作者借鉴社会科学理论中测量理论,作为需要考虑的因素,并为概念化、操作化和评估数据集中的多样性提供建议。
这项研究最终目的是,呼吁在机器学习研究中,特别是在数据集构建过程中,希望 AI 学者对带有价值判断的属性数据,采取更加细致和精确的处理方法。
论文五:Stealing Part of a Production Language Model
作者:Nicholas Carlini,Daniel Paleka,Krishnamurthy Dj Dvijotham,Thomas Steinke,Jonathan Hayase,A. Feder Cooper,Katherine Lee,Matthew Jagielski,Milad Nasr,Arthur Conmy,Itay Yona,Eric Wallace,David Rolnick,Florian Tramèr
机构:苏黎世联邦理工学院,华盛顿大学,麦吉尔大学,Google DeepMind,OpenAI

论文地址:https://arxiv.org/abs/2403.06634
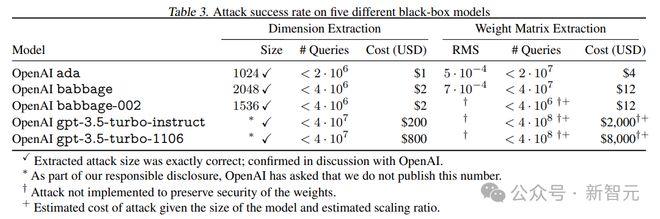
在这项工作中,作者提出了首个能够从黑盒语言模型(如 OpenAI 的 ChatGPT 或 Google 的 PaLM-2)中提取精确且复杂信息的模型窃取攻击。
具体来说,这种攻击能够通过常规的 API 访问,重建 Transformer 模型的嵌入投影层(在对称性条件下)。
并且,只需不到 20 美元,便可提取 OpenAI 的 Ada 和 Babbage 语言模型的整个投影矩阵。从而首次证实了这两个黑盒模型分别具有 1024 和 2048 的隐藏维度。
此外,作者还还原了 gpt-3.5-turbo 模型的确切隐藏维度大小。而这次,整个投影矩阵的提取成本,也不过是 2000 美元。
最后,作者提出了潜在的防御和缓解措施,并讨论了对未来工作影响。
论文六:Information Complexity of Stochastic Convex Optimization: Applications to Generalization and Memorization
作者:Idan Attias,Gintare Karolina Dziugaite,Mahdi Haghifam,Roi Livni,Daniel M. Roy
机构:本·古里安大学,东北大学,特拉维夫大学,多伦多大学,Vector Institute,Google DeepMind

论文地址:https://arxiv.org/abs/2402.09327
在这项工作中,作者研究了在随机凸优化问题(SCO)背景下记忆化和学习之间的相互作用。
首先,通过学习算法揭示与训练数据点相关信息来定义记忆化。然后,使用条件互信息(Conditional Mutual Information,CMI)框架来进行量化。从而,实现了对学习算法的准确性与其 CMI 之间权衡的精确描述。
结果显示,在L^2 Lipschitz 有界设置和强凸性条件下,每个超额误差为ε的学习者的 CMI 分别在Ω(1/ε^2) 和Ω(1/ε)处有下界。
更进一步,作者通过设计一个能准确识别特定 SCO 问题中大部分训练样本的对抗者,证明了记忆化在 SCO 学习问题中的重要作用。
最后,作者列举了几项重要意义,例如基于 CMI 的泛化界限的限制以及 SCO 问题中样本不可压缩性。
论文七:Position: Considerations for Differentially Private Learning with Large-Scale Public Pretraining
作者:Florian Tramèr,Gautam Kamath,Nicholas Carlini
机构:苏黎世联邦理工学院,滑铁卢大学,Vector Institute,Google DeepMind

论文地址:https://arxiv.org/abs/2212.06470
通过利用在大型公共数据集上预训练的非私有模型的迁移学习能力,可以显著提升差分隐私机器学习的性能。
在这项工作中,作者质疑了使用大型网络抓取数据集是否符合差分隐私保护。并警告称,将这些在网络数据上预训练的模型称为「private」可能会带来诸多危害,比如削弱公众对差分隐私这一概念的信任。
除了使用公共数据的隐私考虑之外,作者还进一步质疑了这种方法的实用性。
对于那些大到终端用户无法在自己设备上运行的模型,预训练的影响尤为明显。因为这将需要将私有数据外包给计算能力更强的第三方,因此部署此类模型会对隐私造成净损失。
最后,作者讨论了随着公共预训练变得越来越流行和强大,隐私学习领域的潜在发展路径。
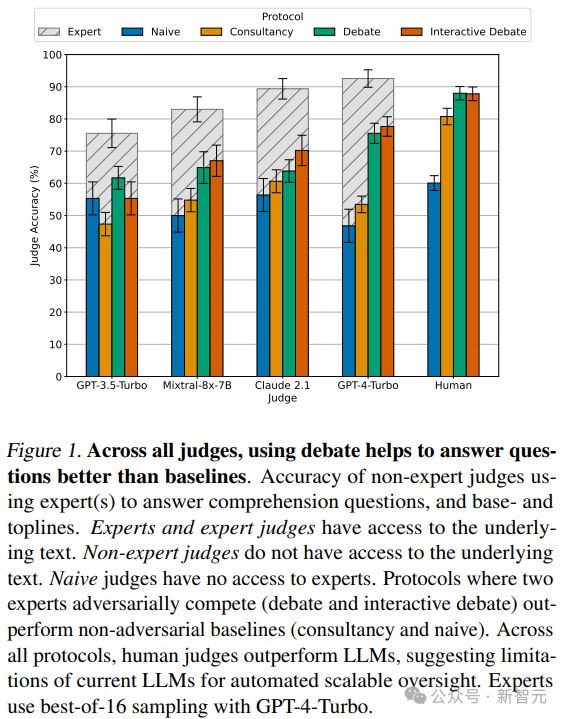
论文八:Debating with More Persuasive LLMs Leads to More Truthful Answers
作者:Akbir Khan, John Hughes, Dan Valentine, Laura Ruis, Kshitij Sachan, Ansh Radhakrishnan, Edward Grefenstette, Samuel R. Bowman, Tim Rocktäschel, Ethan Perez
机构:伦敦大学学院,Speechmatics,MATS,Anthropic,FAR AI

论文地址:https://arxiv.org/abs/2402.06782
目前常用的 LLM 对齐方法,严重依赖于人工标注的数据。
然而,随着模型变得越来越复杂,它们将超越人类的专业知识,人工评估的角色将演变为非专家监督专家。
基于此,作者提出了一个疑问:较弱的模型能否评估较强模型的正确性?
根据设定,较强的模型(专家)具备回答问题的必要信息,而较弱的模型(非专家)缺乏这些信息。
而评估的方法则是辩论,即两个 LLM 专家各自为不同的答案辩护,而非专家选择答案。
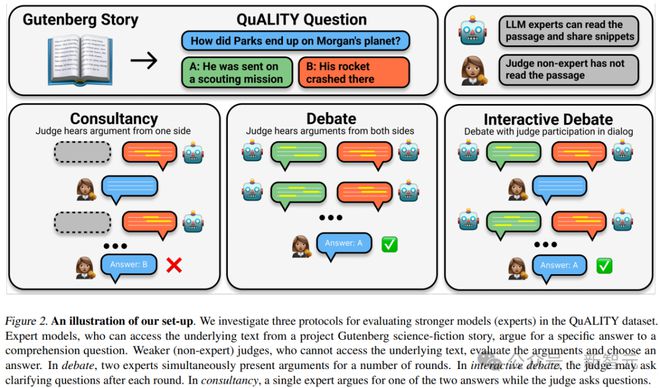
结果显示,辩论始终可以帮助非专家模型和人类更好地回答问题,分别达到了 76% 和 88% 的准确率(基线分别为 48% 和 60%)。
此外,通过无监督方式优化专家辩手的说服力提高了非专家在辩论中识别真相的能力。
论文九:Genie: Generative Interactive Environments
作者:Jake Bruce,Michael Dennis,Ashley Edwards,Jack Parker-Holder,Yuge Shi,Edward Hughes,Matthew Lai,Aditi Mavalankar,Richie Steigerwald,Chris Apps,Yusuf Aytar,Sarah Bechtle,Feryal Behbahani,Stephanie Chan,Nicolas Heess,Lucy Gonzalez,Simon Osindero,Sherjil Ozair,Scott Reed,Jingwei Zhang,Konrad Zolna,Jeff Clune,Nando de Freitas,Satinder Singh,Tim Rocktäschel
机构:哥伦比亚大学、Google DeepMind

论文地址:https://arxiv.org/pdf/2402.15391
谷歌 DeepMind 团队发布的基础世界模型——Genie「精灵」。
从一个图像,一张照片,一个草图中,它就能生成一个无穷无尽的世界。

Genie 的疯狂之处在于,学习了 20 万小时的未标注互联网视频,无需监督即可训练。
无需任何动作标注,便可以确定谁是主角,并让用户能够在生成的世界中对其控制。
具体来说,它是通过潜动作(latent action)模型、视频分词器,以及自回归动态模型三大核心组件来实现的。
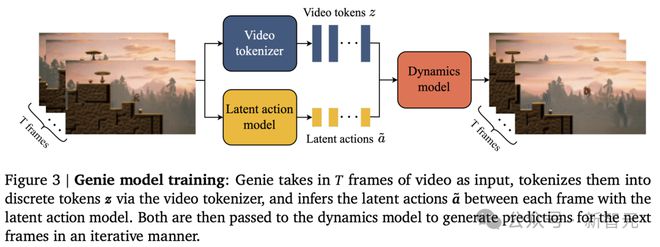
由此产生的学习潜动作空间,不仅使用户交互成为可能,而且还有助于训练智能体模仿看不见的视频中的行为。
总而言之,Genie 为培养未来的通才智能体开辟了崭新的途径,重塑了交互式生成环境的格局。
论文十:VideoPoet: A Large Language Model for Zero-Shot Video Generation
作者:Dan Kondratyuk,Lijun Yu,Xiuye Gu,José Lezama,Jonathan Huang,Grant Schindler,Rachel Hornung,Vighnesh Birodkar,Jimmy Yan,Ming-Chang Chiu,Krishna Somandepalli,Hassan Akbari,Yair Alon,Yong Cheng,Josh Dillon,Agrim Gupta,Meera Hahn,Anja Hauth,David Hendon,Alonso Martinez,David Minnen,Mikhail Sirotenko,Kihyuk Sohn,Xuan Yang,Hartwig Adam,Ming-Hsuan Yang,Irfan Essa,Huisheng Wang,David A. Ross,Bryan Seybold,Lu Jiang
机构:卡内基梅隆大学、Google

论文地址:https://arxiv.org/pdf/2312.14125
在 Sora 发布之前,谷歌和 CMU 团队在 23 年 12 月,在技术路线上推出了与 Sora 相似的视频生成技术——VideoPoet。
VideoPoet 一次能够生成 10 秒超长,且连贯大动作视频,而且无需特定数据便可生成视频。

具体来说,VideoPoet 主要包含以下几个组件:
- 预训练的 MAGVIT V2 视频 tokenizer 和 SoundStream 音频 tokenizer,能将不同长度的图像、视频和音频剪辑转换成统一词汇表中的离散代码序列。这些代码与文本型语言模型兼容,便于与文本等其他模态进行结合。
- 自回归语言模型可在视频、图像、音频和文本之间进行跨模态学习,并以自回归方式预测序列中下一个视频或音频 token。
- 在大语言模型训练框架中引入了多种多模态生成学习目标,包括文本到视频、文本到图像、图像到视频、视频帧延续、视频修复/扩展、视频风格化和视频到音频等。此外,这些任务可以相互结合,实现额外的零样本功能(例如,文本到音频)。
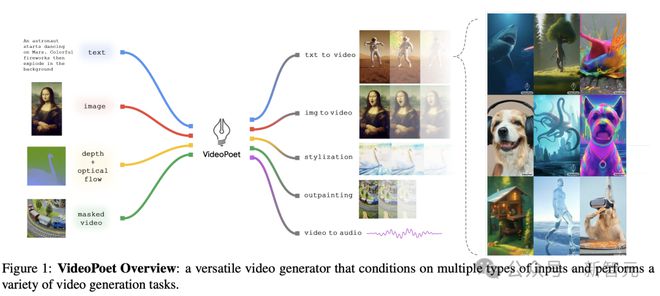
与领先模型不同的是,VideoPoet 并非基于扩散模型,而是多模态大模型,便可拥有 T2V、V2A 等能力。
总之,VideoPoet 具备了三大优势:生成更长的视频、实现更精准的控制、强大的运镜手法。

最佳审稿人奖
最好,ICML 2024 大会上,还公布了最佳审稿人奖。

参考资料:






