
自 2024 年 GPT-4o 出现以来,业内各公司纷纷投入巨大的资源进行 TTS 大模型的研发。近几个月内,中文语音合成大模型如雨后春笋般涌现,如 chattts、seedtts、cosyvoice 等。
虽然当前语音合成大模型在中文普通话上的效果已与真人几乎无异,但面对中国纷繁复杂的方言,TTS 大模型却鲜有涉猎,训练一个统一的中文各方言语音合成大模型是一项极具挑战的任务。
行业痛点与技术瓶颈
当前,语音合成大模型技术在普通话领域已经取得了显著进展,但在方言领域的发展却十分缓慢。中国拥有数十种主要方言,每一种方言都有独特的语音特征和语法结构,这使得训练一个覆盖各种方言的 TTS 大模型变得异常复杂。
现有的 TTS 大模型大多专注于普通话,无法满足多样化的语音合成需求。此外,方言语料库的稀缺以及高质量标注数据的匮乏,也进一步增加了技术难度。
巨人网络 AI Lab 的技术创新与突破
为了解决上述难题,巨人网络 AI Lab 团队中的算法专家和语言学家共同努力,基于中国方言体系,构建了涵盖 20 种方言、超过 20 万小时的普通话和方言数据集。通过这一庞大的数据集,我们训练出了第一个支持多种普通话方言混说的 TTS 大模型 ——Bailing-TTS。Bailing-TTS 不仅能够生成高质量的普通话语音,还能够生成包括河南话、上海话、粤语等在内的多种方言语音。

ArXiv: https://arxiv.org/pdf/2408.00284
Homepage: https://giantailab.github.io/bailingtts_tech_report/index.html
论文标题:Bailing-TTS: Chinese Dialectal Speech Synthesis Towards Human-like Spontaneous Representation
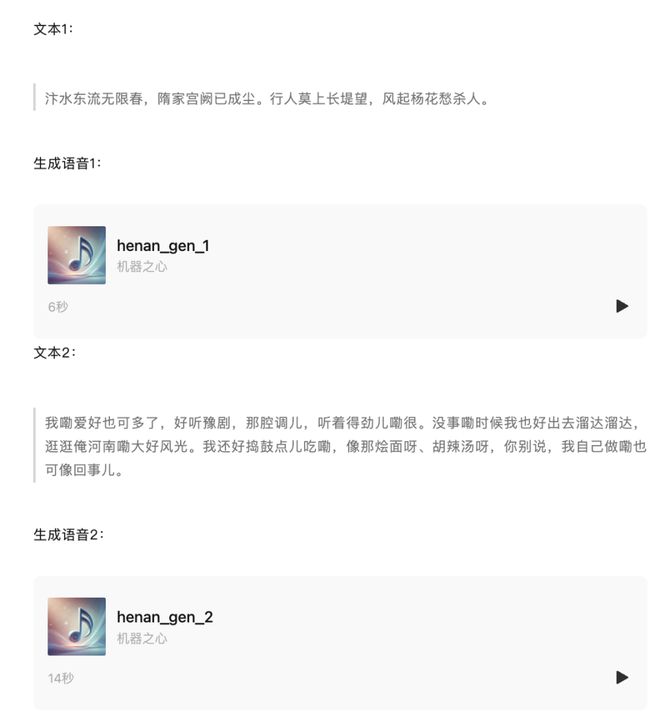
以下是 Bailing-TTS 河南话的合成效果:
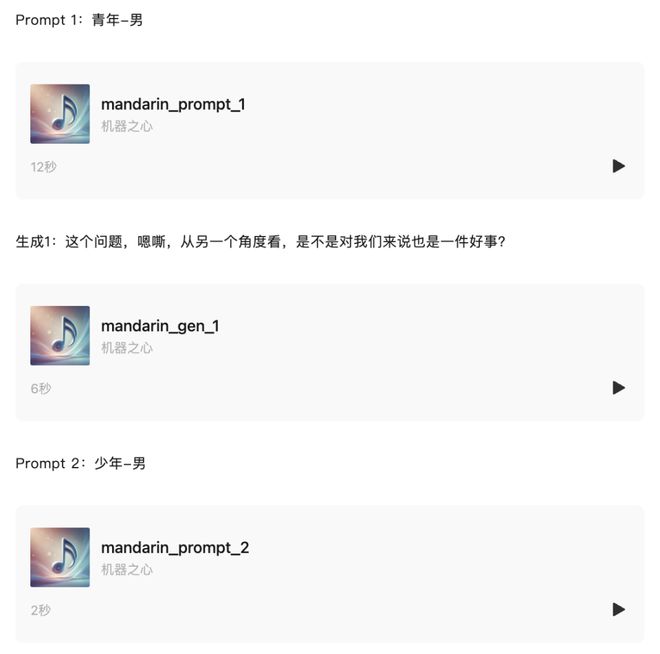
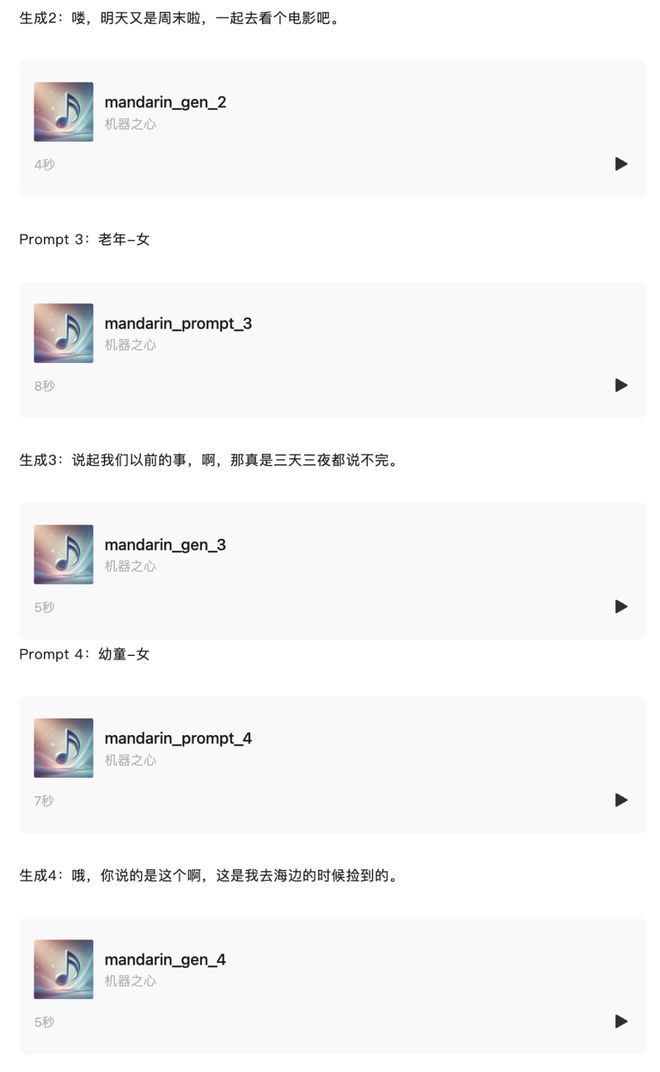
再给大家听一下普通话零样本克隆的效果:
我们采取了多项创新技术来实现这一目标:
1. 统一的方言 Token 规范:我们将各方言的 token 规范统一,并使普通话与各方言的 token 有部分重叠,以利用普通话提供基础发音能力。这使得我们能够在有限的数据条件下,实现高质量的方言语音合成。
2. 精细化 Token 对齐技术:我们提出了基于大规模多模态预训练的精细化 token-wise 对齐技术。
3. 层次混合专家结构:我们设计了一种层次混合专家体系结构,用于学习多个汉语方言的统一表示和每种方言的特定表示。
4. 层次强化学习增强策略:我们提出了层次化的强化学习策略,通过基础训练策略和高级训练策略相结合的方法,进一步增强 TTS 模型的方言表达能力。
实现细节
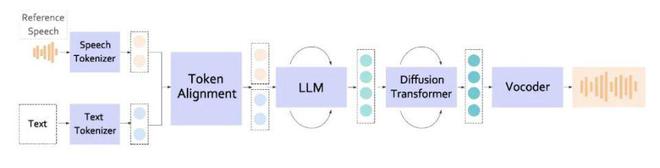
图 1 Bailing-TTS 整体架构
1. 基于大规模多模态预训练的精细化 Token 对齐
为了实现文本和语音 token 的精细化对齐,我们提出了一个多阶段、多模态的预训练学习框架。
第一阶段,我们使用无监督的采样策略,在大规模数据集上进行粗略训练。第二阶段,我们采用精细化采样策略,在高质量的方言数据集上进行细粒度训练。这一方法能够有效地捕捉文本和语音之间的细粒度关联关系,促进两种模态的对齐。
2. 基于层次混合专家 Transformer 网络结构
为了训练适用于多种汉语方言的统一 TTS 模型,我们设计了一种层次混合专家网络结构和多阶段多方言 token 学习策略。
首先,我们提出了一种专门设计的混合专家体系结构,用于学习多个汉语方言的统一表示和每种方言的特定表示。然后,我们通过基于交叉注意力的融合机制,将方言 token 注入 TTS 模型的不同层次,以提升模型的多方言表达能力。
3. 层次强化学习增强策略
我们提出了一种层次化的强化学习策略,通过采用基础策略训练和高级训练策略相结合的方法,进一步增强 TTS 模型的方言表达能力。基础训练策略支持探索优质的方言语音表达,高级训练策略在此基础上强化不同方言的语音特色,从而实现多种方言的高质量语音合成。
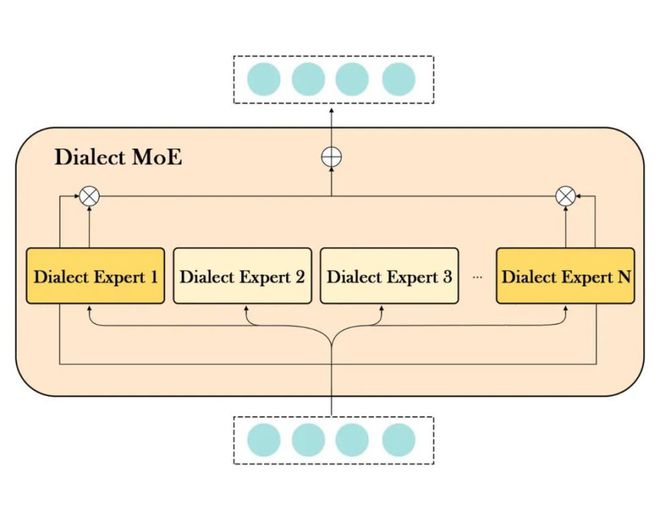
图 2 Dialect MoE 结构
实验结果
Bailing-TTS 在普通话、多种方言的鲁棒性、生成质量、自然度上已达到与真人较为接近的水平。

表 1 Bailing-TTS 在中文普通话、方言上的测试结果
在实际的应用场景测评中,Baling-TTS 均取得了不错的效果。
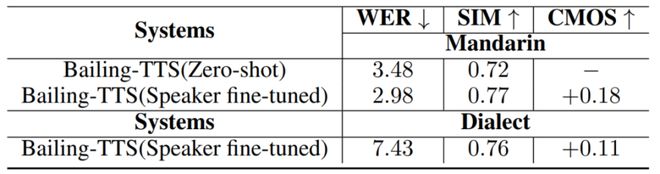
表 2 Bailing-TTS 在中文普通话、方言上的说话人微调和零样本克隆的测试结果
技术的落地应用与未来前景
目前,这项多方言 TTS 大模型已经在多个实际场景中得到应用。例如,在游戏中为 NPC 配音,视频创作中进行方言配音等。通过这一技术,游戏和视频内容能够更加贴近地域文化,提升用户的沉浸感和体验感。
未来,随着端到端语音交互大模型的进一步发展,这项技术将在方言文化保护、游戏 AI NPC 方言交互等领域展现更大的潜力。在方言保护场景中,通过支持多种方言的语音交互,可以让下一代便捷地学习、传承、守护汉语方言,让汉语方言文化源远流长。在游戏场景中,会说方言的可语音交互的智能 NPC,将进一步提升游戏内容的表现力。
巨人网络 AI Lab 将继续致力于推动这一技术的创新和应用,为用户带来更智能、更便捷的语音交互体验。
团队介绍
巨人 AI 实验室成立于 2022 年,是隶属于巨人网络的人工智能技术应用与研究机构。致力于面向 AIGC 内容(图像 / 文本 / 音视频 / 3D 模型等)生成领域,实现内容生产创作全面智能化,推动游戏玩法创新。目前,实验室已在巨人内部构建起全链路 AI 工业化生产管线,同时完成游戏行业内首个垂类大模型(GiantGPT)备案,率先投入商业化应用。






