7 月 23 日,Meta 正式发布 Llama 3.1 模型,包含 8B、70B 和 405B 三种参数规模。其中 405B 是目前最大开源模型之一,拥有 4050 亿参数,支持多语言输入输出,在复杂数学和即时生成内容方面表现出色。
为了给企业、开发者提供更多元的模型选择,腾讯云 TI 平台迅速响应,国内首批完成 Llama 3.1 的适配和上架,支持一键发起精调和推理。腾讯云对该系列模型进行了精调、推理测试验证,保障模型的可用性、易用性,可覆盖智能对话、文本生成、写作等多个不同场景。
此前,腾讯云 TI 平台除了内置自研的腾讯混元大模型、行业大模型之外,也已广泛接入了 Llama 3、Baichuan、Falcon、Dolly、Vicuna、Bloom 等市场主流开源大模型,支持快速发起训练任务或部署推理服务,使用流程简单,开发效率高。企业、开发者可以根据不同细分场景的业务需求,灵活选择各类大模型,降低模型使用成本。
打造面向实战的大模型精调工具链,助力企业智能化升级
腾讯云 TI 平台致力于构建面向实战的大模型精调工具链,帮助用户训练出真正可用的大模型,并缩短模型开发周期,提升研发效率与资源利用率。
平台在数据准备阶段提供极致灵活高效的数据构建与标注能力,包括 3 大类数据处理 pipeline,覆盖有监督多轮问答、单轮问答和无监督预训练,以及 5 大高质量处理环节,如原始数据分析、数据清洗、数据去重等。代码完全开源,支持用户按需灵活修改。此外,平台还基于腾讯云的实战经验,沉淀了覆盖 12 大类 LLM 应用场景的 100 多万条精调配比数据,智能分配配比数据量,解决过拟合或能力遗忘问题,有效提升模型效果。
在数据标注方面,腾讯云 TI 平台升级面向 LLM 和多模态大模型的数据标注能力,首创基于 Schema 定义数据标注结构及组件,提供个性化标注操作台,实现业内最极致的多模态数据标注灵活性。
精调训练阶段,腾讯云 TI 平台提供易用、稳定、高效的训练工具。内置主流开源大模型及腾讯混元等自研模型,支持一键启动精调任务。通过 3 层机制保障大规模训练稳定运行,包括硬件容错、容器调度、任务断点续训。基于自研的 Angel 训练框架,整体提升 30% 的训练性能,部分模型如 baichuan2 模型相比 deepspeed 加速 70%,显著提升任务成功率及资源利用率。
模型验证评测阶段,腾讯云 TI 平台贴合算法真实使用流程,提供轻量体验、客观评测、主观评测三阶段评测能力。轻量体验通过在线问答形式体验模型效果,确保模型训练过程不出现大偏差;客观评测使用业界主流开源评测集进行自动化评估;主观评测则通过业务人员人工标注打分,保障最终模型效果。
同时,为了简化开发流程,腾讯云 TI 平台还对外开放 API 接口和丰富的 SDK,开发者可以轻松地将 Llama 3.1 等模型集成到自己的应用中,无需进行复杂的配置和改动,显著提升了开发效率和应用的迭代速度。
持续推动大模型生态建设,加速模型应用场景落地
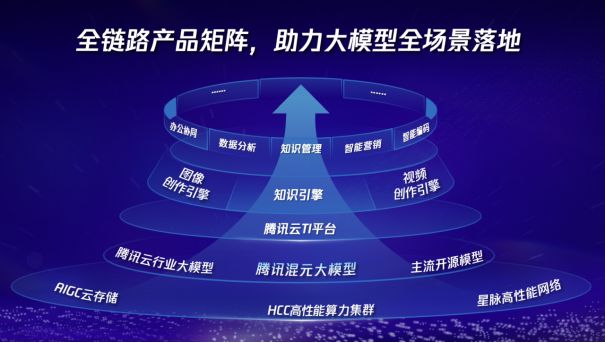
目前,腾讯在大模型领域已经构建了一套全链路产品矩阵,涵盖从底层丰富基础设施到顶层多元智能应用。包括自研通用大模型、模型开发平台、智能体开发平台,以及针对不同场景定制的智能应用解决方案等。通过这些产品和方案,致力于助力企业客户高效地将大模型技术应用到实际业务场景中,实现快速部署和价值创造。
在医疗行业,腾讯云携手上海市数字医学创新中心,共研医学大模型,目前在瑞金医院实现了总检报告和电子病历生成等相关项目的落地应用。以体检报告生成为例,平均每 5 秒即可自动生成一份总检报告,为医生节约 50%+的撰写时间。
在文娱行业,阅文集团一直利用大模型能力持续提升其用户写作和插图制作效率,但面临模型迭代快、更新复杂和推理成本高昂等问题。腾讯云 TI 平台的应用简化了模型训练配置,通过加速框架提升了推理速度,同时提供了易于使用的管理工具,助力持续解决上述难题。
大模型时代,算力、网络、数据构成了底层基础设施的“铁三角”。除了提供一站式 AI 大模型服务之外,腾讯云还为客户提供了 HCC 高性能计算集群、星脉高性能计算网络以及向量数据库等基础设施服务。
不断为千行百业打造行业大模型解决方案的同时,腾讯云也在积极参与行业大模型标准的制定。在金融领域,腾讯云与信通院合作,发布了国内首个金融行业大模型标准,为智能化发展和大模型的安全合规提供了支持;在医疗健康领域,腾讯参与编写的《人工智能大模型赋能医疗健康产业白皮书(2023 年)》已发布,旨在推动医疗健康大模型的发展并提出标准建议。
与此同时,腾讯还被选举为全国信标委人工智能分委会委员兼副秘书长单位,作为核心成员,承担了更多标准制定工作以及技术引领作用。未来,腾讯云将持续优化技术,推动大模型生态建设,加速千行百业应用落地,为各行业的数字化转型提供有力支持。






