文扬帆出海,作者丨子墨
继 Sora、Runway、Pika 后,又一图(文)生视频的 AI 产品爆火——Dream Machine。
Dream Machine 背后是一家成立于 2021 年的美国公司,名为 Luma AI。3 年以来成功进行了 3 轮融资,合计融资额 6730 万美元。最近一次进行的B轮融资 4300 万美元发生在今年 1 月,由著名风投机构 a16z 领投,英伟达二次跟投,投后估值达到2-3 亿美元。

今年 6 月,Dream Machine 在全球范围内开启免费公测,每个用户每月有 30 次免费生成视频的机会,每条视频时长为 5 秒。为了能和先入局者对标与抗衡,它更突出了“效率”、“物理”、“运镜”几个特点。仅用 120 秒的时间即可生成 120 帧视频是主打特色之一(不过在公测期间排队人数过多,用户普遍反馈生成一个视频需要 10-20 分钟时间,有的甚至要 2 个小时),能够模拟物理世界,还特别强调角色一致性,并能通过自然的运镜技巧,让画面更加流畅逼真,与所表达的情感相融合。用户的头脑风暴让生成的视频充满了创意与想象,运用在广告宣传、教学培训、故事创作等领域,也起到了明显的降本增效作用。
AI 视频生成产品哪家强?
在设计上 Dream Machine 的页面直观且简单,有文生视频和图生视频两个功能。文生视频中,用英文描述的效果会更好一些,想要让生成的视频更加符合需求,需要尽量精准且详细的文字描述,还可加上一些关于情感表述的词语,让效果更加逼真。
不过对于文字创作能力没那么好强的用户来说,图生视频功能会更受青睐,因为它更像是在一个作品上的二次加工。只需上传一张图片,再根据脑海中的情景加入一段文字描述,就可以让静态的图片动起来,将画面中展现的故事通过视频形式讲述出来。
在 Twitter 上我们可以看到用户分享的各种创意视频,有搞笑的让蒙娜丽莎画像动起来、用自拍照还原自拍时的场景、还有温情的“复活”重要的人让场景重现等等。可以说是 AI 创作工具加上用户丰富的想象力,赋予了作品新的生命力。
而在这个赛道上,对标一直是离不开的话题。从架构来看,Dream Machine 与 Sora 同样都是使用 Diffusion Transformer 架构,关联性会更高一些;从生成内容来看,相比 Runway 和 Pika,Dream Machine 的差异化体现在动作幅度更加大,镜头切换角度更多且更快,而不是只让视频中的物体稍微动一动,不过由于目前模型还处于初级阶段,可控性问题也由此而生。例如在用户测试时就出现过,动物镜头切换时出现不符合常理的多头现象,整体来说,数据和模型还都有很多可优化的点。
再从单次生成视频时长来看,Dream Machine 可在 120 秒生成一段 5 秒视频,Runway 则更快一些,90 秒可生成 10 秒视频,最新版本中可延长至 18 秒,而 Pika 还是单次只能生成 3 秒的视频,Sora 作为鼻祖,算是已经打破了时长局限,可以生成长达 1 分钟的视频,但差不多要用 1 个小时的时间来渲染。再对比几个产品的收费定价,免费测试阶段过后,Dream Machine 的整体收费最高,而 Pika 的专业版定价是其标准版的 6 倍,其他产品都在2-3.5 倍左右。
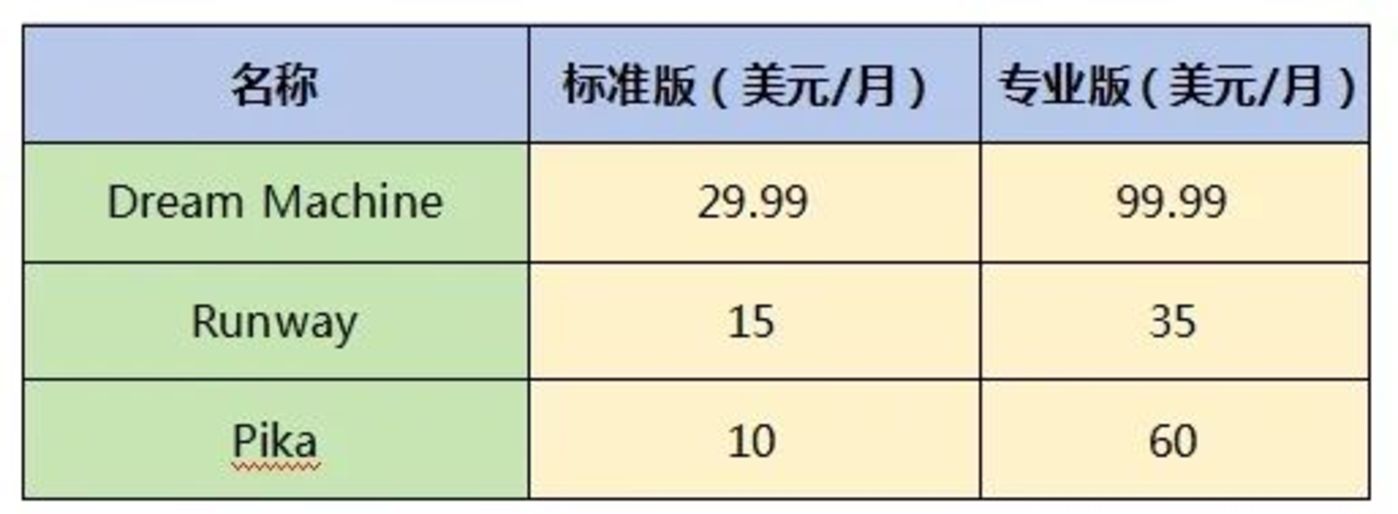
(AI 视频生成产品价格对比)
最后从视频生成效果上看,同一段文字表述,不同产品生成的视频风格各异。相比于其他产品,电影感和物理真实感是用户在使用 Dream Machine 时候的普遍感受之一,它生成的视频镜头感和可代入感更加强烈。总结可能原因有两点,一是产品在模型训练时使用了大量电影片段,这也让生成的视频充满了想象,并不局限于原画面中的事物,而是增加了一些额外的场景,还对动画人物的处理加上嘴部动作,显得更加真实;而另外一点则是与背后公司在 3D 建模方面的技术与经验积累息息相关。
文生 3D 小手办,技术积累功不可没
Luma AI 在成立之初就专注于 3D 内容生成,之前上线的一款文生 3D 模型应用 Genie1.0 曾一度爆火全球。该应用有 PC 网页版、手机 APP 版(名为 Luma AI),并还可以在海外广泛应用的 Discord 服务器上使用。
仅需输入一句文字描述,10 秒时间便可生成 4 个逼真的 3D 模型,类似于一个“小手办”,根据个人喜好选取后,还能够自行编辑质感,包括原始、光滑和反光三种。最后可以通过 fbx、gltf、obj 等多种格式输出,实现与其他 3D 编辑软件(如 Unity 和 Blender)的无缝对接,让模型能够动起来,完美契合游戏、动漫等场景,真正做到了为下游提供场景赋能。
Genie1.0 的低技术门槛也让用户通过简单的视频片段拍摄,就可以重建 3D 场景。按照要求对物体进行平视、俯视及仰视 3 个视角的 360°拍摄,上传后等待几分钟,Genie1.0 便可完成对视频的 3D 渲染。
技术方面,Luma AI 可以说是将 NeRF(神经辐射场)发挥到了极致。传统的 NeRF 需要用专业设备拍摄出大量照片,且需要严格遵循坐标位置。如今得益于底层代码开源,越来越多的简化模型被开发,所需照片和拍摄角度要求都大幅下降,Genie1.0 则实现了更高一级的水平,成为了一个随时随地通过引导便可用的 NeRF。
3D 技术与产品的积累,帮助公司顺利的从 3D 生成转向了视频生成,但反过来看,视频生成也为 3D 创造了优质条件。在 Luma AI 的理念中,做视频生成产品其实是为了将 3D 加上时间维度更好的去做 4D,视频在这里算是充当中间的角色。
我们可以将 Genie1.0 与 Dream Machine 两个产品结合起来看,前者是可以通过多角度视频搭建 3D 模型,后者利用 3D 模型的积累去更好的生成视频。且由于 3D 相较于图片和视频来说,数据存在局限性,想要更好的创造 3D,就需要更多的大模型数据来驱动。为了达到最终的 4D 目标,从生成的视频中采集多视角数据,再利用这些数据去生成 4D 效果,一个完整的链条也就被打通了。
卷到最后出路在哪?
今年以来,AI 视频生成赛道逐渐拥挤起来,尤其是互联网大厂,无论是自研模型还是对外投资,都在这个领域做了一定布局。而随着入局者不断增多,一些问题也逐渐暴露,主要体现在生成视频的可控性和一致性上。
这两个问题发生时点主要都集中在视频角度切换时,如前文中提到的动物多头画面,以及在人像画面中,由于人的面部表情和细节特点变化很快且很难捕捉,在视频中切换人脸角度时,下一秒可能就出现了脸部变形、甚至不是同一张脸的情况,而这也是导致视频时长受限制的原因之一。生成视频的时间越长,保证一致性的难度就越高。

(生成视频中出现动物多头现象)
这一痛点问题也让很多开发者苦恼,虽然目前还没有完美的解决方案,但从他们的开发动作中可以看出,已经在往这个核心方向去发力。如腾讯 AI 实验室开发的 VideoCrafter2,就是利用低质量视频来保证画面中事物运动的一致性,商汤推出的人物生成模型 Vimi 可精准模仿人物微表情,重点瞄准人物、可控两个方面。
从受众群体来说,AI 视频生成产品目前主要还是对准C端用户,现阶段用户出于对新兴事物的可玩性与创意性去做测试,但随着产品增多,这股热潮褪去之后,更多的变现也要靠B端支撑。目前,这类产品也促使着 API 需求不断上升,赋予了下游企业更多可能性,无论是对生成视频的再加工还是直接使用,都让创作的时间和成本大大降低。
另外,近期快手联合博纳推出了国内首部 AIGC 原创短剧,也颠覆了传统影视行业的创作思路。两大新兴火热赛道的结合也让 AI 视频生成在应用场景上有了新的突破,更多可能性将被打开,虽然二者均处于发展初期,无论是技术还是产品都不太成熟,但迎着双风口,踩着两红利的“联名”势必会快速驱动着行业发展进程。
写在最后
AI 创作产品的推陈出新给人们的生活带来了无限创意和惊喜,也为制作降低了难度和成本。从目前的产品来看,无论是文生视频还是图生视频,都打造出了有趣新奇的玩法,其中个人的创意是驱动 AI 更好输出的关键因素。虽然一些技术方面的问题导致了偶尔有 bug 出现,且产品形态很大程度上依赖于模型的实际能力,但通过迭代更新,市场良性竞争以及赛道间的结合,相信模型终会被训练得越来越完美。与此同时,也期待着未来国产大模型产品在全球市场闯出属于自己的一番天地。






